오전: 스캐폴딩과 공통 컴포넌트
어제 폴더 구조만 잡고 끝났으니, 오늘은 실제로 코드를 채워야 한다.
오전 9시 39분, 첫 번째 커밋이 올라갔다.
chore: Mongle-app 초기 세팅 및 구조 스캐폴딩
어제 PR로 올려둔 chore/#1-project-pivot 브랜치가 main에 최종 머지되면서 Mongle의 공식 시작이 확정됐다. 이어서 바로 공통 컴포넌트 작업으로 넘어갔다.
feat: Add common Card component and install project dependencies.
팀 전체가 공유해서 쓸 components/common/Card.jsx를 먼저 만들었다. 어떤 화면이든 카드 레이아웃이 필요할 테니, 이걸 먼저 정의해두면 각자 작업할 때 일관성이 생긴다. 패키지 의존성도 이 커밋에서 한번에 설치했다.
이후 test.jsx로 Card 컴포넌트 import 확인, auth 테스트 화면 추가 등 몇 차례 검증 커밋이 이어졌다가, 필요 없어진 테스트 파일은 정리했다.
chore: remove unnecessary files test.jsx and error.txt
오전 작업을 깔끔하게 마무리.
11시: GitHub Issues 기능별 정리
docs: issues 내용 기능별로 추가
본격 코딩 전에 GitHub Issues를 기능별로 정리했다. 팀원들이 각자 맡은 기능을 이슈 단위로 트래킹할 수 있게. PM으로서 해야 할 일이기도 하고, 나중에 PR을 이슈에 연결하면 진행 상황이 훨씬 명확해진다.
오후 1: FastAPI 백엔드 폴더 구조
feat: 백엔드 폴더 구조 생성— 12:19
데이터를 보여줄 API가 없으면 프론트엔드가 붙을 수 없다. 팀원 C(백엔드 담당)와 협의해서 먼저 라우터 구조를 잡아두기로 했다.
Mongle-server/
├── main.py
├── requirements.txt
└── api/
├── __init__.py
├── budget.py # 예산 API
├── chat.py # 챗봇 API
├── timeline.py # 타임라인 API
└── vendors.py # 업체 APIFastAPI 기반, 라우터는 기능별로 분리. requirements.txt도 같이 추가했다. 아직 각 파일은 라우터 뼈대만 있지만, 인터페이스를 먼저 합의해두면 프론트와 백이 병렬로 개발하기 수월해진다.
오후 2: AI 아키텍처 설계
feat: Introduce AI component with intent parser, responder, and dummy vendors.— 14:58chore: ai 관련 폴더 생성— 16:06
AI 챗봇의 두뇌 구조를 설계했다. 내가 PM이면서 AI 챗봇 UI를 담당하는 만큼, 백엔드 AI 파이프라인도 직접 짰다.
아키텍처: 3-Layer Pipeline
사용자 메시지
↓
[intent_parser.py] → 의도 파악 (JSON 추출)
↓
[responder.py] → 업체 추천 + 응답 생성
↓
[dummy_vendors.py] → (임시) 더미 업체 데이터intent_parser.py — 사용자 메시지에서 검색 조건을 추출한다. GPT-4o-mini에게 JSON 형태로 반환받는 방식으로, 비동기(AsyncOpenAI)로 구현했다.
async def parse_intent(message: str) -> dict:
response = await client.chat.completions.create(
model="gpt-4o-mini",
response_format={"type": "json_object"},
messages=[
{
"role": "system",
"content": """
사용자의 웨딩 메시지에서 검색 조건을 JSON으로 추출해.
반환 형식:
{
"categories": ["studio", "dress", "makeup", "hall"],
"style": ["모던", "내추럴", "클래식", "럭셔리", "빈티지"],
"region": null,
"budget_max": null,
"is_wedding_query": true
}
"""
},
{"role": "user", "content": message}
]
)
return json.loads(response.choices[0].message.content)“강남 근처 모던한 스튜디오 추천해줘” 같은 자연어 입력이 들어오면, {"categories": ["studio"], "style": ["모던"], "region": "강남구", ...} 형태의 JSON이 나온다. 이걸 가지고 Supabase에서 필터 쿼리를 날리는 구조다.
responder.py — 파싱된 의도와 업체 목록을 받아서 최종 응답을 생성한다.
dummy_vendors.py — 실제 데이터가 올라가기 전까지 테스트용 더미 업체 61개를 하드코딩해뒀다.
오후 3: 카카오 API 크롤링 — 그리고 삽질들
AI 챗봇이 추천할 실제 업체 데이터가 필요하다. 더미 데이터로 데모는 할 수 있지만, 서비스다운 느낌을 주려면 진짜 서울 업체 데이터가 있어야 한다.
카카오 로컬 API를 택했다. 무료에 호출량도 넉넉하고, 업체 이름·주소·카테고리가 깔끔하게 나온다.
크롤링 설계
KEYWORDS = {
"studio": ["서울 웨딩스튜디오", "서울 웨딩사진", "서울 스냅촬영", ...],
"dress": ["서울 웨딩드레스", "서울 드레스샵", "서울 턱시도", ...],
"makeup": ["서울 웨딩메이크업", "서울 웨딩헤어", "서울 브라이덜샵", ...],
"hall": ["서울 웨딩홀", "서울 스몰웨딩", "서울 호텔웨딩", ...],
}
SEOUL_DISTRICTS = [
("강남구", 37.5172, 127.0473),
("서초구", 37.4837, 127.0324),
("마포구", 37.5663, 126.9014),
("송파구", 37.5145, 127.1059),
("종로구", 37.5735, 126.9790),
("용산구", 37.5384, 126.9654),
("강서구", 37.5509, 126.8495),
("영등포구", 37.5263, 126.8963),
]4개 카테고리 × 5개 키워드 × 8개 구 × 좌표 반경 5km로 쿼리를 돌렸다. 중복 제거는 seen_ids set으로 처리.
이슈 1: 카카오 API 초기 0건
첫 실행에서 결과가 하나도 안 나왔다. response.status_code는 200인데 documents가 빈 배열. 디버깅을 위해 응답 전체를 출력해보니 파라미터 오류였다. 카카오 API는 좌표를 x(경도), y(위도) 순으로 받는데, 위도/경도를 반대로 넣고 있었다. 수정하니 바로 데이터가 쏟아졌다.
이슈 2: 한글 인코딩
터미널 출력이 전부 깨졌다. 처음엔 sys.stdout을 UTF-8 래퍼로 교체했는데, 일부 환경에서 여전히 깨지는 경우가 있었다. 결국 스크립트 상단에서 직접 환경변수를 세팅하는 방식으로 해결했다.
os.environ["PYTHONIOENCODING"] = "utf-8"이슈 3: .env 경로 & json 경로
load_dotenv()가 API 키를 못 찾았다. 스크립트 위치가 Mongle-server/ai/script/ 안이라 상대 경로로 .env를 못 찾는 문제였다. 절대 경로로 명시해서 해결했다.
env_path = Path(__file__).parent.parent.parent / ".env"
load_dotenv(dotenv_path=env_path)raw_vendors.json도 같은 이유로 FileNotFoundError가 났고, 동일하게 절대 경로로 수정.
레이블링: GPT-4o-mini로 987개 자동 분류
크롤링으로 수집한 원시 데이터(raw_vendors.json)에는 업체 이름과 주소만 있다. 이걸 AI 챗봇이 쓸 수 있는 구조화된 데이터로 바꿔야 한다.
GPT-4o-mini에게 업체별로 이런 형태의 JSON을 뽑아달라고 했다.
prompt = f"""
아래 웨딩 업체 정보를 분석해서 JSON으로 반환해줘.
업체 정보:
- 이름: {vendor['name']}
- 카테고리: {vendor['raw_category']}
- 주소: {vendor['region']}
반환 형식:
{{
"style": ["모던", "내추럴", "클래식", "럭셔리", "빈티지", "로맨틱"] 중 해당하는 것들,
"district": "강남구" 처럼 구 이름만,
"price_min": 예상 최소 가격 (만원, 모르면 null),
"price_max": 예상 최대 가격 (만원, 모르면 null),
"description": 업체 특징 한 줄 요약
}}
"""이슈 4: Ctrl+C로 147개 날림
레이블링 스크립트를 실행하고 기다리는데, 중간에 실수로 Ctrl+C를 눌러버렸다. 중간 저장 로직이 없으니 지금까지 처리한 게 전부 날아갔다. 147개 분량이 허공으로.
바로 중간 저장 로직을 추가했다. 10개마다 자동으로 파일에 저장하도록.
# 10개마다 중간 저장
if (i + 1) % 10 == 0:
with open(output_path, "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)이후 재실행. 이번엔 끝까지 완료.
최종 커밋: 987개 수집 완료
실제 식장, 스, 드, 메 web crawling 및 987개소 분류 완료— 17:09 28,676 lines added
raw_vendors.json → 10,859 lines (원시 업체 데이터)
labeled_vendors.json → 17,768 lines (AI 레이블링 완료)
upload_to_supabase.py → Supabase 업로드 스크립트서울 웨딩홀·스튜디오·드레스·메이크업 업체 987개소, 전부 AI가 스타일과 가격대를 분류한 상태. 내일 팀원들과 함께 Supabase에 올리면 AI 챗봇이 실제 데이터를 기반으로 추천을 시작할 수 있다.
이날 Evan-Yoon이 머지한 PR만 5개다.
오늘을 돌아보며
오늘은 계획했던 것보다 환경 설정과 오류 해결에 시간을 많이 썼다. 특히 Ctrl+C로 147개를 날린 건 단순한 실수였는데, 그 덕분에 중간 저장 로직의 필요성을 몸으로 배웠다. 처음부터 방어적으로 코드를 짜는 습관이 중요하다는 걸 다시 느꼈다.
크롤링으로 987개 업체를 수집하고, 레이블링까지 자동화한 건 꽤 뿌듯하다. 단순 더미 데이터가 아니라 실제 서울 업체 데이터를 AI로 분류한다는 게 서비스다운 느낌을 준다.
내일은 오류 없이 chat.py까지 완성하는 게 목표다.
화면 기록
Day 2는 화면보다 AI 백엔드 구조를 먼저 세운 날이었다. 실제로 어떤 코드를 붙였고, 어떤 주제로 챗봇을 만들었는지가 보이는 자료를 같이 남긴다.
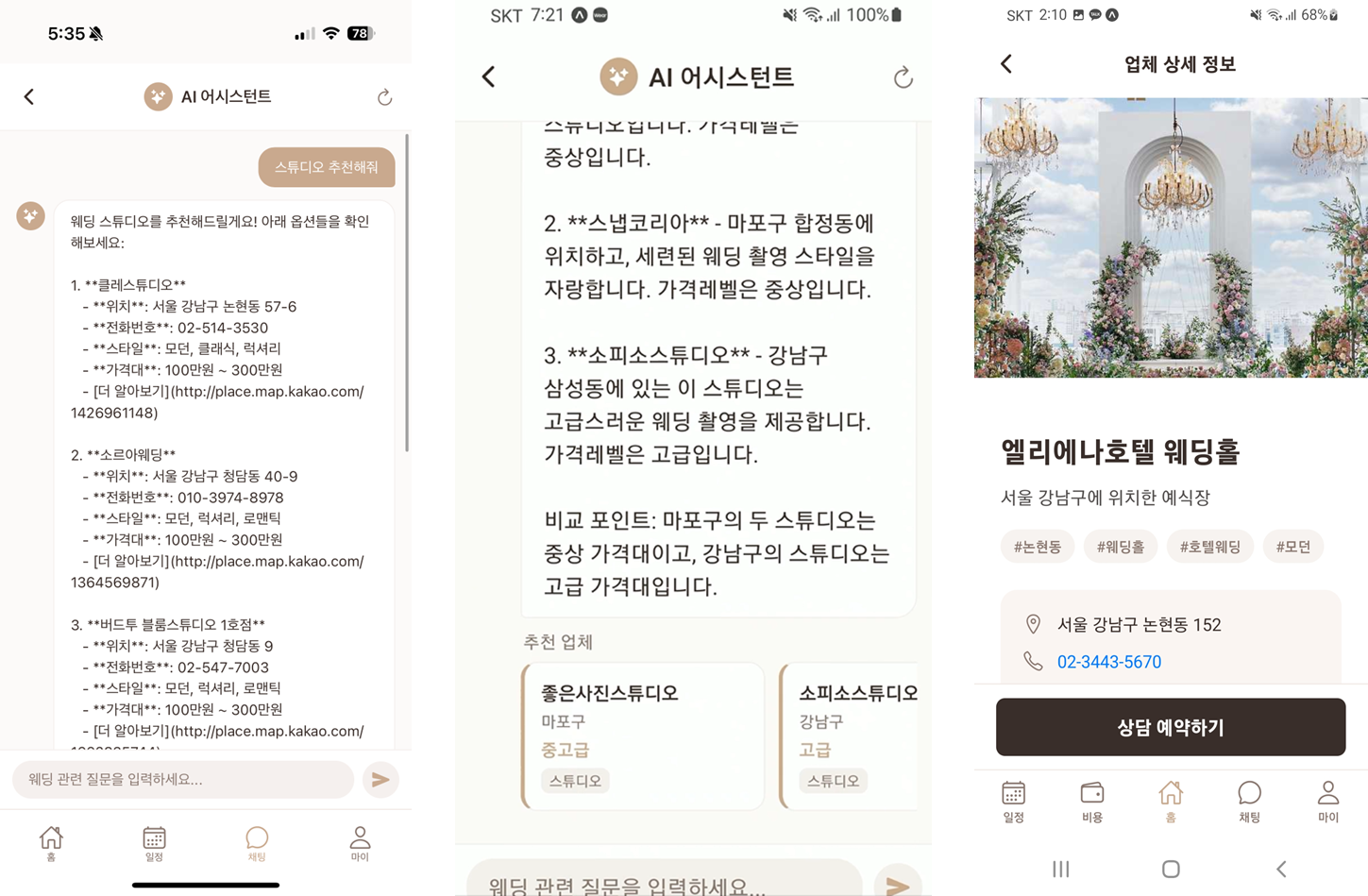
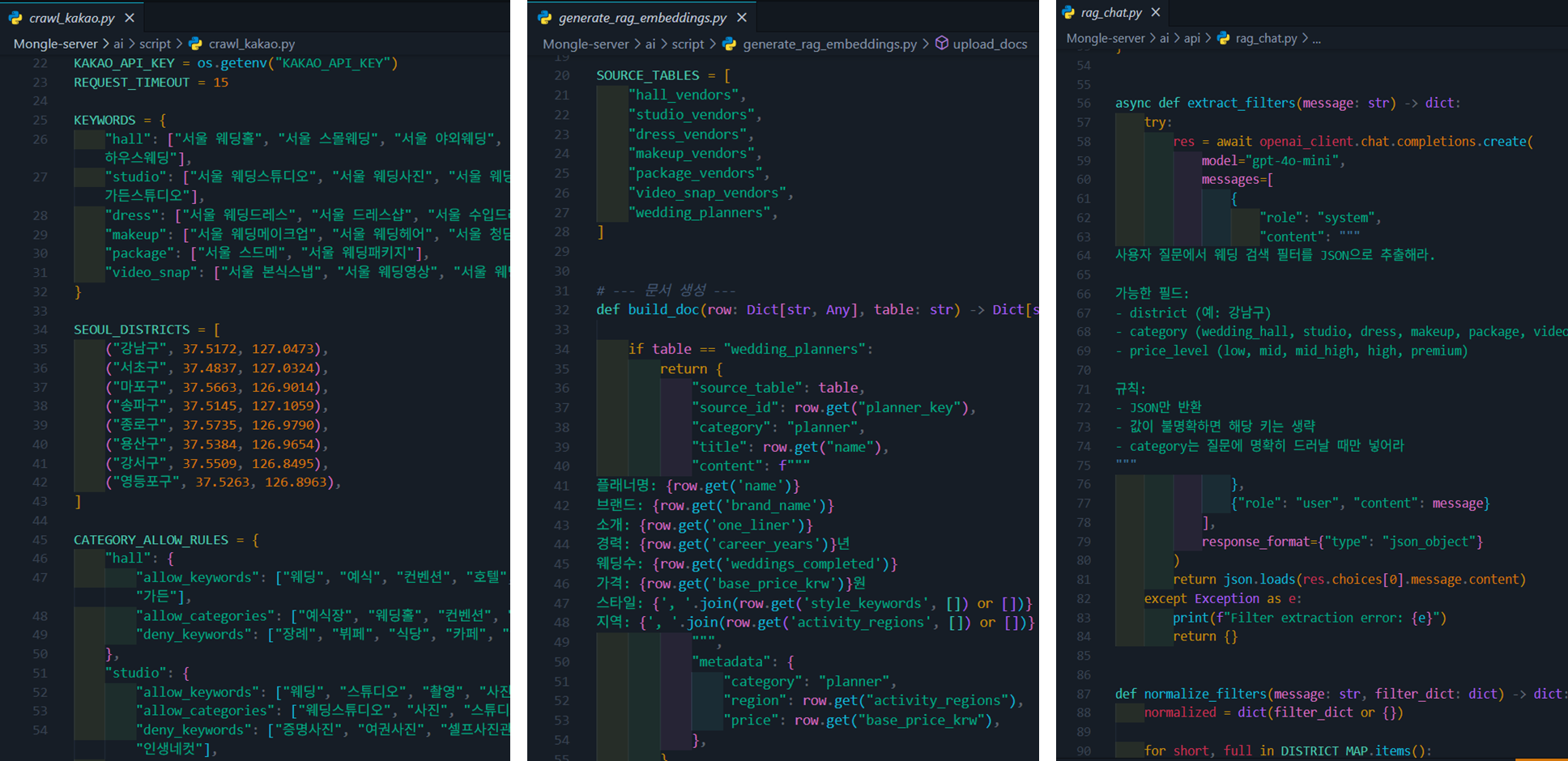
GitHub: APP-Project-Team1/mongle
백엔드 구조를 먼저 세운 덕분에 얻은 것
Mongle의 기능은 표면적으로는 챗봇이나 예산 분석처럼 AI 기능이 눈에 띄지만, 실제로는 데이터 흐름이 더 중요했다. 업체 정보가 어떤 경로로 수집되고, 어떤 형태로 정제되며, 사용자의 질문과 어떻게 연결되는지가 정리되지 않으면 AI 응답 품질도 안정적으로 유지되기 어렵다. 그래서 Day 2에서 백엔드와 크롤링 아키텍처를 먼저 다진 것은 이후 기능을 빠르게 붙이기 위한 기반 작업이었다.
특히 크롤링은 한 번 데이터를 가져오는 것으로 끝나지 않는다. 출처별 포맷 차이, 중복 제거, 누락 필드 보정, 업데이트 주기, 법적·운영상의 경계까지 고려해야 한다. 이 단계에서 수집과 저장, 조회를 분리해서 본 덕분에 나중에 RAG나 추천 기능을 붙일 때도 구조가 크게 흔들리지 않았다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.