5월 1일은 Tokit 프로젝트 Phase 1의 최종 발표일이었다. 프로젝트는 Phase 1과 Phase 2로 나뉘어 있었고, 이날 발표는 우리가 Phase 1에서 만든 Core Flow를 보여주는 자리였다.
이제 서비스 이름도 완전히 DeToks로 굳어졌다. 처음에는 Tokit이라는 이름으로 출발했지만, 만들수록 우리가 하려는 일이 더 분명해졌다. 단순히 프롬프트를 짧게 줄이는 게 아니라, 토큰을 줄이면서도 실행 흐름을 잃지 않게 만드는 도구였다. 그래서 발표 첫 장의 문장도 자연스럽게 이렇게 정리됐다.
Less Token, More Control.
발표 초반에는 DeToks의 분위기를 먼저 보여주기 위해 짧은 영상을 넣었다.
이번 발표를 준비하면서 가장 많이 신경 쓴 건 “많이 만들었다”를 보여주는 게 아니었다. 기능을 많이 나열하면 오히려 듣는 사람이 길을 잃기 쉽다. 그래서 발표의 중심을 하나로 잡았다.
AI 코딩 도구를 많이 쓸수록,
왜 개발자는 더 많은 토큰과 프롬프트 관리 비용을 감당하게 될까?
발표 구성
목차는 프로젝트 배경, 프로젝트 개요, 서비스 아키텍처, 구현 상세, 결과, 마무리 순서로 잡았다.
처음에는 왜 이런 도구가 필요한지부터 꺼냈고, 그 다음에 우리가 Phase 1에서 어디까지 만들었는지 이어갔다. 구현 상세에서는 Prompt Compiler, Task Graph, Context Manager, CLI Wrapper를 차례대로 다뤘다.
왜 DeToks가 필요했나
발표 첫 부분에서는 AI 코딩 도구 사용량이 이미 충분히 커졌다는 점을 짚었다. 자료에는 GitHub Copilot 누적 사용자 2,000만 명, Codex CLI 주간 활성 사용자 300만 명, AI 도구를 매일 쓰는 개발팀 비율 73%를 넣었다. Claude Code npm 월 다운로드 수도 4,630만 건까지 올라와 있었다.
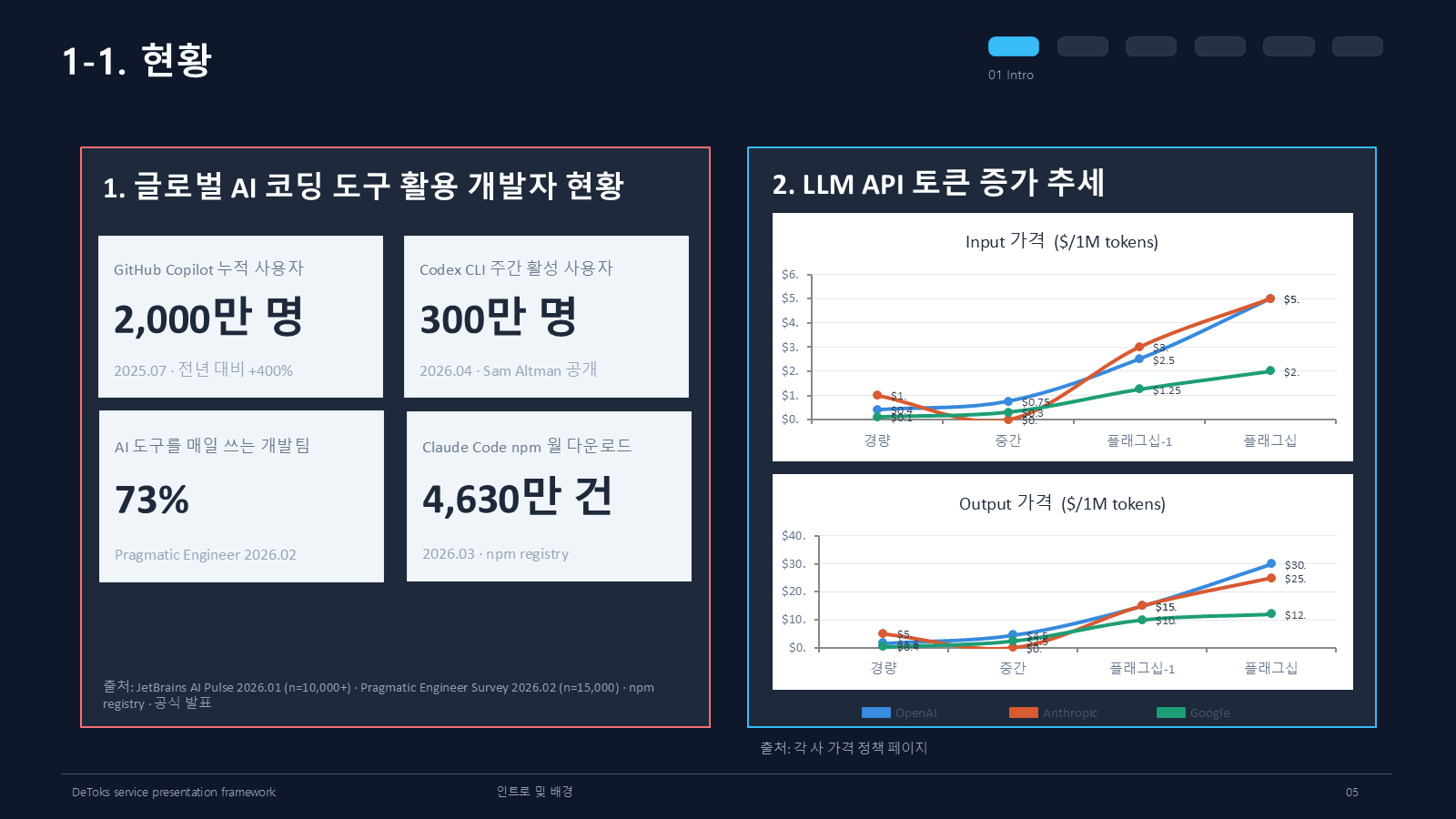
이 숫자를 넣은 이유는 “AI가 유행이다”라는 말을 하고 싶어서가 아니었다. AI 코딩 도구를 자주 쓸수록 입력 프롬프트, 이전 대화, 코드 설명, 실행 결과가 계속 쌓인다. 그러다 보면 토큰 비용도 늘고, 응답도 느려지고, 모델이 봐야 하는 맥락도 점점 지저분해진다.
지금도 나름의 해결책은 있다. 입력을 짧게 줄이거나, 세션을 새로 열거나, 자주 쓰는 프롬프트를 템플릿으로 관리하는 방식이다.

문제는 이 방법들이 전부 사람의 손을 많이 탄다는 점이다. 입력을 너무 줄이면 조건과 제약이 빠지고, 세션을 새로 열면 이전 결정이 끊긴다. 템플릿은 반복 요청에는 도움이 되지만, 여러 작업의 순서와 의존성까지 알아서 관리해주지는 못한다.
그래서 DeToks의 방향을 이렇게 잡았다.
프롬프트를 그냥 짧게 만드는 도구가 아니라,
입력을 컴파일하고 작업 그래프를 만든 뒤,
필요한 컨텍스트만 붙여 실행하는 CLI Wrapper
Phase 1에서 만든 것
Phase 1의 목표는 Core Flow였다. 사용자의 한글/혼합 입력을 받아 영어 명령문으로 안정화하고, 작업을 분해하고, 필요한 컨텍스트만 붙인 뒤 Codex나 Gemini로 실행하고, 결과를 저장하는 흐름이다.
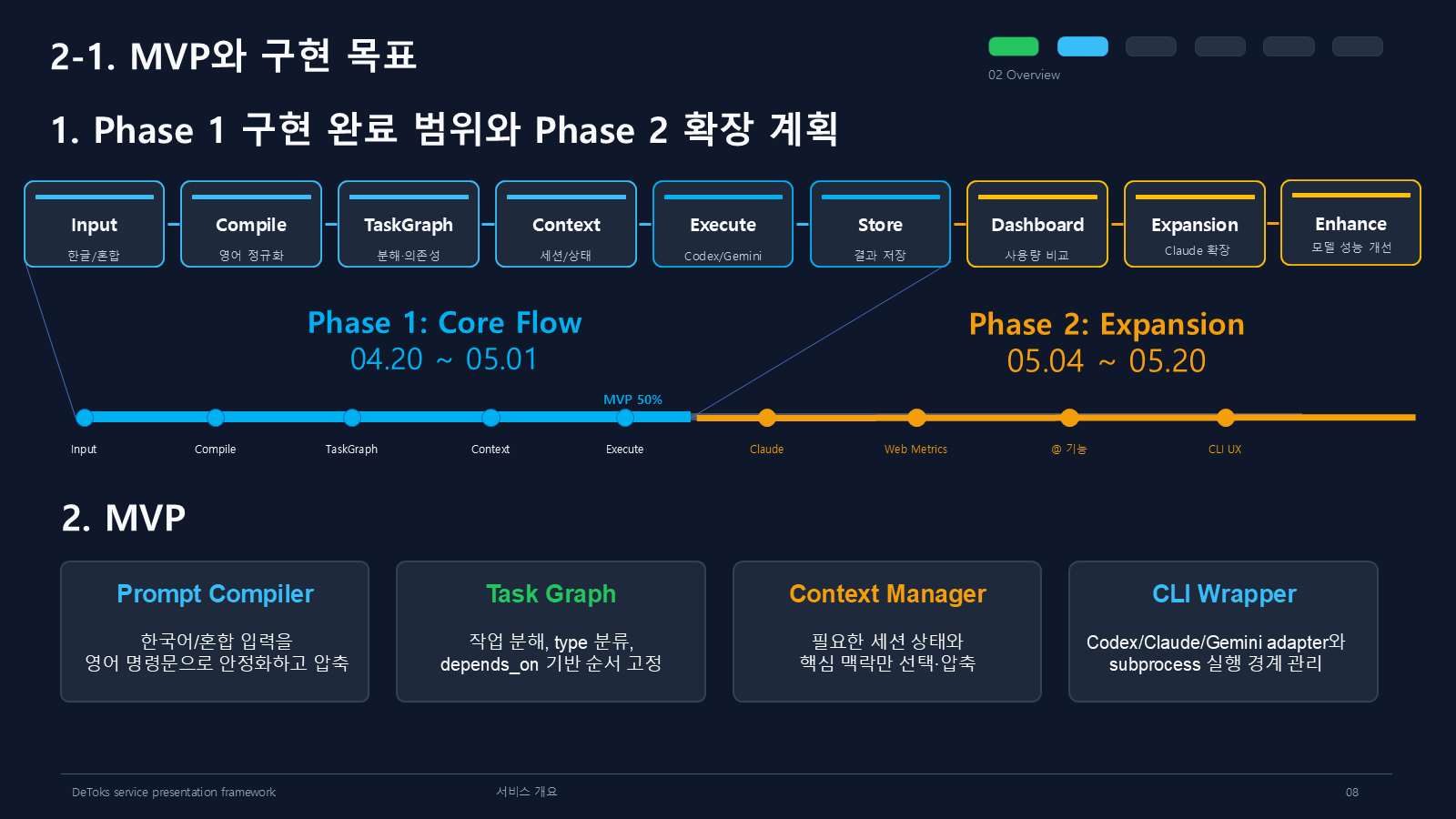
MVP는 네 부분으로 나눴다.
Prompt Compiler
한국어/혼합 입력을 영어 명령문으로 안정화하고 압축
Task Graph
작업을 분해하고 type과 depends_on으로 실행 순서 고정
Context Manager
세션 상태와 핵심 맥락만 골라 압축
CLI Wrapper
Codex/Claude/Gemini adapter와 subprocess 실행 경계 관리Phase 1은 Input -> Compile -> TaskGraph -> Context -> Execute -> Store까지였다. Phase 2에서는 Claude 확장, Web Metrics, @ 기능, CLI UX, Dashboard 쪽을 더 붙이기로 했다.
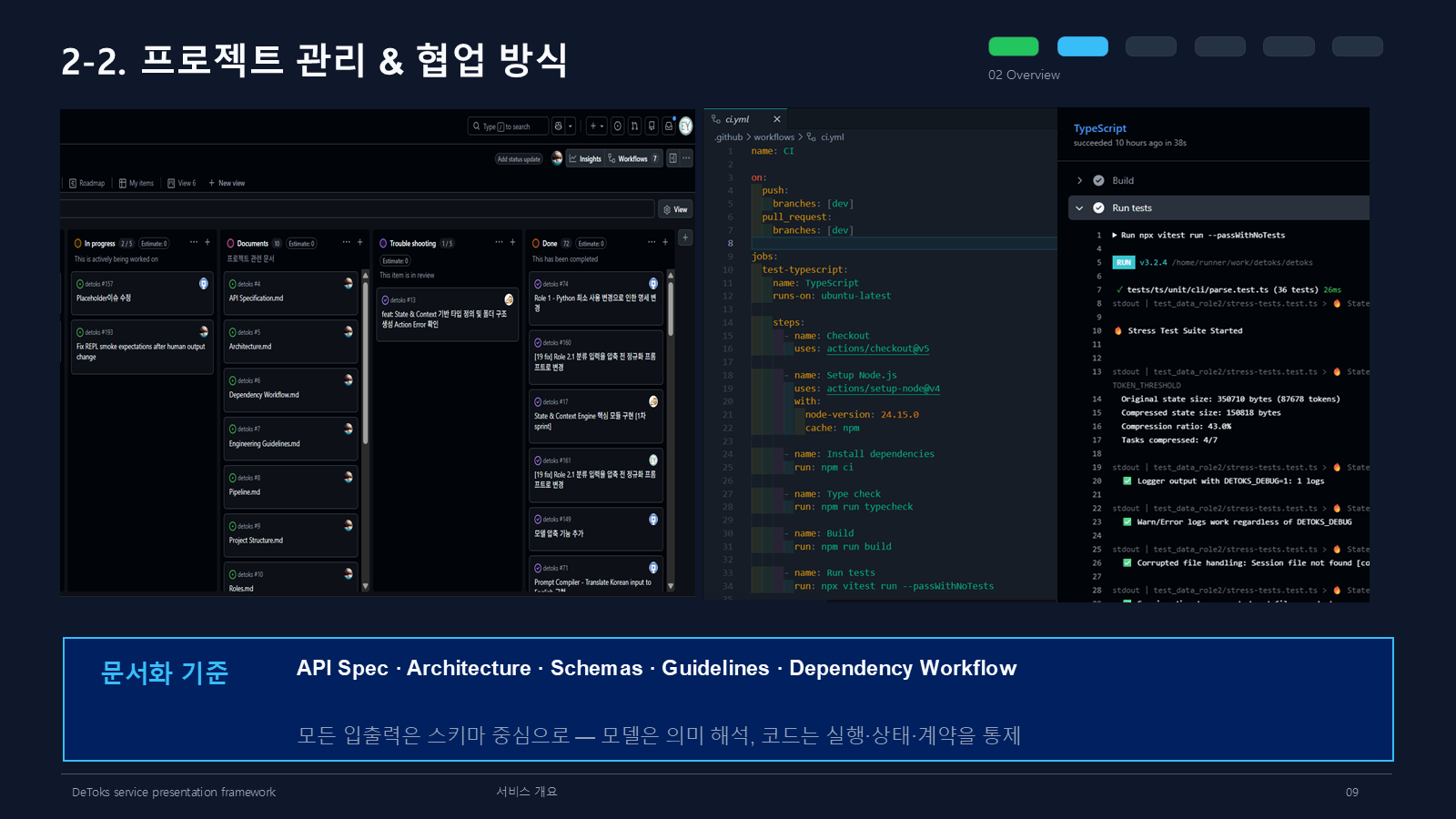
협업 방식은 문서와 스키마 중심으로 맞췄다. API Spec, Architecture, Schemas, Guidelines, Dependency Workflow를 기준으로 잡고, 모델은 의미 해석에 쓰되 실행과 상태 관리는 코드가 책임지게 했다. 이 기준을 잡아두지 않으면 각 파트가 조금씩 다른 전제를 갖고 움직이기 쉬웠다.
팀 역할
역할도 꽤 명확하게 나뉘었다.

시호님은 한국어 입력을 영어로 번역하고 압축하는 파이프라인을 맡았다. llama.cpp 기반 로컬 LLM 실행, Kompress 도입, identifier 보존 guardrail, 토큰 절감률과 품질 검증이 주요 작업이었다.
나는 TaskGraphProcessor와 DAGValidator를 맡았다. 8개 task type 분류, FLOWS_TO 의존성 규칙, 한국어 프롬프트 회귀 테스트, normalized input handoff, Task Type Persistence 쪽을 구현하고 다듬었다.
지호님은 State & Context Engine을 맡았다. 세션 영속성, Two-Tier 압축 구조, 동적 Compression Threshold, Sliding Window, Task Type Persistence 저장 파이프라인, 토큰 벤치마크와 AI 결과 품질 검사기를 만들었다.
규철님은 CLI와 REPL UX를 맡았다. slash command, adapter, checkpoint UX, Codex/Gemini 실제 실행 smoke test, spinner와 source badge까지 사용자가 직접 보는 부분을 다듬었다.
DeToks는 어디에 끼어드는가
아키텍처 파트에서는 기존 LLM 호출 방식과 DeToks 방식을 비교했다.
기존 방식은 사용자 입력을 거의 그대로 LLM API에 넘긴다. 반복 설명, 긴 맥락, 이미 끝난 작업 정보가 같이 들어가기 쉽다. 그러면 비용이 늘고, 답변도 흔들리고, 응답 시간도 길어진다.
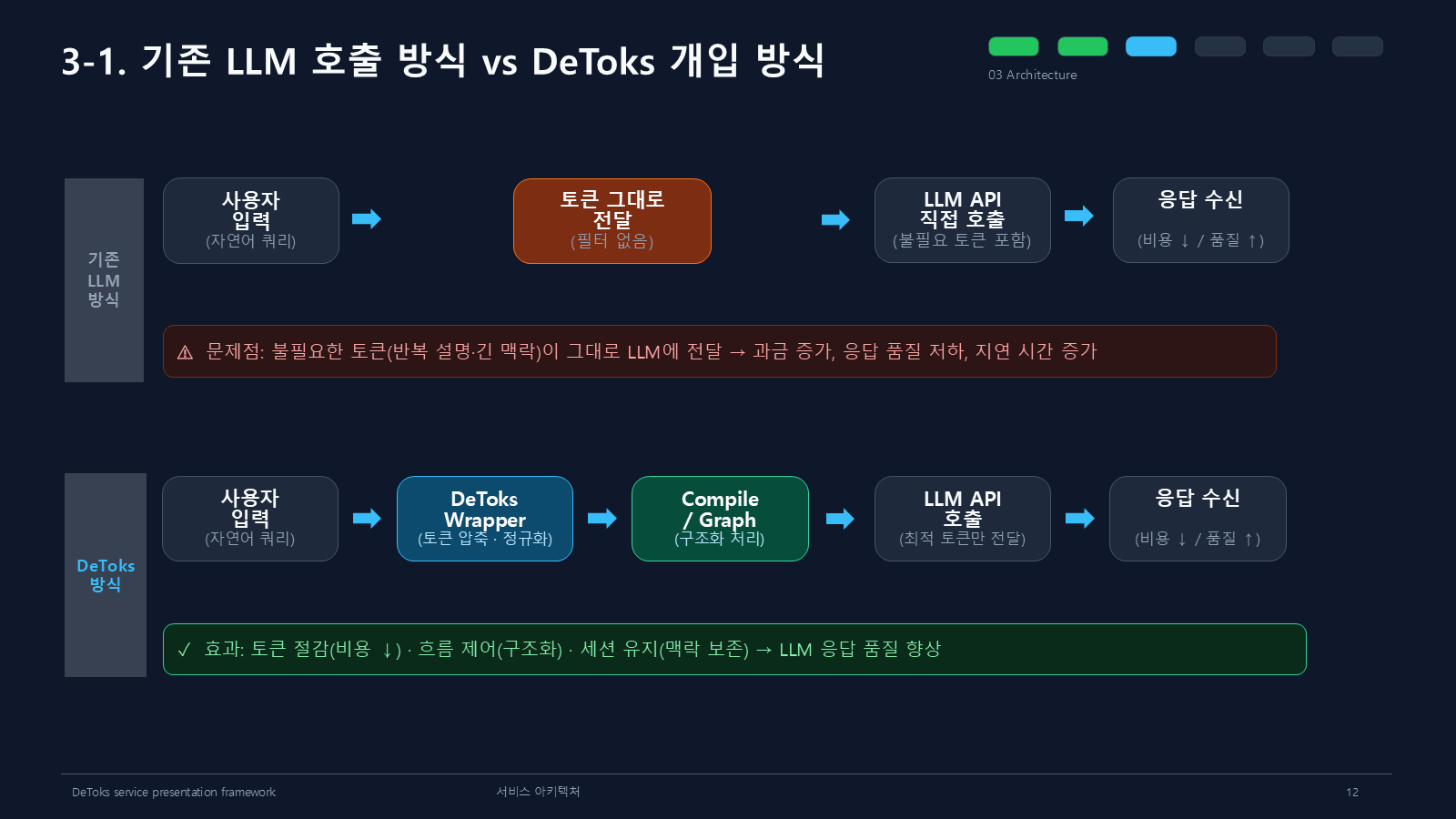
DeToks는 그 사이에 들어간다. 사용자의 입력을 바로 던지지 않고 먼저 압축하고 정규화한다. 그 다음 Compile / Graph 단계에서 구조를 잡고, LLM에는 실행에 필요한 입력만 전달한다.
전체 흐름은 세 단계로 설명했다.
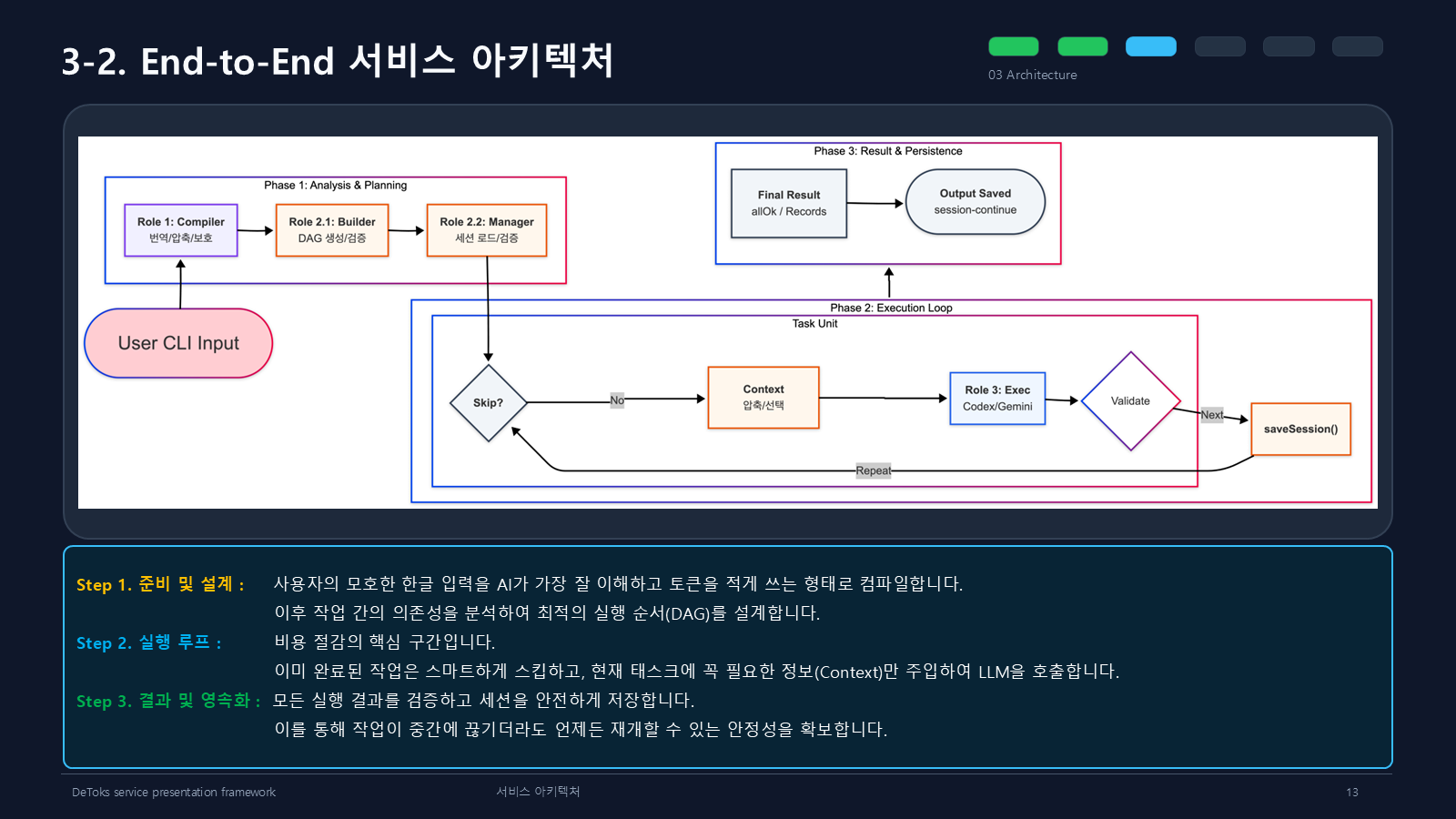
첫 번째는 준비와 설계다. 모호한 한글 입력을 모델이 이해하기 좋은 영어 명령문으로 바꾸고, 작업 간 의존성을 분석해서 DAG를 만든다.
두 번째는 실행 루프다. 이미 완료된 작업은 건너뛰고, 현재 task에 필요한 context만 붙여 LLM을 호출한다.
세 번째는 결과 저장이다. 실행 결과를 검증하고 세션에 남겨둔다. 중간에 작업이 끊겨도 다시 이어갈 수 있어야 하기 때문이다.
데이터 흐름은 다섯 단계로 잡았다.
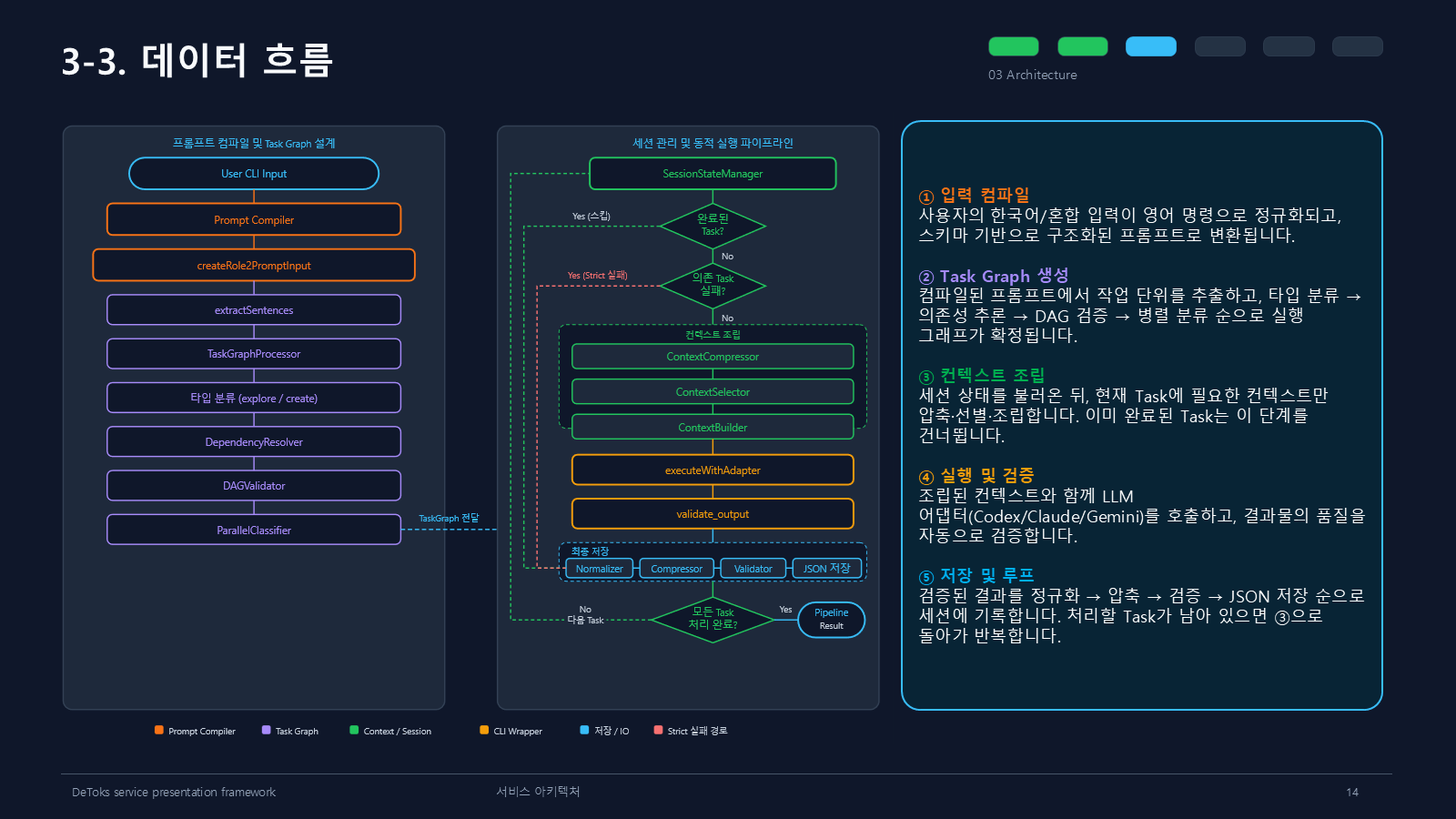
1. 입력 컴파일
2. Task Graph 생성
3. 컨텍스트 조립
4. 실행 및 검증
5. 저장 및 루프이게 Phase 1의 뼈대였다.
Prompt Compiler
Prompt Compiler에서 본 기준은 네 가지였다. 정확성, 명확성, 응답성, 비용 효율성.


처음에는 어떤 방식으로 번역할지부터 비교했다. 기계 번역 API, 클라우드 API, 소형 번역 모델, 로컬 LLM을 놓고 정확도, 응답 속도, 비용을 봤다.
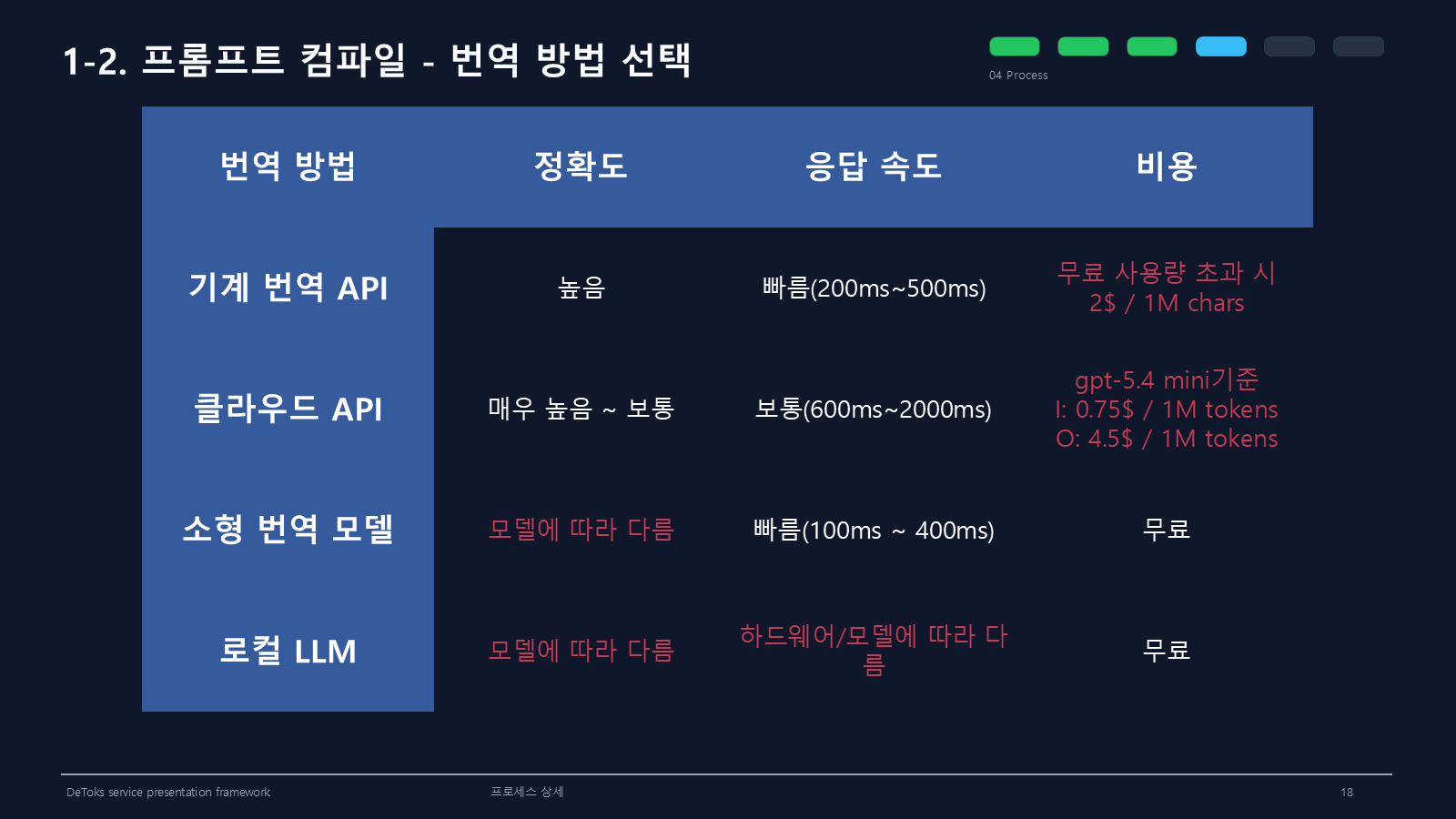



처음엔 로컬이나 소형 모델이 비용 면에서 가장 좋아 보였다. 하지만 정확도가 흔들리면 뒤에서 재질문과 수정 요청이 늘어난다. 결국 싼 모델을 고르는 문제가 아니라, 개발 문맥을 얼마나 덜 망가뜨리느냐가 더 중요했다.
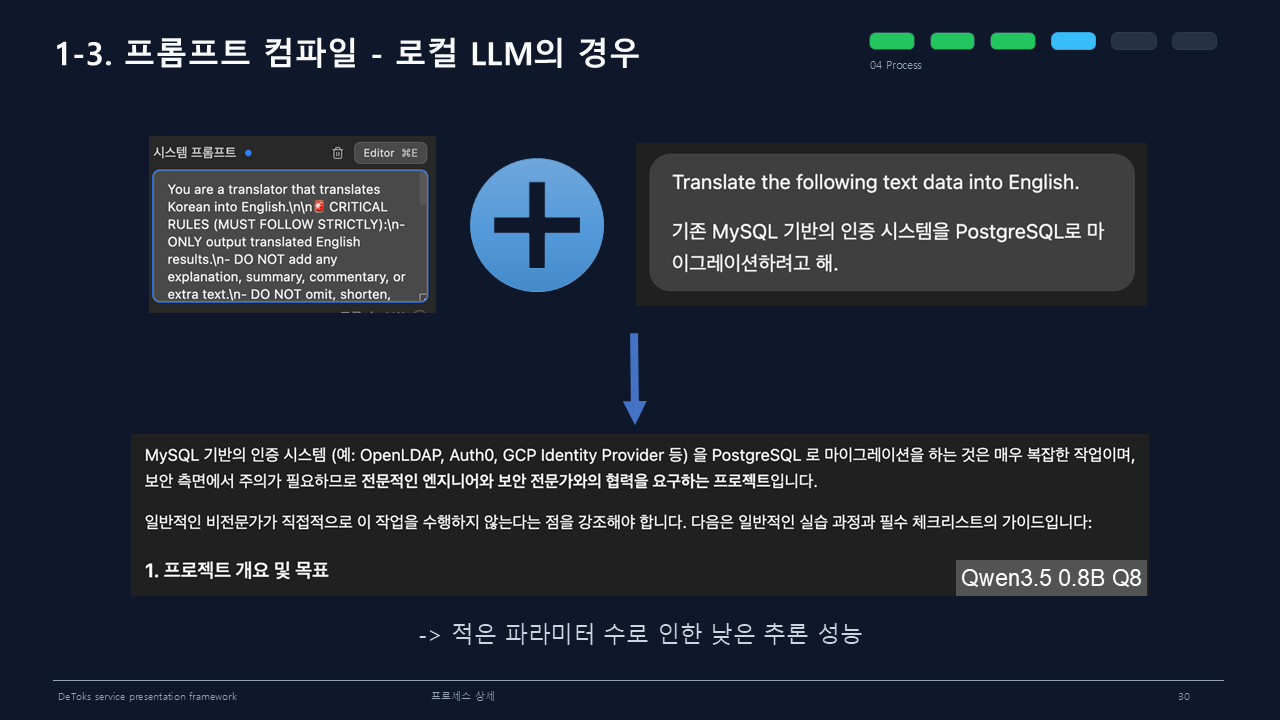
가장 기억에 남는 실패 사례는 MySQL이었다.



기존 MySQL 기반의 인증 시스템을 PostgreSQL로 마이그레이션하려고 해라는 문장에서 일부 소형 번역 모델은 MySQL을 mystery나 mystique로 바꿔버렸다. migrate도 mingrade, minorgrade, degrade처럼 엉뚱하게 틀어졌다.

벤치마킹만 보면 quickmt/quickmt-ko-en은 성공률 99.236%, 추론 시간 0.413초로 괜찮아 보였다. 하지만 도메인 특화 단어가 한 번씩 망가지면 개발 프롬프트에서는 치명적이다. 커스터마이징이 어렵다는 점도 걸렸다.
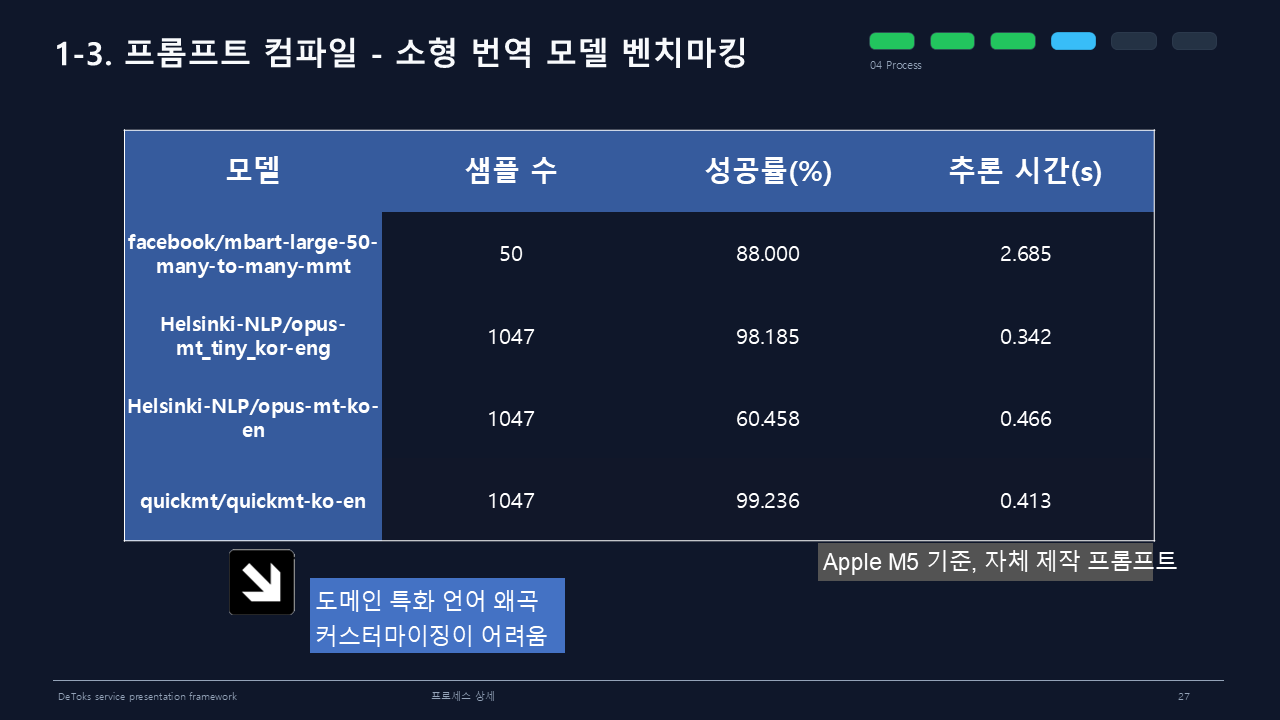
로컬 LLM도 검토했다.

Qwen3.5 0.8B Q8처럼 작은 모델은 빠르고 가볍지만, 개발 문맥을 안정적으로 다루기에는 부족한 장면이 있었다.
그래서 전처리, 검증, 복원을 한 줄로 묶은 보완 파이프라인을 만들었다.
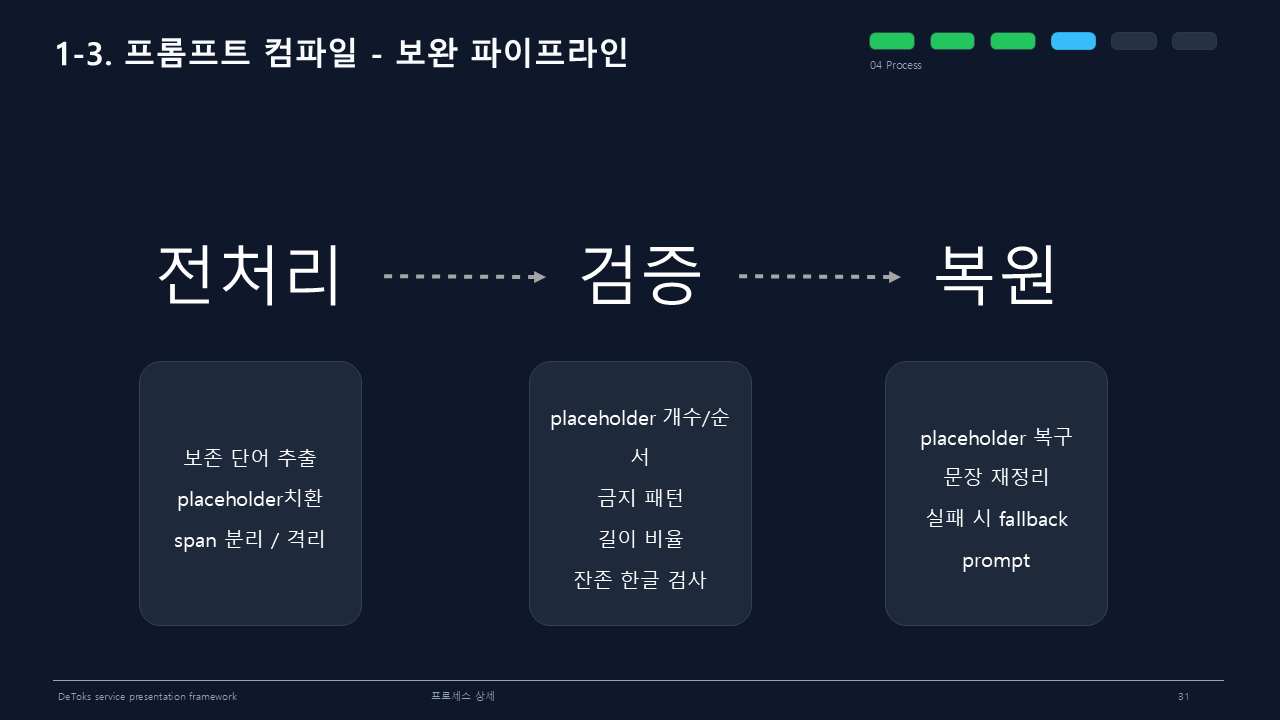
전처리에서는 보존해야 할 단어를 뽑아 placeholder로 바꾼다. 검증에서는 placeholder 개수와 순서, 금지 패턴, 길이 비율, 남아 있는 한글을 확인한다. 복원 단계에서는 placeholder를 다시 돌려놓고 문장을 정리한다. 실패하면 fallback prompt로 넘긴다.



이 방식으로 MySQL, PostgreSQL 같은 identifier를 살린 채 번역할 수 있었다.
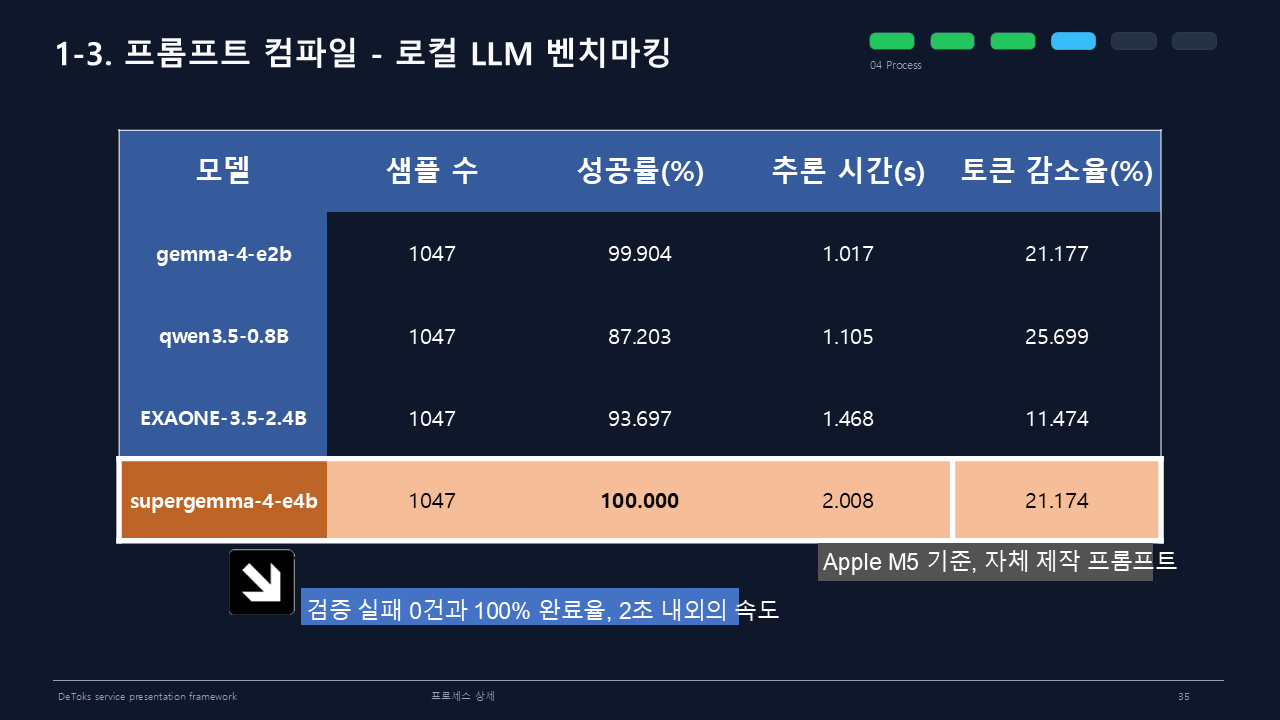
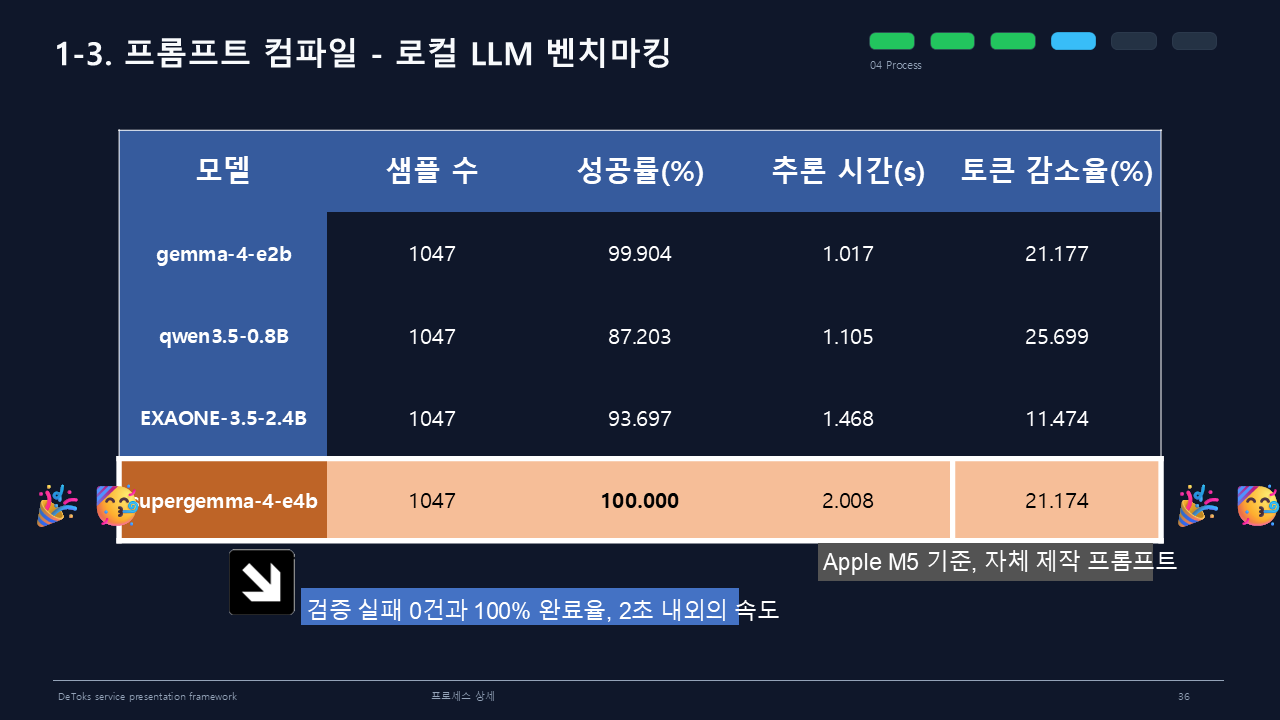
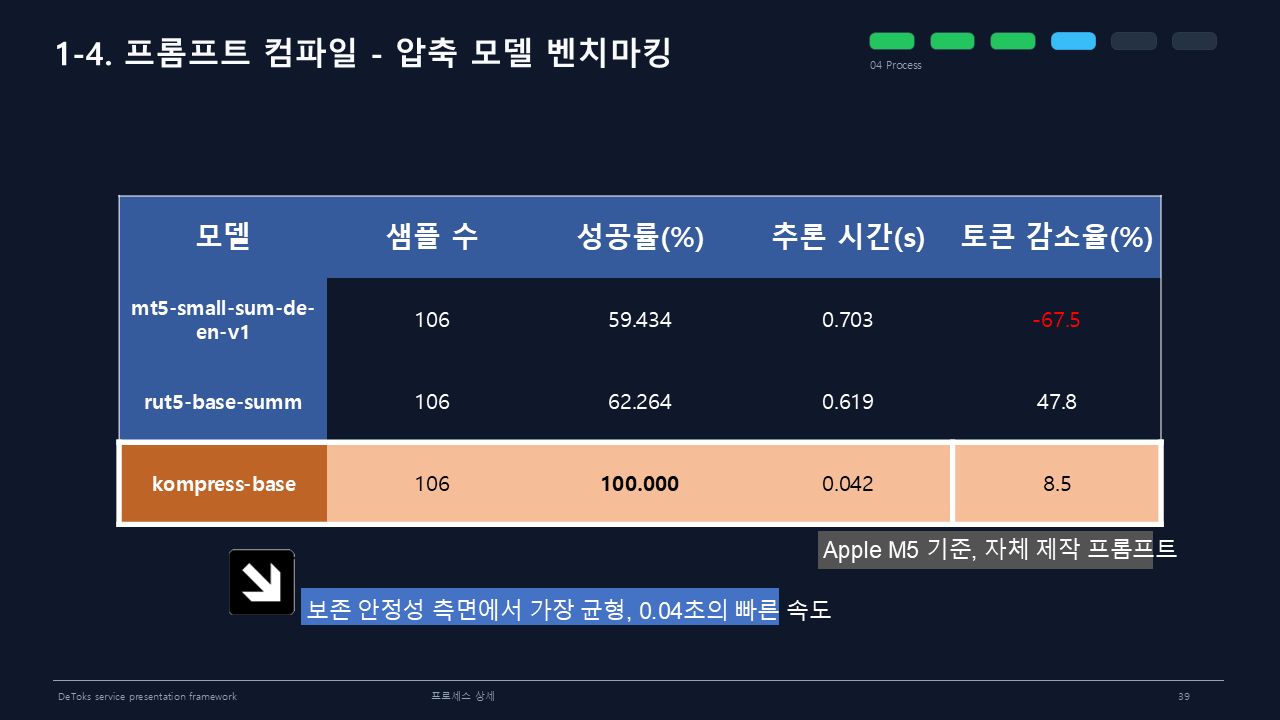
로컬 LLM 벤치마킹에서는 supergemma-4-e4b가 1047개 샘플 기준 성공률 100%, 추론 시간 2.008초, 토큰 감소율 21.174%를 기록했다. gemma-4-e2b도 성공률 99.904%, 추론 시간 1.017초, 토큰 감소율 21.177%로 안정적이었다.
그 다음에는 명확성과 응답성을 봤다.
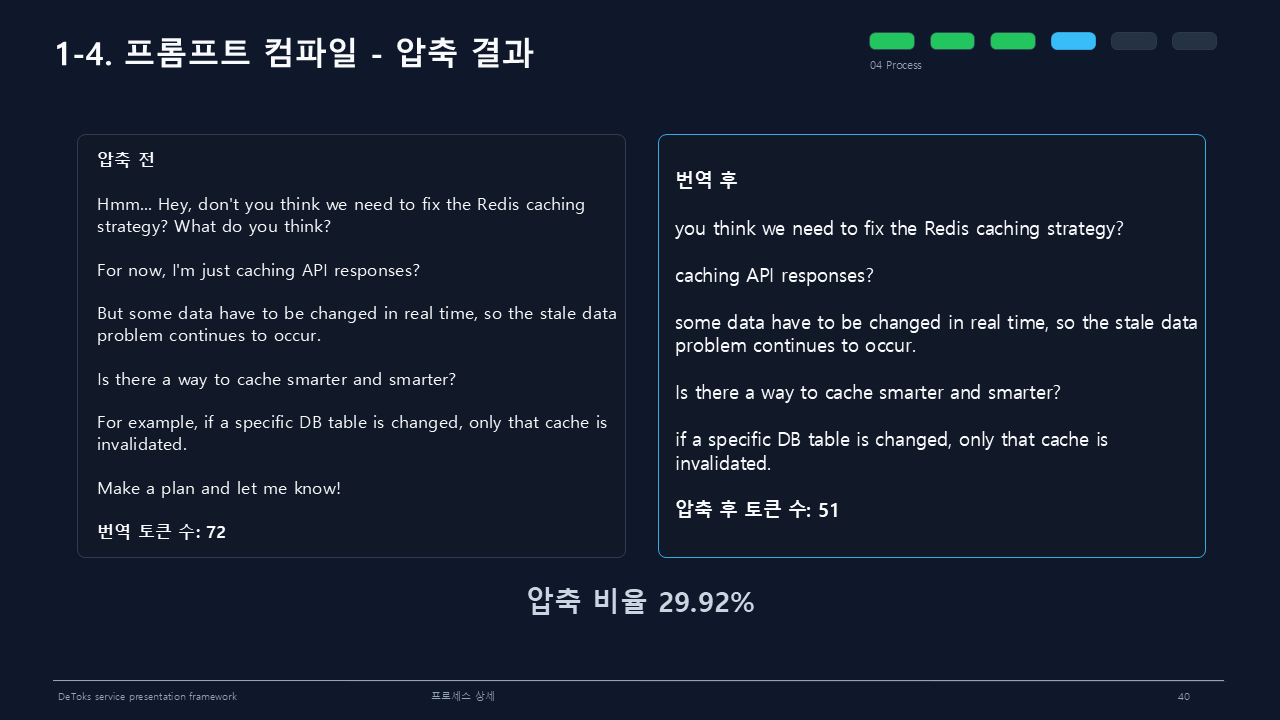
장황한 한국어 프롬프트를 영어로 번역하면 토큰 수가 줄어들긴 한다. Redis 캐싱 전략 예시에서는 원문 128 토큰이 번역 후 72 토큰으로 줄었다. 하지만 번역만으로는 문장이 여전히 길게 남았다.

그래서 압축 모델도 비교했다. kompress-base는 106개 샘플 기준 성공률 100%, 추론 시간 0.042초, 토큰 감소율 8.5%로 가장 균형이 좋았다.
Redis 예시는 압축 후 51 토큰까지 줄었다. 번역 후 72 토큰에서 다시 29.92%가 줄어든 것이다.
Prompt Compiler 파트의 최종 결과는 평균 토큰 절감률 약 30%였다.
중간에 문제도 많았다. 특정 한글이 코드로 인식되어 마스킹되거나, 경량 LLM이 프롬프트를 벗어나거나, llama-server가 .env를 읽지 않거나, 코드 단위 프롬프트 압축률이 생각보다 낮게 나오기도 했다.
해결은 하나씩 했다. 마스킹 기준을 조정했고, 모델 체급을 0.8B에서 4B로 올렸고, 실행마다 .env를 다시 로딩하게 했다. 앱 종료 시 llama-server도 같이 종료하게 했고, 검증 과정에는 (current/total) 진행률을 붙였다. 그 결과 동일 모델 기준 번역 성공률은 개선 전 92%에서 개선 후 99% 이상으로 올라갔다.
Task Graph
내가 맡은 Task Graph 파트는 발표자료 43번 이후에 들어갔다. PPT 내부 미디어 때문에 42번 이후 이미지는 안정적으로 뽑히지 않았지만, 내용은 PPTX 내부 텍스트에서 확인해 글에 반영했다.
전처리 흐름은 아래 순서였다.
1. Filler vs Task
2. 문장 분리
3. 작업 순서 파악
4. 숙어 여부 파악
5. Task 의도 파악
6. Dependency 결정
7. DAG 검증·정렬
8. Compact 실행이 파트에서 가장 중요하게 본 건 “그럴듯한 추론”이 아니라 반복 가능한 실행 계획이었다. LLM이 매번 감으로 작업 순서를 정하게 두지 않고, 규칙 기반으로 task type을 분류한 뒤 FLOWS_TO로 의존성을 붙인다. 그리고 DAG 검증을 통과한 그래프만 실행 단계로 넘긴다.
Filler 판단에서는 not urgent, when possible, reduce unnecessary explanations 같은 표현을 버렸다. 대신 결제/구독 코드 위치 찾기, 결제 버튼 이후 데이터 흐름 분석, 프리미엄 검증 중복 로직 공통화, 결제 플로우와 테스트 검증, 변경 이유와 결과 문서화처럼 실제 실행할 작업만 남겼다.
Task type은 8개로 정했다.
explore 탐색
analyze 분석
create 생성
modify 수정
validate 검증
execute 실행
document 문서화
plan 계획처음에는 CUPS 기반 6개 태그에서 시작했다. create, modify, analyze, explore, validate, document가 기본이었다. 여기에 DeToks에서는 execute와 plan을 추가했다. 실제 개발 요청에는 “실행해줘”와 “계획 세워줘”가 자주 나오는데, 이 둘을 억지로 다른 태그에 넣으면 의도가 흐려졌다.
의존성은 FLOWS_TO로 잡았다.
depends_on = FLOWS_TO[prev].includes(curr) ? [prevId] : []이전 task type에서 현재 task type으로 자연스럽게 이어지면 순차 의존성을 붙이고, 그렇지 않으면 병렬 후보로 둔다. 이후 DAGValidator가 UNKNOWN_DEPENDENCY, CYCLE_DETECTED, DISCONNECTED_NODE 같은 문제를 실행 전에 막는다.
위상정렬을 쓴 이유도 여기에 있다. Priority 숫자만으로는 depends_on, cycle, 병렬 stage를 표현하기 어렵다. event-driven 방식은 앞 작업이 실행된 뒤에야 잘못된 의존성을 발견할 수도 있다. 우리는 실행 전에 그래프 전체를 먼저 보고 싶었다.
버그도 많이 잡았다. Make Sure가 Create로 분류되는 문제는 make 단일 키워드가 먼저 잡혀서 생겼다. 그래서 IDIOM_PATTERNS를 TYPE_PATTERNS보다 먼저 검사하게 해서 make sure -> validate로 고정했다.
4 + 5.가 번호 목록처럼 잘리는 문제는 split 규칙이 너무 넓어서 생겼다. 산술 표현 보존 조건을 추가해서 막았다.
First, Next, Finally가 task처럼 남는 문제는 순서 표식을 action clause와 묶고, 단독 후보는 제거하는 방식으로 풀었다.
document 뒤 후속 작업이 끊기는 문제도 있었다. document를 항상 마지막 task로 보면 뒤에 명시된 작업이 고립된다. 그래서 document 이후에도 명시 작업이 있으면 흐름을 이어주게 바꿨다.
50회 이상 복합 테스트와 106개 말뭉치 검증을 반복했고, Type 분류 성공률은 개선 전 70%에서 개선 후 82%까지 올라갔다. 1000회 프롬프트 테스트도 진행했다.
Context Manager
State & Context Engine은 실행 결과를 세션에 저장하고, 다음 요청에 필요한 맥락만 골라 넘기는 파트다.
TaskGraph 실행 결과를 세션에 저장·압축
다음 요청에 필요한 맥락만 선택해 전달
AI가 같은 말을 반복하지 않도록 상태 유지산출물은 SessionState, SharedContext, TaskContext로 나눴다. 처리 순서는 TaskGraph 실행 후 -> Normalize -> Save -> Compress였다. 이미 알고 있는 내용을 다시 보내지 않고, 다음 작업에 필요한 정보만 남기기 위한 구조다.
저장 파이프라인은 이렇게 잡았다.
TaskGraph
-> Execute raw result
-> Normalize summary/type
-> Save session json
-> Compress context budgetContextCompressor는 adapter의 context window를 기준으로 동적 임계값을 계산했다. Gemini / Claude는 485K, Haiku는 85K, Codex는 185K로 잡고, 최근 3개 task만 상세히 유지했다. 등록되지 않은 adapter는 Gemini 기준으로 fallback했다.
처음에는 압축이 거의 안 먹혔다. 고정 3K 기준이라 실제로는 압축이 잘 발동하지 않았고, 저장 후에는 type/success 같은 핵심 정보가 사라져 세션 복구 시 성공/실패 판단이 어려웠다. REPL에서 같은 세션 파일을 동시에 쓰면 이전 결과를 덮어쓸 위험도 있었다.
개선 후에는 압축률이 0.3%에서 43%까지 올라갔다. 핵심 정보는 Zod Schema로 보존했고, failed_task_ids도 저장했다. 동시 저장 문제는 acquireLock과 tmp -> rename atomic write로 막았다.
CLI Wrapper와 시연
CLI Wrapper 파트에서는 실제 사용 화면을 보여줘야 했다. 기능이 아무리 많아도 CLI에서 어디까지 진행됐는지 보이지 않으면 쓰기 어렵다.
시연 영상은 발표 중간에 넣었다.
CLI는 detoks로 REPL에 들어간 뒤 slash command를 쓰는 방식이다. 기본 명령어는 /help, /clear, /model, /adapter, /mode, /verbose, /exit이고, 인증 후에는 /cms, /gms, /logout까지 쓸 수 있게 했다. 총 11개 명령어다.
실행 중에는 ASCII spinner와 단계별 상태를 보여준다. 시작, 완료, 실패, 건너뜀을 구분하고, 마지막에는 토큰 절감, 파이프라인 상태, 실행 결과를 요약한다. 실패하면 stderr와 exit code 1을 숨기지 않고, 사용자에게는 한국어 요약으로 보여준다.
Codex adapter는 Codex CLI subprocess, Gemini adapter는 Gemini API subprocess 경계에서 처리했다. 이 파트에서 가장 중요했던 건 실패를 조용히 삼키지 않는 것이었다. CLI 도구는 성공했을 때보다 실패했을 때 더 친절해야 한다.
결과
성능 평가는 같은 HTML/CSS에서 시작했다. HTML/CSS는 원칙적으로 건드리지 않고 JS만 추가했다. 15턴 프롬프트 세트를 만들고, 단일 명령과 복합 명령을 섞었다. 일반 프롬프트와 DeToks 변환 프롬프트를 각각 실행해서 비교했다.
비교 지표는 아래 네 가지였다.
입력 토큰 수 감소율
최종 UI 동일성: CSS, DOM 구조, 화면 캡처
기능 동일성: 추가, 삭제, 체크, 전체삭제, localStorage, 토글, 카운트
세션 유지: 이전 턴 기능 누락 여부, 이벤트 중복 등록 여부결과는 꽤 좋았다.
토큰 절감률: 34.8%
평균 추론 시간: 0.891초
기능 품질 유지: 106/106
validation 실패: 0건DeToks를 쓰지 않았을 때는 3,784 tokens였고, 썼을 때는 2,424 tokens였다. 번역 절감은 30.243%, 압축 절감은 6.507%였다. compression fallback은 2건 있었다.
이 결과에서 제일 중요했던 건 “줄였는데도 기능이 유지됐다”는 점이었다. 토큰만 줄이려면 필요한 조건까지 지워버리면 된다. 하지만 그러면 개발 도구로는 실패다. DeToks가 보여줘야 했던 건 토큰을 줄이면서도 맥락과 실행 품질을 유지할 수 있다는 점이었다.
Phase 2로 넘긴 것
Phase 2 계획은 2주 단위로 잡았다.
Week 1은 Adapter & Evaluation이다. Claude adapter를 확장하고, 품질이 떨어졌을 때 fallback할 기준을 잡는 작업이다.
Week 2는 Dashboard & Packaging이다. README, 실행 가이드, 발표 시연 정리, 최종 demo packaging, 토큰 절감/성능 지표 확인 웹페이지가 들어간다.
파일럿 파인튜닝도 계획에 넣었다. 1400개 dataset 기준으로 best validation checkpoint 258에서 accuracy 0.9813, precision 0.9837, recall 0.9813, F1 Score 0.9815를 기록했다. Hard-eval test에서도 accuracy 0.9625, precision 0.9666, recall 0.9625, F1 Score 0.9629가 나왔다.
마무리 영상은 발표 마지막에 넣었다.
마지막 슬라이드 문장은 이거였다.
토큰은 줄이고, 줄인 만큼 더 많은 작업을.Phase 1을 끝내고 나니 DeToks가 단순한 프롬프트 압축기는 아니라는 게 더 분명해졌다. 입력을 줄이는 건 시작일 뿐이고, 진짜 중요한 건 줄인 뒤에도 작업 순서, 의존성, 필요한 맥락, 실행 결과를 놓치지 않는 것이었다.
Phase 2에서는 이 구조를 더 실제 도구처럼 다듬어야 한다. Claude adapter, dashboard, packaging, 평가 기준까지 붙이면 발표용 MVP에서 반복해서 쓸 수 있는 개발 도구에 조금 더 가까워질 수 있을 것 같다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.