팀: 규철(팀장), 시호, 지호, Evan — 4명
서비스명: Tokit
일정: 4월 20일 ~ 5월 1일 (NLP 프로젝트) → 이후 2주 (서비스 개발)
프로젝트 시작 전에, 팀장 규철님이 정리한 아이디어를 바탕으로 Tokit이 뭔지, 왜 이걸 만들려는지 먼저 적어두는 글이다.
무엇을 만드는가
Tokit은 LLM CLI를 위한 프롬프트 컴파일러다.
한국어로 작성된 개발자 프롬프트를 받아서, 더 짧고 명확한 영어 명령으로 변환한다. 이 과정에서 입력 토큰과 출력 토큰을 동시에 줄이는 것이 목표다.
내가 생각하는 포인트는 “번역”이 아니라 “컴파일”이라는 데 있다.
Please explain this code in detail...
의미만 옮긴다. 길이와 출력 토큰은 그대로다.
Explain this code briefly and identify the main issue.
의미 유지 + 길이 압축 + 출력 형식 제어.
번역은 의미만 옮긴다. 내가 만들고 싶은 쪽은 의미를 유지하면서 길이를 줄이고, 출력 형식까지 같이 건드리는 쪽이다.
프로젝트 목표
- 입력 토큰 감소
- 출력 토큰 감소
- 성능 유지 또는 향상
- Codex CLI / Gemini CLI와의 호환성 확보
전체 흐름
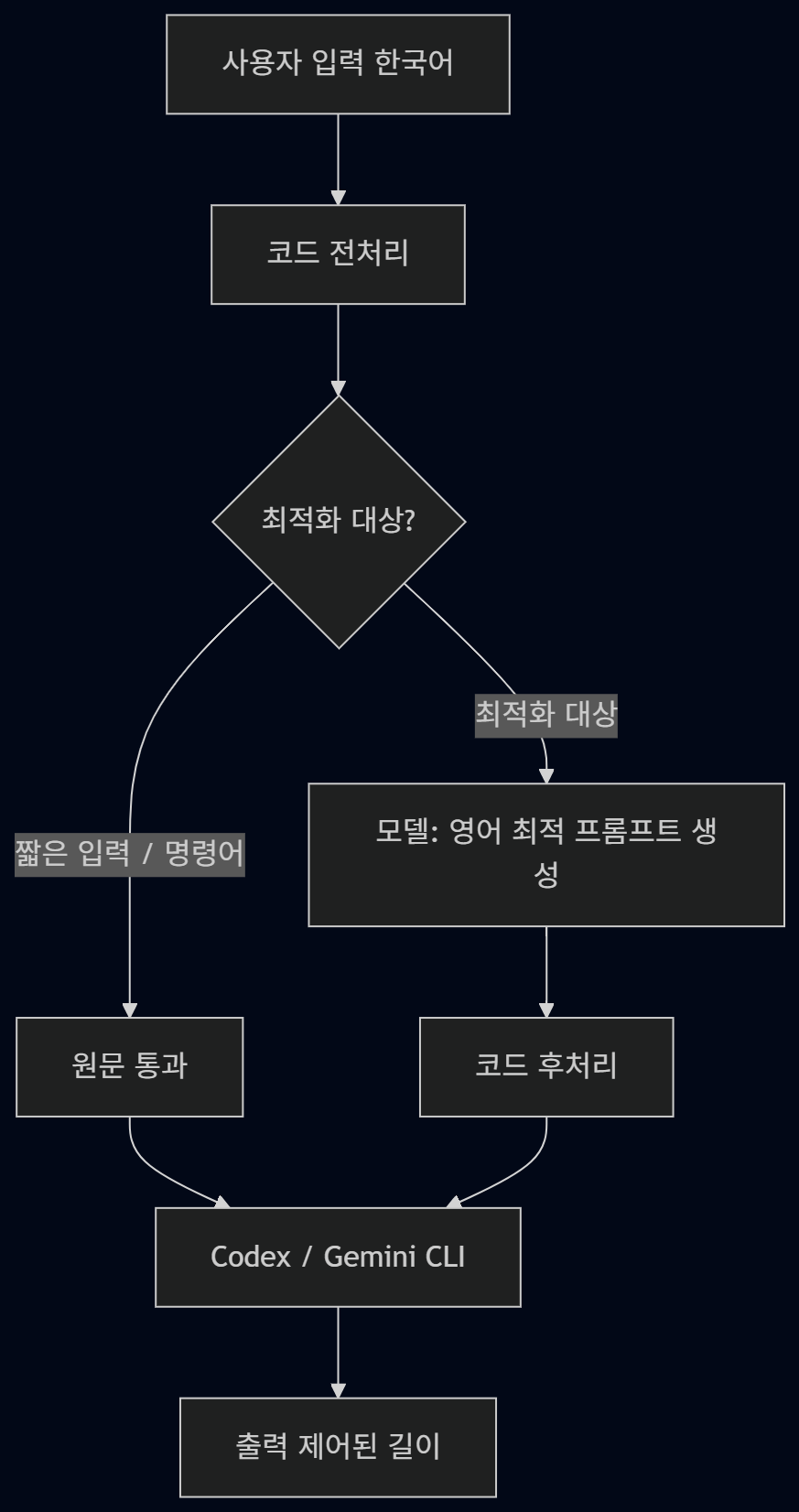
시스템은 두 레이어로 나뉜다.
코드 로직 레이어
빠르고 안전하게 처리해야 할 것들을 담당한다.
- slash command pass-through (
/,@,!) — 기존 CLI 명령어는 건드리지 않는다 - 코드블록 / 파일경로 / 에러 메시지 보호
- 짧은 입력 필터링 (최적화 대상이 아닌 경우 원문 그대로 통과)
- 토큰 계산, 캐싱, diff/log 출력
모델 레이어
입력 프롬프트에서 세 가지를 처리한다.
- 의미 파악 — 사용자의 실제 작업 의도 추출
- 영어 변환 — 항상 영어로 출력
- 프롬프트 최적화 — 명령형, 짧고 명확하게, 출력 길이 제어 포함
토큰을 어떻게 줄이는가
입력 토큰
- 군더더기 표현 제거
- 명령형으로 변환
- 중복 내용 제거
- 영어로 압축
입력 토큰은 이 방향으로 가면 비교적 안정적으로 줄일 수 있다고 보고 있다.
출력 토큰
프롬프트 안에 출력 형식을 강제하는 지시문을 추가한다.
in 3 bullet points
keep it concise
only root cause and fix출력 토큰은 작업 유형과 설계에 따라 달라진다.
작업 유형별 최적화 정책
유저 프롬프트가 어떤 작업인지 먼저 나누고, 거기에 맞춰 출력 제어 전략을 붙인다.
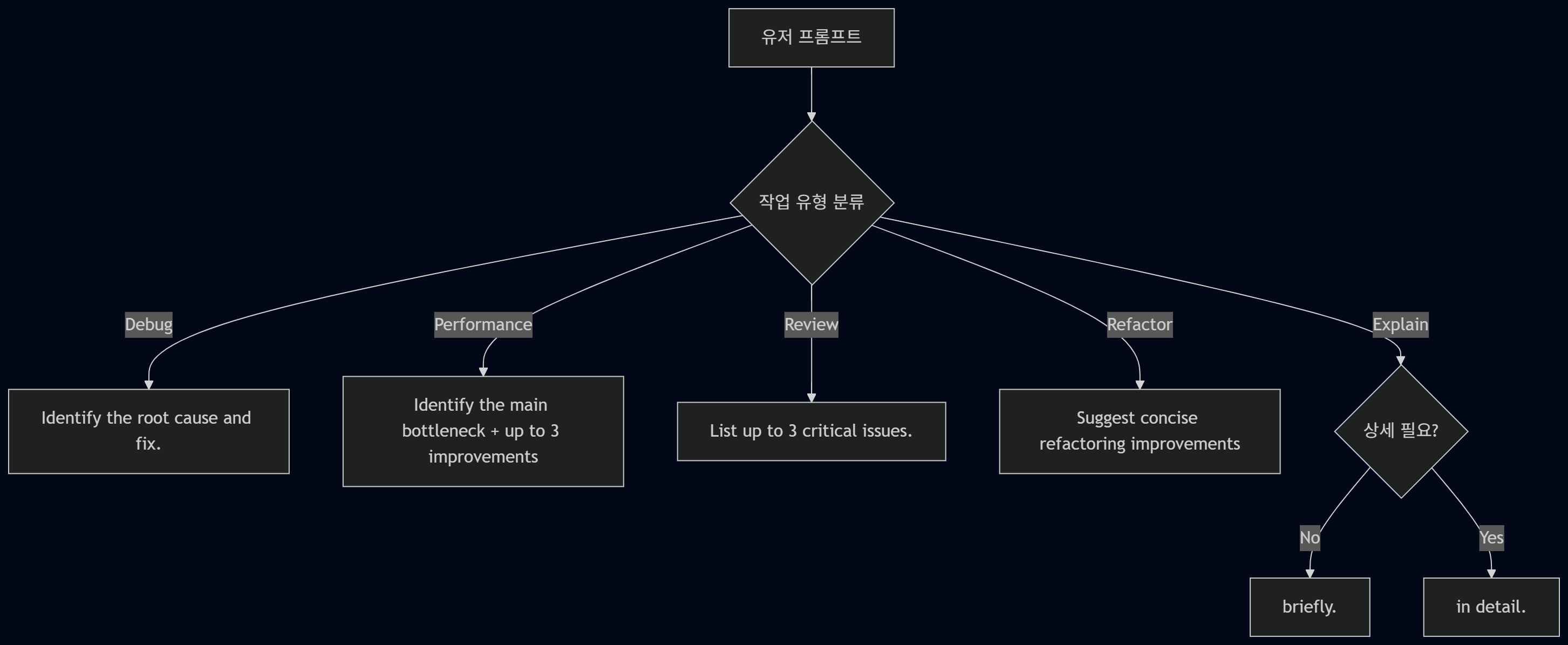
Identify the root cause and suggest a fix.
Identify the main bottleneck and suggest up to 3 improvements.
List up to 3 critical issues in this code.
Suggest concise refactoring improvements.
Explain briefly. (필요 시: Explain in detail.)
Explain만 예외적으로 길어질 수 있고, 나머지는 기본적으로 짧게 가도록 설계하려고 한다.
설계 원칙
- always-on — 모든 프롬프트를 처리한다. 필터링 조건을 만족하지 못하면 원문 그대로 통과시킨다.
- 명령어는 건드리지 않는다 —
/,@,!로 시작하는 CLI 명령어는 패스스루. - 출력은 기본값으로 짧게 — verbose 모드는 opt-in.
- 전체 비용으로 평가한다 —
최적화 모델 비용 + 메인 모델 비용이 함께 줄어드는지로 판단한다.
기존 LLM 서비스와 어떻게 다른가
OpenAI, Google 같은 서비스들은 이미 내부에서 컨텍스트 압축과 정보 필터링을 수행한다. 그렇다면 Tokit은 중복인가?
잘못 만들면 진짜 중복이 된다. 내가 계속 붙잡고 있는 기준은 모델이 이미 잘 하는 걸 또 만들지 않는 것이다.
모델만으로는 해결되지 않는 것
모델도 내부적으로 효율화를 하긴 하지만, 목표가 사용자의 총 토큰 비용 최소화에 있지는 않다
모델은 주로 현재 요청 단위로 동작하고, 세션 전체 흐름이나 반복 루프까지 직접 최적화하지는 않는다
툴 출력(logs, HTML, JSON)은 대체로 모델에 들어가기 전에 서비스 레이어에서 먼저 정제하는 편이 더 효율적이다
Tokit이 해야 할 방향
- 모델이 받기 전에 정제 — 툴 출력, 로그 압축, HTML → 구조화 데이터 변환
- 반복 루프 최적화 — 이전 결과 캐싱, 중복 요청 제거, diff 기반 업데이트
- 중요도 기반 필터링 — 에러 메시지는 유지, 성공 로그는 제거, stack trace는 축소
- 구조화 압축 — 자연어 대신 JSON으로 정보 전달 (토큰 감소 + 의미 보존)
내 기준
이 최적화가 모델 없이도 할 만한 일인가? YES면 Tokit에서 맡을 만하고, NO면 모델이 이미 하고 있는 것과 겹칠 가능성이 크다.
복합 요청 처리
유저가 “코드 생성, 리뷰, 테스트”처럼 여러 작업을 한 번에 던지면, 이걸 단일 카테고리로 묶는 순간 빠지는 정보가 생긴다.
{ "category": "code_generation" } // ❌ 나머지 작업이 사라짐대신 작업 그래프로 분해한다.
{
"intent": "multi_step_dev_request",
"tasks": [
{ "type": "code_generation" },
{ "type": "code_review" },
{ "type": "test_creation" }
]
}작업 간 의존 관계와 실행 순서를 그래프로 표현하면 이렇다.
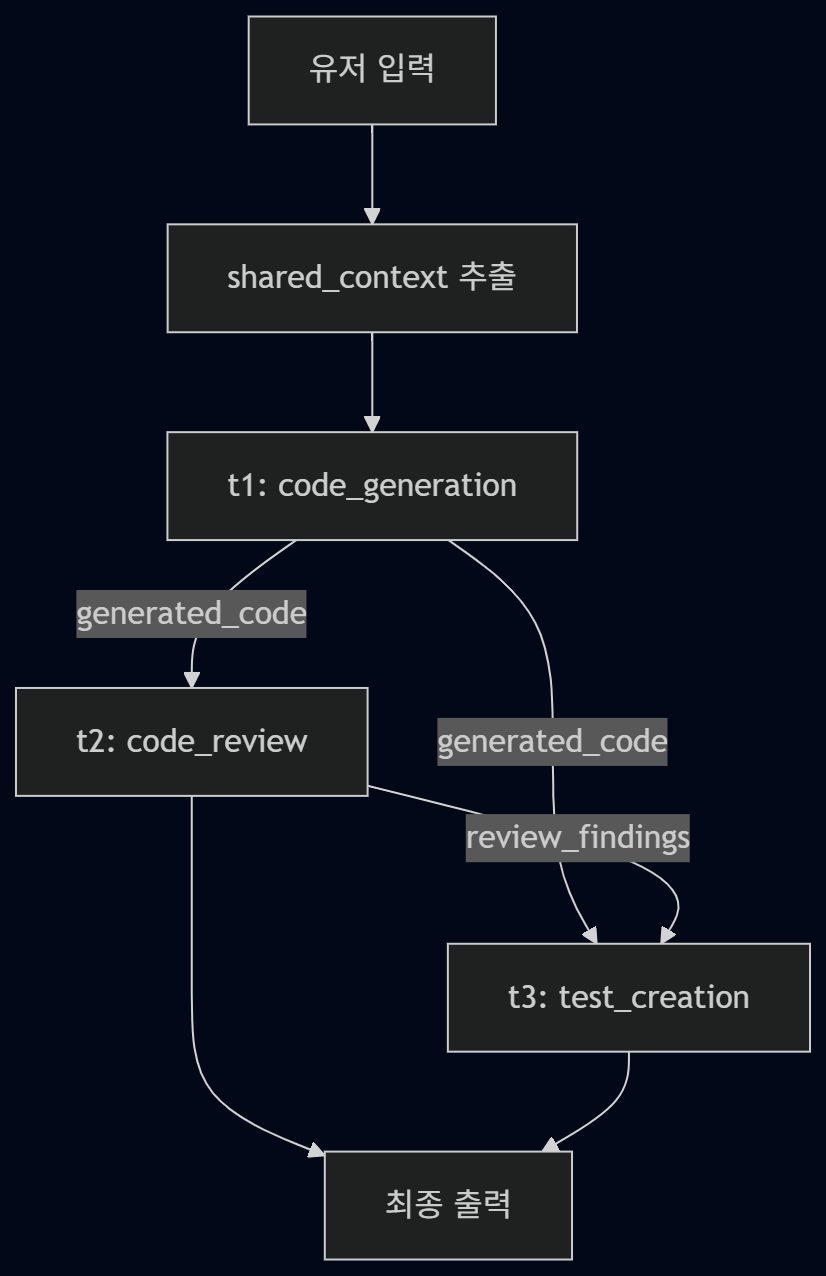
공유 컨텍스트 분리
세 작업이 같이 쓰는 정보를 매번 반복해서 넣으면 토큰만 더 든다. 그래서 shared_context로 한 번만 정의하고, 각 작업에는 차이만 담는 식이 더 낫다.
{
"shared_context": {
"language": "Node.js",
"feature": "JWT authentication middleware"
},
"tasks": [
{ "type": "code_generation", "task_context": {} },
{
"type": "code_review",
"task_context": { "focus": ["security", "maintainability"] }
},
{ "type": "test_creation", "task_context": { "framework": "jest" } }
]
}단계 간 상태 전달
각 단계마다 전체 대화를 다시 넘기면 컨텍스트가 계속 불어난다. 그래서 각 단계 결과를 상태(state)처럼 정리해두고, 다음 단계에는 필요한 것만 넘기는 쪽으로 생각하고 있다.
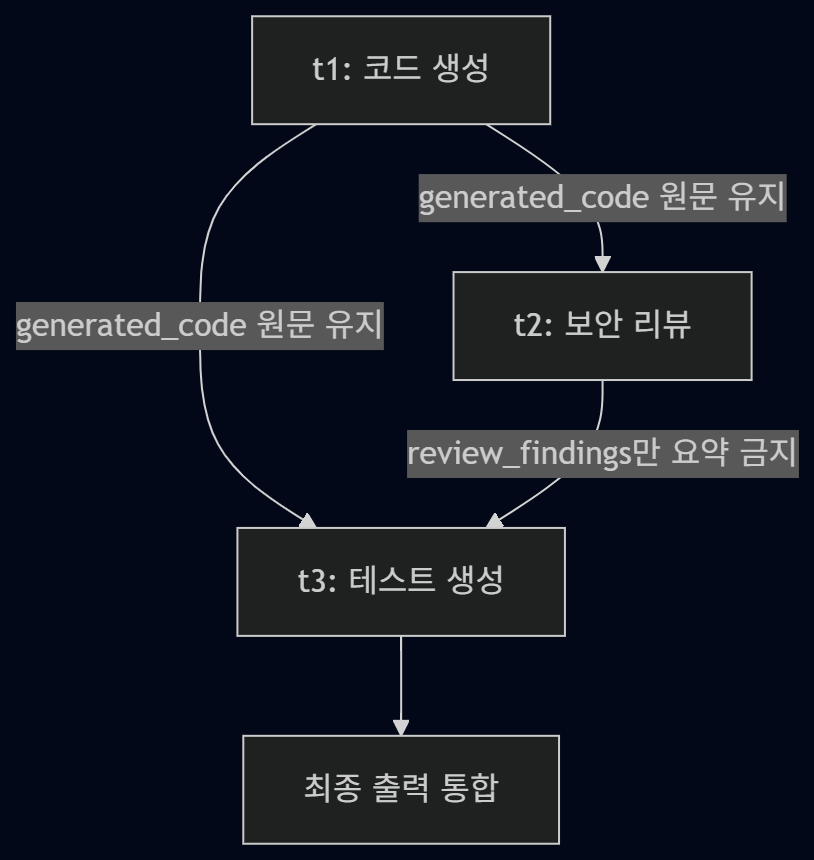
- 리뷰 단계 → 코드 + 최소 요구사항만
- 테스트 단계 → 최종 코드 구조 + 리뷰에서 발견된 위험 포인트만
압축하면 안 되는 것
여긴 안 줄인다
생성된 코드 본문, 에러 메시지 원문, 보안 리뷰에서 나온 이슈, 함수 시그니처는 절대 요약하면 안 된다. 여기서 정보가 빠지면 다음 단계가 바로 흔들린다.
생성된 코드 본문
에러 메시지 원문
보안 리뷰 발견 이슈
함수 시그니처 / 인터페이스
반복된 배경 설명
해결된 이전 논의
중요도 낮은 코멘트
성공 로그, 중복 설명
어떻게 검증하고 무엇부터 만들까
여기까지는 Tokit이 뭔지, 왜 이런 방향으로 가려는지 정리한 단계다. 그런데 이제부터는 무엇을 만들지 보다 무엇을 어떻게 검증할지 를 먼저 잡아야겠다는 생각이 들었다. 그냥 문장을 그럴듯하게 바꾸는 수준이면 금방 한계가 올 테고, 내가 진짜 보고 싶은 건 토큰이 얼마나 줄었는지, 응답 시간이 실제로 나아졌는지 같은 숫자다.
1. 먼저 낭비 구간을 찾아야 한다
프롬프트를 바로 손보기보다 먼저 실제 요청을 보면서
- 어떤 요청이 반복되는지
- 어디에서 중복 설명이 많이 들어가는지
- logs / HTML / JSON 같은 raw output에서 토큰이 크게 쓰이는지
를 봐야 한다. 내가 만들고 싶은 건 “문장을 예쁘게 바꾸는 도구”가 아니라 토큰이 많이 새는 구간을 찾아서 줄이는 도구 에 더 가깝다.
2. 최적화 전략은 3~5개로 좁혀야 한다
MVP에서는 가능한 걸 다 넣기보다 아래 같은 후보 중에서 우선순위를 정하는 쪽이 맞다.
- 중복 제거
- logs / HTML / JSON 정제
- 히스토리 요약
- 중요 정보만 유지
- 캐싱 / diff 기반 전달
여기서 중요한 건 전략을 많이 적는 게 아니라, 3~5개 정도로 좁혀서 실제로 비교해볼 수 있게 만드는 것 이다.
3. 좋아 보이는 프롬프트보다 측정 지표가 중요하다
결국 봐야 하는 건 이런 것들이다.
- 입력 토큰이 줄었는가
- 출력 토큰이 줄었는가
- 응답 지연이 유지되거나 줄었는가
- 사용자가 체감하는 품질이 유지되는가
영어 프롬프트가 더 그럴듯해 보인다고 끝이 아니다. 나한테 중요한 건 총 비용과 응답 시간, 결과 품질이 같이 나아지는지 다.
4. MVP는 정제와 반복 제거가 우선이다
첫 버전은 이 순서로 가는 게 맞겠다고 보고 있다.
- logs / raw output 정제 모델에 들어가기 전에 불필요한 데이터를 줄이고 구조화하기
- 반복 작업 캐싱 같은 요청이나 같은 context에서 중복 호출 줄이기
- diff 기반 context 전달 전체를 다시 보내지 않고 바뀐 부분만 전달하기
- 중요도 기반 필터 에러, stack trace, critical finding 같은 핵심 정보만 유지하기
이 순서로 가려는 이유도 분명하다. 모델이 이미 어느 정도 해주는 일을 또 만드는 것보다, 모델 바깥에서 미리 줄일 수 있는 비용을 먼저 줄이는 쪽이 더 현실적 이기 때문이다. 그래서 Tokit은 replace라기보다 augment 쪽에 가깝다.
5. 이 글에서 다음 단계로 넘어가려면
지금 이 글에서는 “Tokit이 뭔지”까지는 충분히 적어둔 것 같다. 이제 다음 단계에서는 무엇부터 만들지, 뭘 기준으로 잘 됐다고 볼지 를 더 분명하게 가져가야 한다. 그래야 나중에 서비스화할 때도 그냥 “그럴듯한 번역기”가 아니라, 실제로 비용과 흐름을 줄여주는 쪽으로 이어질 수 있다.
Base System Prompt
지금은 이 시스템 프롬프트를 MVP 시작점으로 잡고 있다.
You are a prompt compiler for developer-focused LLM workflows.
Convert a Korean developer prompt into a compact, precise English prompt for a coding LLM.
Rules:
- Preserve the core task, constraints, and requested output format.
- Always output English.
- Use concise, command-oriented phrasing.
- Remove redundant or polite wording.
- Keep technical terms, code symbols, file names, paths, commands, and error messages unchanged when possible.
- Minimize likely input and output token usage without losing important meaning.
- Output only the final optimized English prompt.기대하는 변화와 걱정되는 점
걱정되는 점
의미 손실(압축 중 조건 누락), 지연 증가(매 프롬프트마다 모델 추가 호출), 짧은 입력에서 오히려 손해. 이 셋은 결국 fallback + 캐싱 + 입력 길이 필터링으로 막아봐야 한다.
그래서 이렇게 보려 한다:
- 짧은 입력은 필터링해서 원문 통과 (fallback)
- 캐싱으로 반복 호출 최소화
- 빠르고 가벼운 모델 사용
일정
NLP 프로젝트 — 프롬프트 컴파일러 구현
서비스 프로젝트 — Tokit 서비스화
한 줄 요약
Tokit이 만드는 것
개발자가 한국어로 프롬프트를 입력하면, Tokit이 그것을 더 짧고 명확한 영어 명령으로 컴파일해서 Codex / Gemini CLI에 넘긴다. 번역이 아니라 압축이다. 입력 토큰과 출력 토큰을 동시에 줄이는 것이 목표다.
지금 기준으로는 크게 세 덩어리로 나뉜다.
1. 프롬프트 컴파일러 — 한국어 입력을 받아 작업 유형(Debug / Review / Explain 등)을 분류하고, 각 유형에 맞는 짧은 영어 명령으로 재작성한다. 출력 형식 제어(in 3 bullet points, only root cause and fix)도 프롬프트 안에 포함시킨다.
2. 입력 전처리 레이어 — /, @, ! 명령어는 건드리지 않고, 짧은 입력은 원문 그대로 통과시킨다. 툴 출력(logs, JSON, HTML)은 모델에 넘기기 전에 정제한다.
3. 반복 루프 최적화 — 복합 요청(코드 생성 → 리뷰 → 테스트)을 작업 그래프로 분해하고, 각 단계에는 전체 대화 대신 필요한 상태(state)만 전달해 컨텍스트가 눈덩이처럼 커지는 걸 막는다.
지금 내가 생각하는 Tokit은 이 세 가지가 합쳐진 형태다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.