오전: 데이터 대수술
어제까지의 챗봇은 dummy_vendors.py에 하드코딩된 61개 업체를 기반으로 돌아갔다. 오늘은 그걸 걷어내고 Supabase에 실제 데이터를 올리는 게 첫 번째 목표였다.
그런데 시작하려고 보니 기존 데이터 구조에 문제가 있었다. 어제 만든 labeled_vendors.json 하나에 식장·스튜디오·드레스·메이크업이 전부 뒤섞여 있어서, 카테고리별 쿼리를 날리기도 불편하고 Supabase 테이블 구조와도 맞지 않았다.
홀,스,드,메,패키지,스냅 데이터 추가— 11:43 76,481 insertions, 35,766 deletions
카테고리별로 파일을 완전히 분리했다.
Mongle-server/ai/script/vendors/
├── hall_vendors.json # 웨딩홀 · 예식장
├── studio_vendors.json # 스튜디오 · 본식스냅
├── dress_vendors.json # 드레스 · 한복
├── makeup_vendors.json # 메이크업 · 헤어
├── package_vendors.json # 스드메 패키지
└── video_snap_vendors.json # 영상 · 스냅기존 통합 파일은 삭제하고, 크롤링 규칙도 crawling_rule.md와 dummy_rule.md로 문서화했다. 데이터 규모가 커지면서 어떤 기준으로 수집하고 레이블링했는지 팀원들이 알 수 없으면 나중에 유지보수가 힘들어진다.
오전 내내 Merge PR도 이어졌다.
오후 1: Supabase 마이그레이션
챗봇용 데이터베이스 supabase에 업로드— 14:55, 14:58
분리된 JSON 파일들을 Supabase에 올렸다. 두 번에 나눠서 커밋된 건 첫 번째 시도에서 스키마 불일치가 있어서 수정 후 재업로드했기 때문이다.
이 시점부터 챗봇은 로컬 더미 데이터가 아닌 실제 Supabase DB를 바라보게 된다. 팀원 C(백엔드 담당)도 이 타이밍에 맞춰 frontend payload ↔ backend models ↔ Supabase schema 정합성을 맞추는 작업을 진행했다.
오후 2: RAG 챗봇 구현
feat: 챗봇에 RAG 기능 구현— 16:12Mongle-server/ai/api/rag_chat.py— 212 lines 신규 생성
어제 챗봇은 더미 데이터를 LLM에게 통째로 넘겨줬다. 오늘부터는 사용자 질문에서 검색 필터를 먼저 추출하고, Supabase에서 관련 업체만 조회해서 LLM에게 넘기는 RAG(Retrieval-Augmented Generation) 구조로 전환했다.
파이프라인
사용자 메시지
↓
extract_filters() → GPT-4o-mini로 검색 필터 JSON 추출
↓
Supabase 쿼리 → district + category 기반 필터링
↓
generate_response() → 실제 업체 데이터 기반 스트리밍 응답extract_filters() — 자연어에서 구조화된 필터를 뽑는다.
async def extract_filters(message: str) -> dict:
res = await openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{
"role": "system",
"content": """
사용자 질문에서 웨딩 검색 필터를 JSON으로 추출해라.
가능한 필드:
- district (예: 강남구)
- category (wedding_hall, studio, dress, makeup, package, video_snap, planner)
"""
}, {"role": "user", "content": message}]
)지역명 정규화 — “강남”이라고 입력해도 “강남구”로 매핑되도록 사전을 만들었다.
DISTRICT_MAP = {
"강남": "강남구", "서초": "서초구", "송파": "송파구",
"마포": "마포구", "종로": "종로구", "용산": "용산구",
# ... 17개 구
}카테고리 별칭 처리 — “예식장”, “호텔 웨딩홀”은 wedding_hall로, “스드메”는 package로.
CATEGORY_ALIAS = {
"웨딩홀": "wedding_hall", "예식장": "wedding_hall",
"호텔 웨딩홀": "wedding_hall", "호텔": "wedding_hall",
"스튜디오": "studio", "드레스": "dress",
"스드메": "package", "패키지": "package",
"영상": "video_snap", "스냅": "video_snap",
}이 덕분에 사용자가 어떻게 표현해도 Supabase 쿼리로 연결된다.
feat: 호텔 데이터 매핑 수정— 16:22
RAG 테스트 중 “호텔 웨딩” 검색 시 결과가 비어있는 문제가 발견됐다. CATEGORY_ALIAS에 “호텔식 웨딩홀” 같은 변형이 빠져있었다. 바로 수정해서 재커밋.
이 시간대 Merge PR.
오후 3: 예산 최적화 AI
feat: AI 분석 기능 추가— 17:46feat: 예산 관리 ai bug 수정— 17:47 총 10 files, 900+ insertions
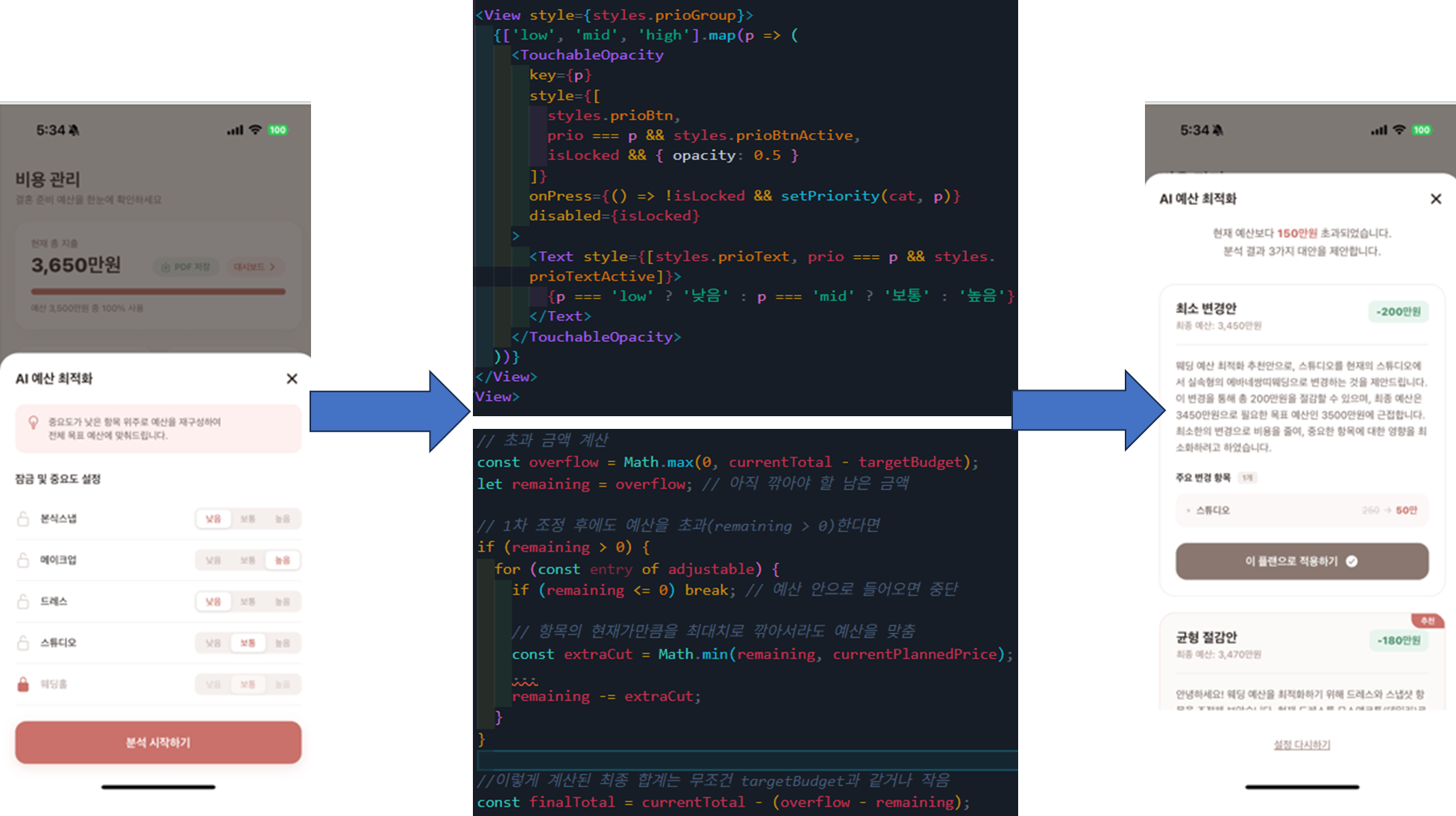
예산 화면에서 “내 예산에 맞게 업체를 최적화해줘” 요청이 들어오면 AI가 현재 선택된 업체 조합을 분석해서 더 저렴하면서도 스타일이 비슷한 대안을 추천하는 기능이다.
BudgetAnalyzer — 스타일 유사도 기반 추천
class BudgetAnalyzer:
def calculate_style_similarity(self, tags_a, tags_b) -> float:
# Jaccard 유사도
set_a, set_b = set(tags_a), set(tags_b)
intersection = set_a.intersection(set_b)
union = set_a.union(set_b)
return len(intersection) / len(union) if union else 0.5
def find_best_replacement(self, category, current_price, style_tags, target_price, locked_ids):
candidates = [v for v in self.all_vendors
if v["category"] == category
and v["vendor_id"] not in locked_ids]
suitable = [v for v in candidates if v["price_min"] <= target_price]
ranked = []
for v in suitable:
sim = self.calculate_style_similarity(style_tags, v.get("style_tags", []))
price_score = 1.0 - (v["price_min"] / current_price) if current_price > 0 else 0
score = (sim * 0.6) + (price_score * 0.4) # 스타일 60%, 가격 40%
ranked.append((score, v))Jaccard 유사도로 스타일 태그 겹침을 계산하고, 가격 절감 점수와 6:4 가중합으로 최종 점수를 낸다. locked_ids로 사용자가 “이 업체는 바꾸지 마”라고 고정한 항목은 제외한다.
프론트엔드 — BudgetOptimizationModal.jsx (452줄)와 useBudgetOptimization.js (44줄).
const optimize = useCallback(async (params) => {
const response = await fetch(`${BASE_URL}/api/v2/budget/optimize`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(params),
});
const data = await response.json();
setResult(data);
return data;
}, []);budget_rule.md (311줄)도 작성했다. 예산 분석 로직의 판단 기준을 문서화해서, 나중에 프롬프트나 로직을 수정할 때 기준점이 되도록.
chore: merge origin/main and resolve package-lock.json conflict— 18:03
하루 동안 여러 브랜치가 동시에 작업되다 보니 package-lock.json이 충돌했다. main을 머지하면서 수동으로 정리했다.
밤: 플래너 관리자 웹 (Admin Web) 전체 스캐폴딩
design: 플래너용 웹페이지 제작— 21:54 53 files, 6,341 insertions(+)
퇴근 후 밤에 예상 밖의 커밋이 하나 더 올라왔다. Mongle-admin-web/ — 플래너 전용 관리자 웹을 새로 만들기 시작했다.
모바일 앱(Expo)은 예비 부부가 쓰는 클라이언트다. 플래너는 고객을 관리하고, 일정을 조율하고, 예산 현황을 확인해야 한다. 이걸 모바일에서 하기엔 한계가 있어서 별도 웹 대시보드를 만들기로 했다.
기술 스택: React + Vite
구현된 페이지:
src/pages/
├── Dashboard.jsx # KPI 그리드, 커플 위젯, 예산 위젯, 업체 위젯
├── CoupleList.jsx # 고객(커플) 목록 관리
├── Budget.jsx # 예산 현황
├── TodoList.jsx # 할 일 목록
├── Notifications.jsx # 알림
├── VendorPartners.jsx # 연계 업체
└── auth/
├── Login.jsx
├── Register.jsx
└── ForgotPassword.jsxContext API로 전역 상태 관리:
context/
├── AuthContext.jsx # 플래너 인증 세션
├── NotificationsContext.jsx # 알림 상태
├── ThemeContext.jsx # 다크/라이트 모드
└── TodoContext.jsx # 할 일 상태대시보드 위젯(CoupleWidget, FinanceWidget, KpiGrid, TodoWidget, VendorWidget), 공통 컴포넌트(Avatar, Badge, ProgressBar), AdminLayout까지 한 번에 올라왔다. 하루를 마무리하면서 혼자 밤에 작업한 것인데, 53개 파일 6,341줄이 한 커밋에 담겼다.
오늘을 돌아보며
데이터 표준화와 마이그레이션 작업을 통해 본격적인 서비스 연동의 기틀을 마련한 하루였다.
하루 동안 일어난 일을 정리하면:
- 더미 데이터 → 카테고리별 JSON 분리 → Supabase 마이그레이션
- 단순 프롬프트 챗봇 → RAG 구조 전환 (필터 추출 + Supabase 쿼리 + 스트리밍)
- 예산 최적화 AI (Jaccard 유사도 기반 스타일 매칭)
- 플래너 관리자 웹 전체 스캐폴딩
내일은 플래너 대시보드 UI 고도화와 Supabase 데이터 정합성 검증이 목표다.
화면 기록
RAG 챗봇을 실제 데이터와 연결하고, 비용 관리 AI와 플래너용 예산 화면까지 붙인 날이라 Day 4에는 예산 관련 자료를 묶어 두는 게 가장 자연스럽다.
GitHub: APP-Project-Team1/mongle
RAG와 운영 화면을 함께 본 이유
RAG는 검색 품질만 좋아진다고 끝나는 기능이 아니다. 어떤 데이터를 검색 대상으로 삼을지, 응답에 어떤 근거를 담을지, 오래된 정보가 섞였을 때 어떻게 보정할지가 함께 정리돼야 한다. Day 4에서 예산 AI와 관리자 웹을 같이 다룬 것은 이 때문이다. 사용자에게 더 나은 답변을 주려면 운영자가 데이터 상태를 파악하고 수정할 수 있어야 한다.
결국 좋은 AI 기능은 좋은 운영 도구 위에서만 오래 버틸 수 있다. 관리자 웹을 따로 후순위로 미루지 않고 함께 설계한 덕분에, Mongle은 단순 체험형 데모가 아니라 유지 가능한 서비스 구조에 더 가까워졌다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.