NLP 수업은 일단 마무리됐지만, RNN·LSTM·GRU·Transformer 슬라이드는 한 번에 이해하기 쉽지 않았다. 특히 RNN 파트는 식이 갑자기 많아지고, h_t, W_xh, W_hh 같은 기호가 연달아 나와서 흐름을 놓치기 쉬웠다. 그래서 이 글에서는 강의 자료 1~41페이지를 기준으로, RNN을 “시계열 데이터를 다루기 위해 나온 신경망”이라는 관점에서 다시 정리해 보려고 한다.
중요한 것은 수식을 외우는 것이 아니다.
이 글에서는 다음 네 가지만 분명하게 이해하는 것을 목표로 한다.
- 왜 일반 신경망으로는 시계열을 다루기 불편한가
- RNN은 이전 정보를 어떤 방식으로 현재에 넘기는가
- RNN은 어떤 형태의 문제에 쓰이는가
- 왜 RNN은 긴 문장에서 점점 약해지는가
1. 일반 데이터와 시계열 데이터는 무엇이 다른가
강의 자료 앞부분은 아주 단순한 비교에서 시작한다. 자동차 가격표처럼 각 행이 서로 독립적인 데이터는 일반적인 표 형태 데이터다. 반면 센서 데이터처럼 시간 순서대로 쌓이는 데이터는 시계열 데이터다.
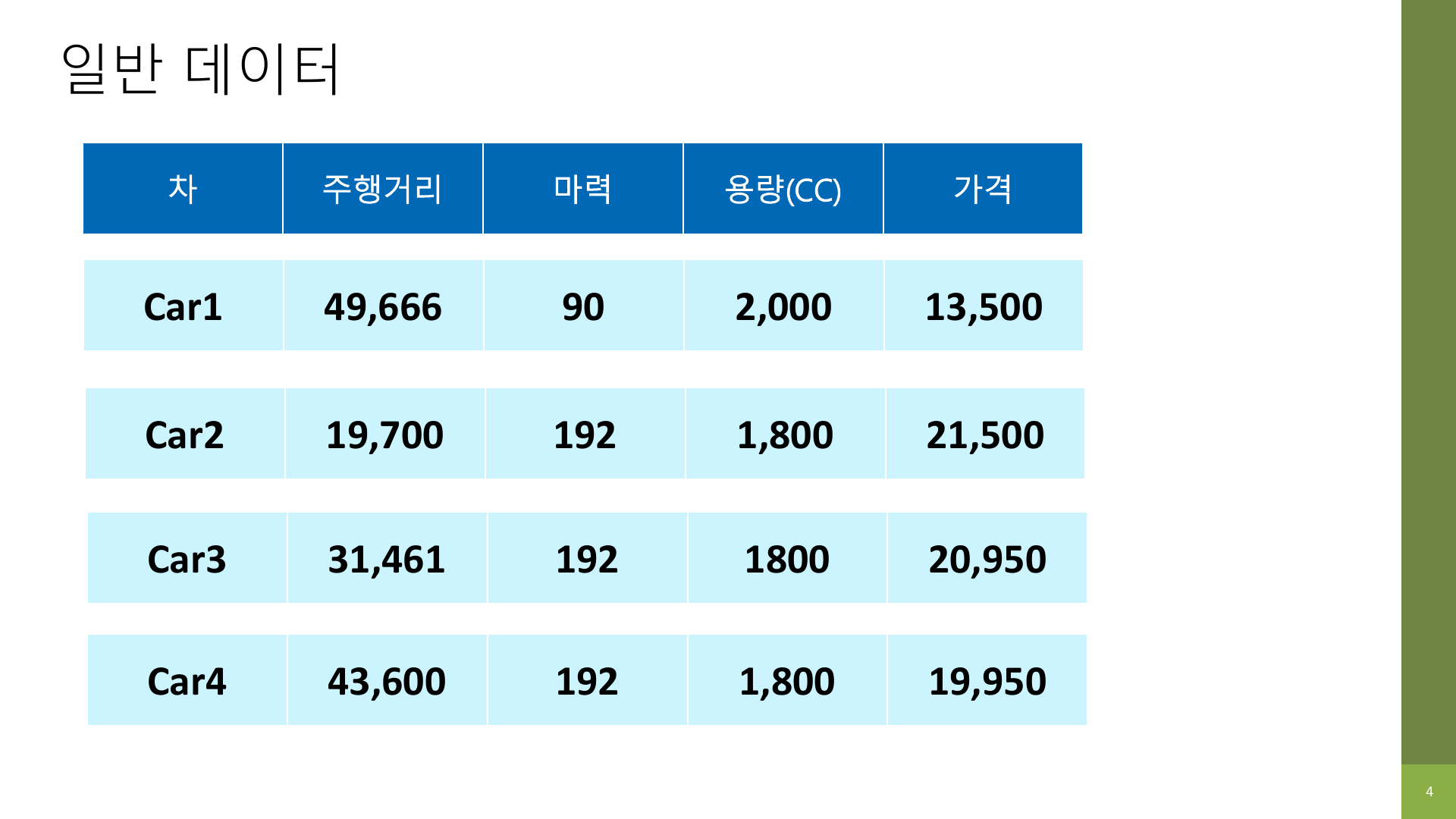
위 표에서는 Car1, Car2, Car3가 서로 독립적이다. Car1의 마력이 Car2의 가격에 직접 영향을 주는 구조는 아니다. 그래서 일반적인 머신러닝 모델은 한 행씩 따로 보고도 학습이 가능하다.
반면 시계열 데이터는 다르다.
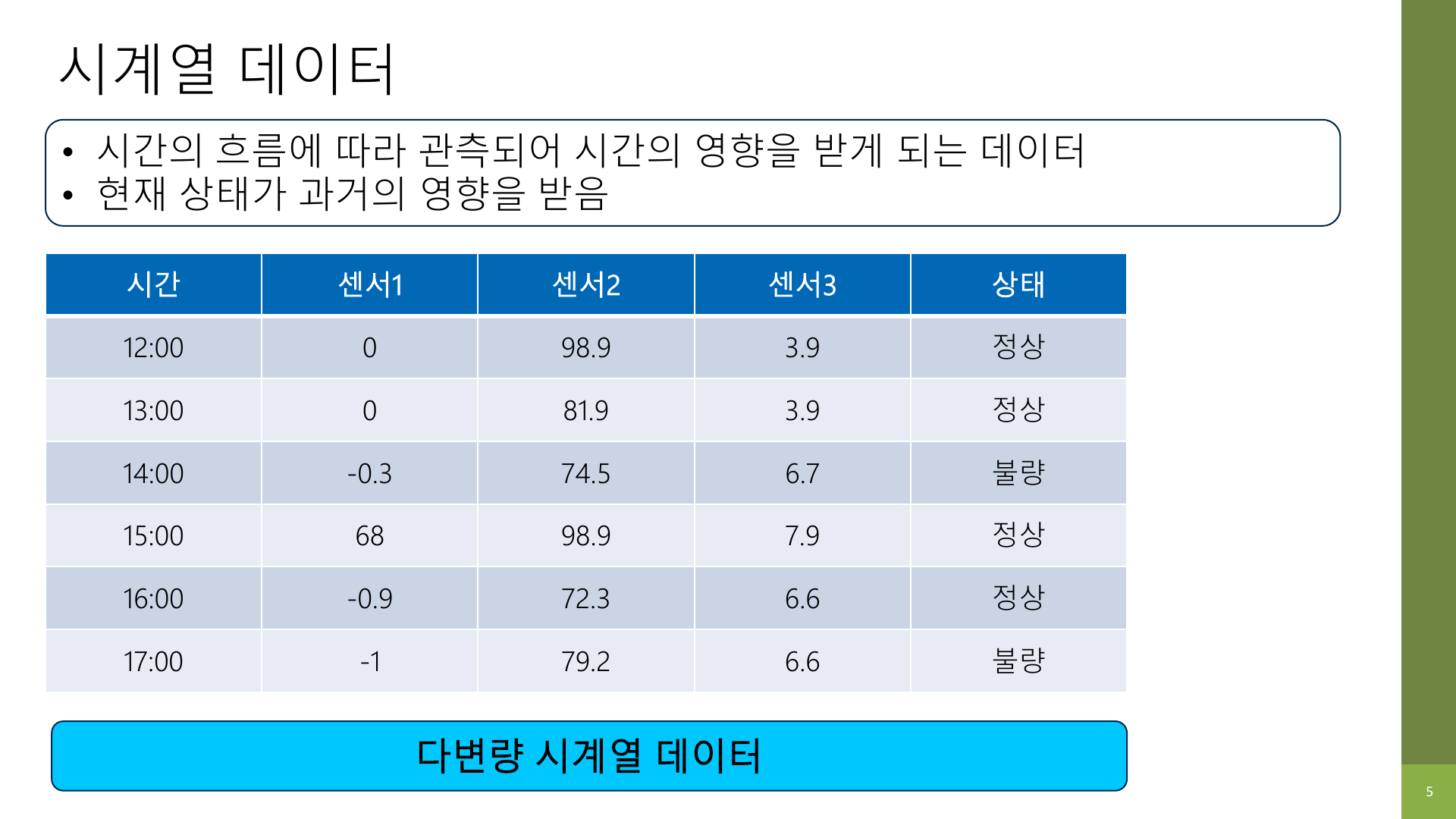
시간이 붙는 순간 데이터의 의미가 달라진다.
- 14시의 상태는 13시와 12시의 흐름과 연결될 수 있다.
- 현재 값이 비슷해 보여도, 직전까지의 변화 패턴이 다르면 상태 해석이 달라질 수 있다.
- 즉, “지금 값 하나”만 보는 것으로는 부족할 수 있다.
이건 NLP에서도 그대로 적용된다.
문장에서 현재 단어 하나만 보고 뜻을 알 수 없는 경우가 많기 때문이다.
"bank"는 앞뒤 문맥에 따라 은행일 수도 있고 강둑일 수도 있다."not bad"는bad라는 단어가 있어도 긍정에 가까운 표현이 될 수 있다."I am fine"와"I am not fine"는 마지막에 붙는 단어 하나가 전체 뜻을 바꾼다.
즉, 시계열 데이터와 자연어 데이터는 둘 다 순서와 이전 정보가 중요하다는 공통점이 있다.
2. 왜 일반 신경망으로는 부족한가
강의 자료에서는 먼저 일반적인 신경망이 입력 x_t를 받아 은닉표현 h_t를 만들고, 거기서 출력 y_t를 예측하는 구조를 보여준다.
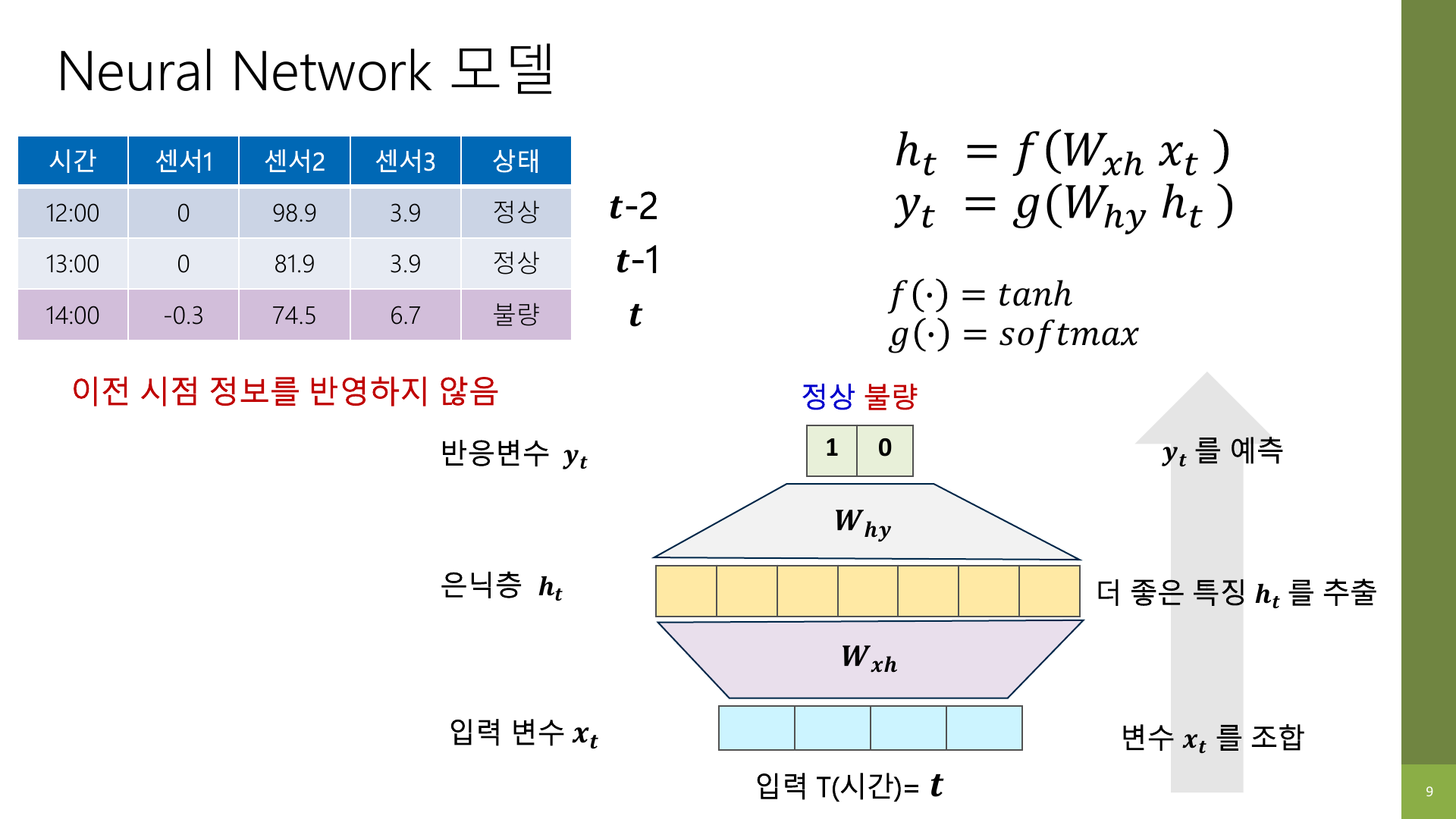
문제는 이 구조가 현재 시점의 입력만 본다는 점이다.
예를 들어 14시 센서값으로 불량을 예측한다고 해도, 13시와 12시에 어떤 흐름이 있었는지는 반영하지 못한다.
NLP로 바꿔 보면 이런 느낌이다.
"movie was good"를 볼 때는good이 긍정 신호다.- 그런데
"movie was not good"에서는 바로 앞의not이 매우 중요하다. - 현재 단어 하나만 보면 전체 문장을 잘못 이해할 수 있다.
그래서 나온 생각이 단순하다.
지금 입력만 보지 말고, 이전 시점에서 만들어 둔 요약 정보도 같이 보자.
이 아이디어가 RNN의 출발점이다.
3. RNN의 핵심 아이디어: 이전 정보를 함께 넘기기
강의 자료에서는 RNN의 필요성을 단계적으로 설명한다. 현재 입력 x_t만 쓰는 것이 아니라, 이전 시점의 은닉 상태 h_{t-1}도 같이 사용하자는 것이다.
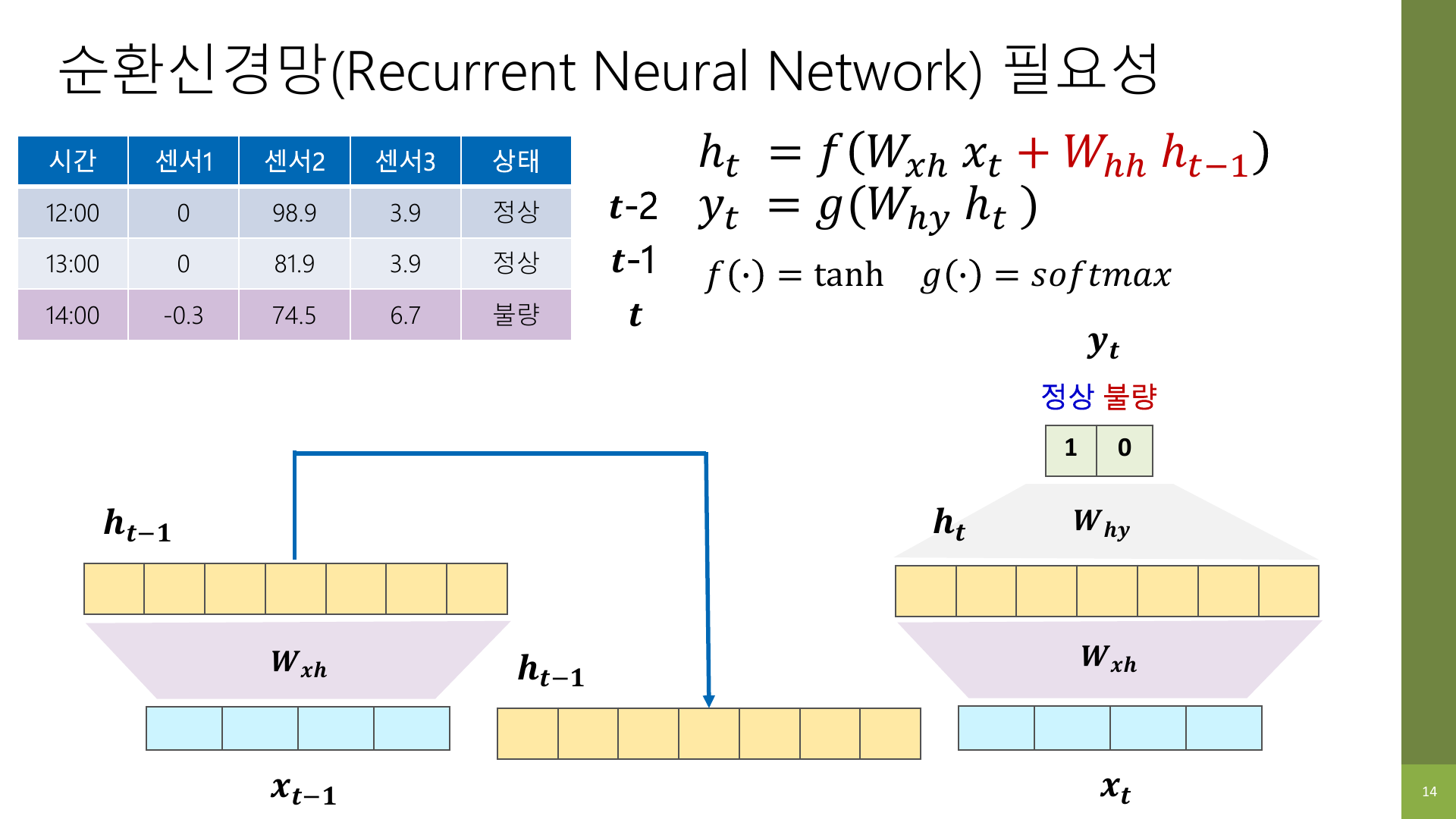
수식이 나오면 어려워 보이지만, 의미는 아주 단순하다.
현재 상태 = 현재 입력 정보 + 이전까지 요약해 둔 정보좀 더 RNN답게 쓰면 다음과 비슷하다.
h_t = tanh(현재 입력을 변환한 값 + 이전 hidden state를 변환한 값)여기서 기호를 직관적으로 바꿔 읽으면 이렇다.
x_t: 지금 들어온 입력h_{t-1}: 바로 전 시점까지 기억한 요약본h_t: 지금 시점에서 새로 만든 요약본y_t: 현재 시점의 예측 결과
즉, RNN은 문장 전체를 통째로 한 번에 보는 것이 아니라, 한 단어씩 읽으면서 메모를 갱신해 가는 방식에 가깝다.
예를 들어 "I am not happy"를 왼쪽부터 읽는다고 해 보자.
I를 읽고 일단 주어 정보를 저장한다.am을 읽고 문장 구조를 조금 더 이해한다.not을 읽고 뒤의 감정을 뒤집을 준비를 한다.happy를 읽을 때, 그냥happy만 보는 것이 아니라 직전의not정보도 함께 반영한다.
RNN이 하려는 일이 바로 이것이다.
3-1. 식을 겁먹지 않고 읽는 법
RNN 식이 어렵게 느껴지는 가장 큰 이유는 기호가 많아서다.
하지만 아래처럼 뜻으로 바꿔 읽으면 생각보다 단순하다.

h_t = tanh(W_xh x_t + W_hh h_{t-1} + b_h)이 식은 사실 한 문장으로 끝난다.
지금 입력에서 얻은 정보와, 직전까지 기억하고 있던 정보를 합쳐서, 새 hidden state를 만든다.
각 기호를 말로 바꾸면 이렇다.
x_t: 현재 시점의 입력h_{t-1}: 직전 시점까지의 기억W_xh: 현재 입력을 얼마나 반영할지 배우는 가중치W_hh: 과거 기억을 얼마나 반영할지 배우는 가중치b_h: 전체 계산을 미세하게 조정하는 기준값tanh: 값이 너무 커지지 않게 눌러 주는 함수
즉, RNN 식은 “현재와 과거를 섞는 공식”이라고 보면 된다.
3-2. 가중치는 무엇을 배우는가
여기서 W가 붙은 가중치는 단순한 숫자 묶음이 아니다.
모델이 학습하면서 “무엇이 중요한지”를 조정하는 손잡이 역할을 한다.
예를 들어 감정 분석에서 다음 두 단어를 생각해 보자.
goodnot
처음에는 모델이 두 단어를 어떻게 해석해야 할지 잘 모른다.
하지만 학습을 반복하면 W_xh는 어떤 입력이 hidden state를 크게 바꾸는지 점점 배우게 된다.
또 W_hh는 직전 문맥을 다음 시점까지 얼마나 강하게 이어갈지 조절하게 된다.
사람이 읽을 때도 비슷하다.
- 중요한 단어를 보면 메모를 크게 수정하고
- 중요하지 않은 단어는 가볍게 넘긴다
RNN의 가중치도 결국 이 차이를 숫자로 배우는 것이다.
3-3. tanh는 왜 들어가는가
처음 RNN 식을 보면 tanh가 왜 필요한지도 낯설다.
이 함수는 아주 거칠게 말하면 값을 -1과 1 사이로 눌러 주는 장치다.
만약 현재 입력과 과거 기억을 계속 더하기만 하면 hidden state 값이 점점 너무 커질 수 있다.
그러면 학습이 불안정해지고, 어떤 단어가 들어와도 값이 폭주해서 해석이 어려워진다.
tanh는 이 문제를 줄여 준다.
- 큰 양수는 1에 가깝게 눌러 주고
- 큰 음수는 -1에 가깝게 눌러 주고
- 0 근처 값은 비교적 자연스럽게 살려 둔다
수학적으로 아주 엄밀하게 이해하지 않아도 괜찮다.
RNN에서는 tanh를 “메모 값이 너무 커지지 않게 정리해 주는 함수”라고 이해해도 충분하다.
4. RNN은 왜 “순환” 신경망인가
강의 자료에서는 같은 셀이 시간축으로 반복되며 연결되는 그림을 보여 준다.
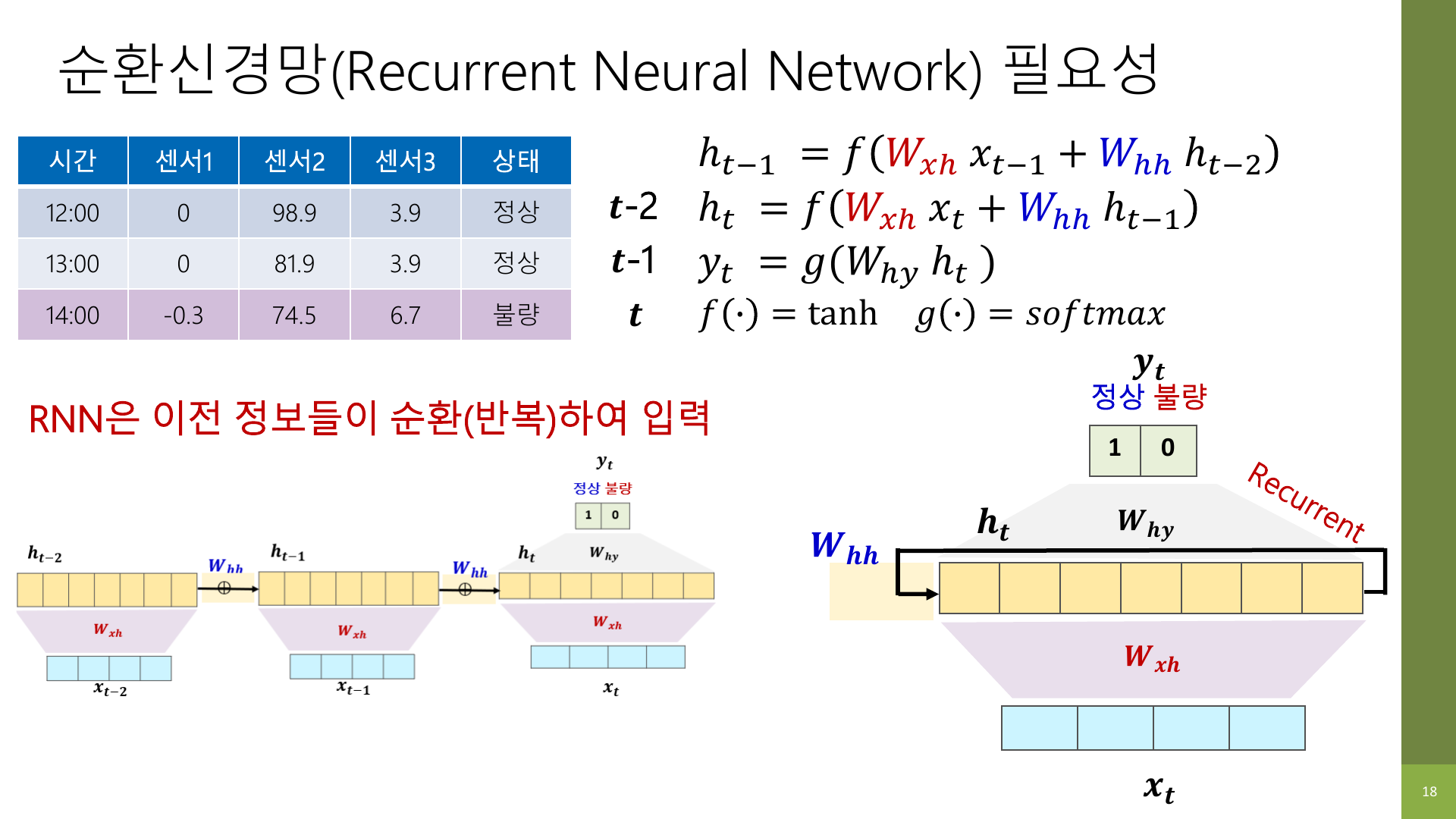
여기서 “순환”은 같은 계산 구조가 계속 반복된다는 뜻이다.
- 1번째 단어를 읽을 때도 같은 셀
- 2번째 단어를 읽을 때도 같은 셀
- 3번째 단어를 읽을 때도 같은 셀
다만 매번 입력되는 값과 이전 hidden state가 달라진다.
중요한 점은 시간마다 다른 모델을 쓰는 것이 아니라, 같은 모델을 반복해서 쓴다는 점이다.
이 방식의 장점은 분명하다.
- 문장 길이가 달라도 같은 구조로 처리할 수 있다.
- 센서 데이터처럼 길이가 다른 시계열도 같은 방식으로 다룰 수 있다.
- 모델이 “이전 요약본을 이어받는다”는 구조를 자연스럽게 갖게 된다.
강의 자료에서 W_xh, W_hh, W_hy 같은 파라미터가 반복해서 보이는 이유도 여기에 있다.
W_xh: 입력에서 hidden state로 가는 가중치W_hh: 이전 hidden state에서 현재 hidden state로 가는 가중치W_hy: hidden state에서 출력으로 가는 가중치
이 세 가지를 계속 재사용하면서 시퀀스를 왼쪽에서 오른쪽으로 읽는 것이다.
4-1. 같은 가중치를 반복해서 쓴다는 뜻
RNN을 수학적으로 이해할 때 중요한 부분이 하나 더 있다.
바로 모든 시점에서 같은 가중치를 공유한다는 점이다.
예를 들어 문장이 다섯 단어라면 hidden state는 다섯 번 계산되지만, 아래 가중치는 매번 같다.
W_xhW_hhW_hy
이게 왜 중요하냐면, RNN이 “1번째 단어용 모델”, “2번째 단어용 모델”, “3번째 단어용 모델”을 따로 두지 않기 때문이다.
같은 규칙으로 반복 계산하니 길이가 다른 문장도 다룰 수 있고, 학습해야 할 파라미터 수도 과하게 늘어나지 않는다.
사람식으로 바꾸면, 문장을 읽을 때마다 매번 다른 두뇌를 쓰는 것이 아니라 같은 읽기 규칙을 계속 적용하는 것에 가깝다.
5. RNN은 어떤 문제에 쓰이는가
강의 자료 중간에서는 RNN이 문제 구조에 따라 어떻게 달라지는지 설명한다. 이 부분이 생각보다 중요하다. RNN은 “한 종류 모델”이라기보다, 순차 입력과 순차 출력을 다루는 여러 틀로 볼 수 있기 때문이다.
5-1. Many-to-One
여러 입력을 보고 마지막에 하나의 결과를 내는 구조다.
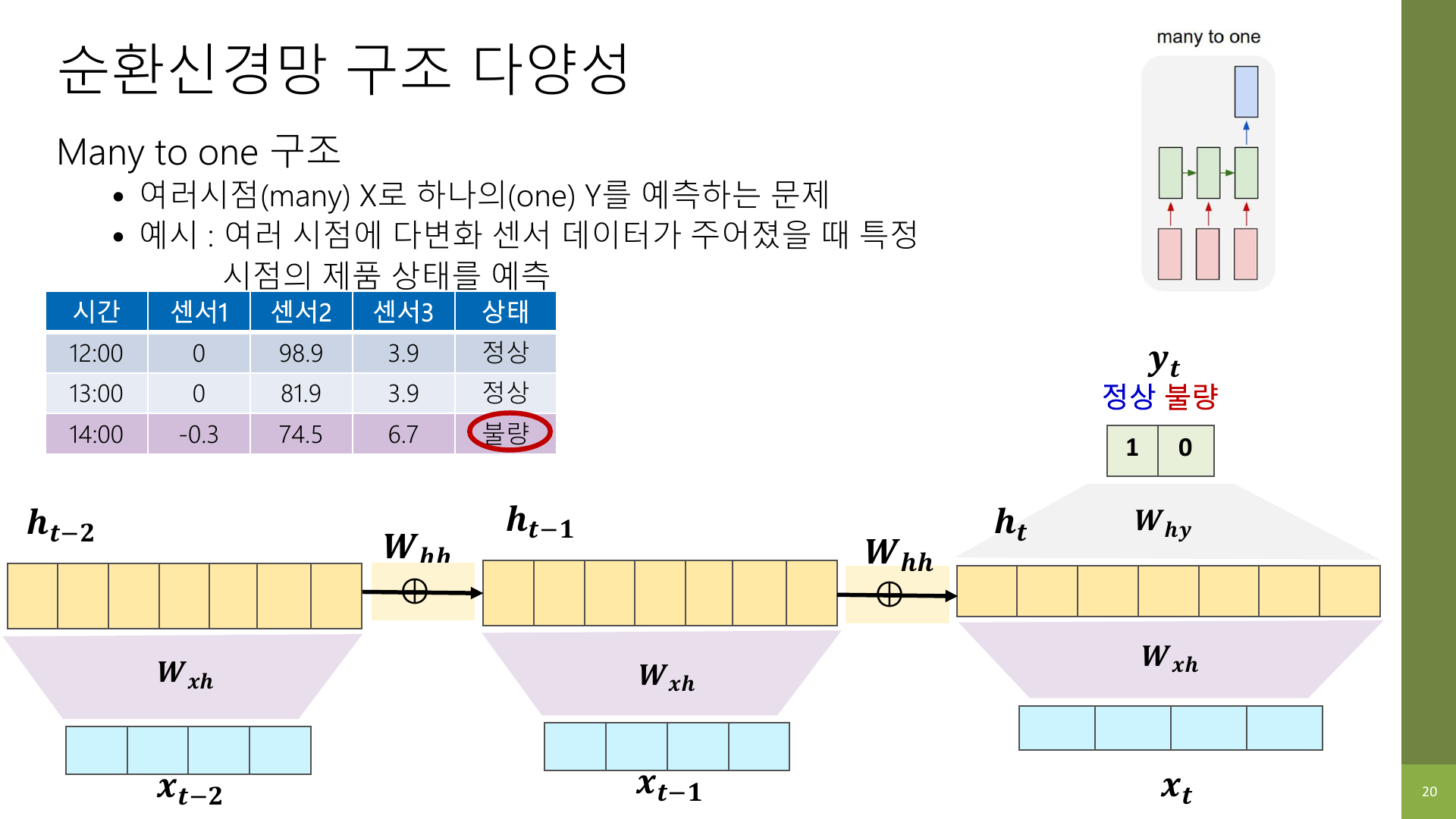
예시는 다음과 같다.
- 문장 전체를 읽고 감정 하나를 예측
- 여러 시간대 센서값을 보고 상태 하나를 예측
- 문장을 읽고 스팸/정상 하나를 예측
NLP에서는 감정 분석이 대표적이다.
"This movie was surprisingly good"전체를 읽고- 최종 출력으로
positive하나를 낸다.
즉, 입력은 여러 시점이고 출력은 하나다.
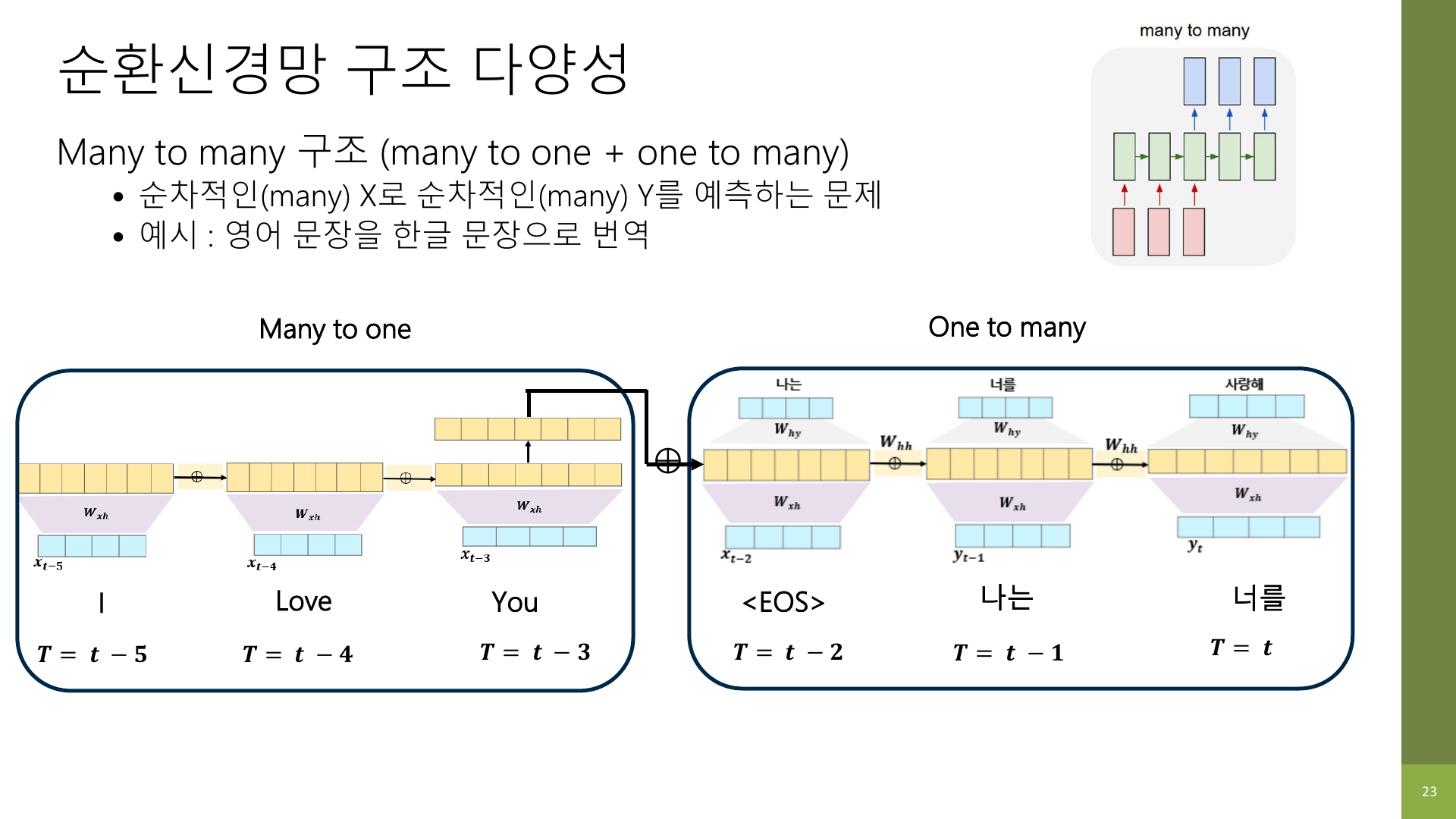
5-2. One-to-Many
입력 하나로 여러 출력을 순차적으로 만드는 구조다.
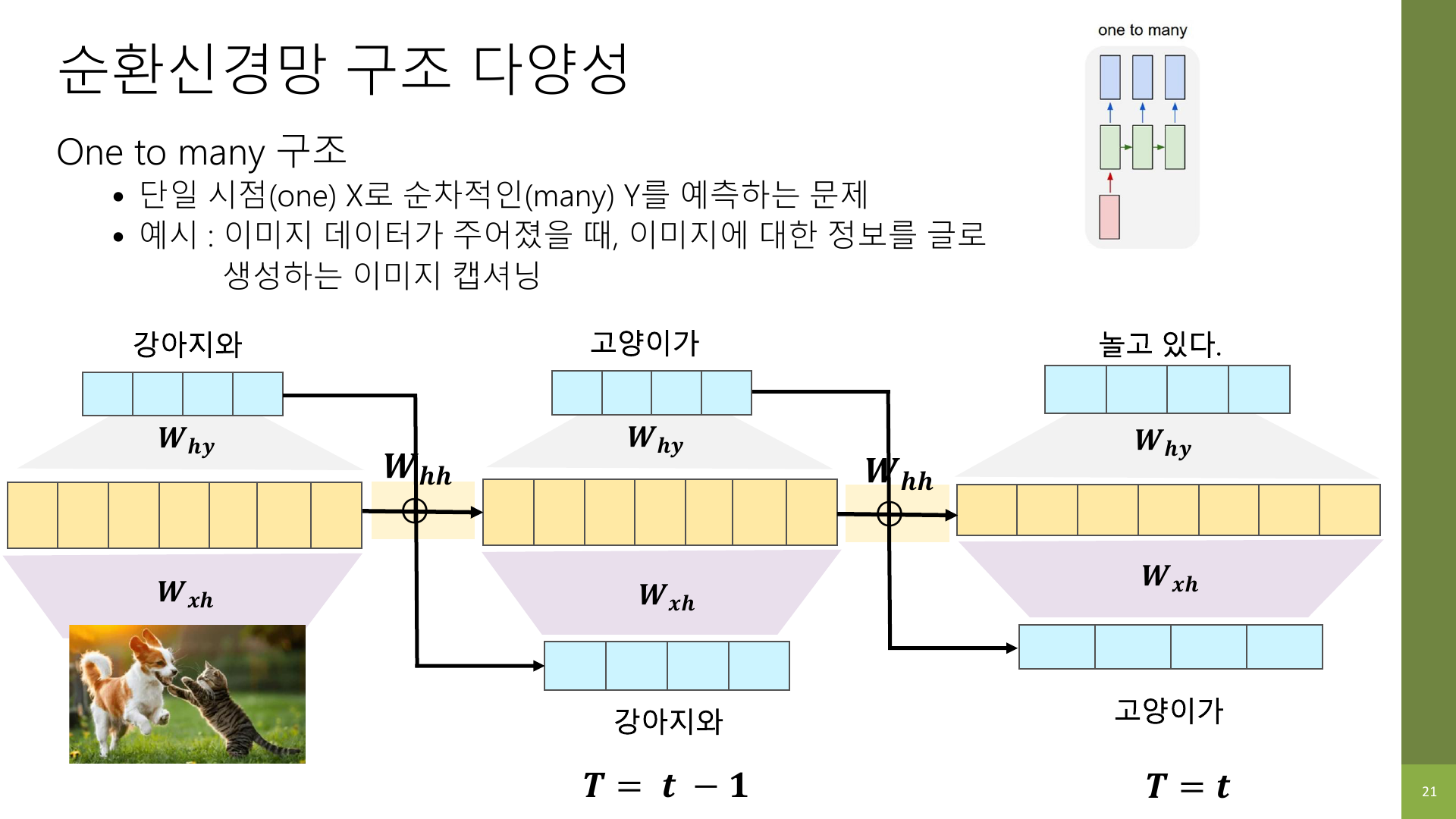
강의 자료에서는 이미지 캡셔닝 예시가 나온다.
이미지 한 장을 입력받고, "강아지와 고양이가 놀고 있다"처럼 여러 단어를 순서대로 생성하는 방식이다.
NLP 관점에서는 다음처럼 생각하면 된다.
- 시작 신호 하나를 넣고
- 단어를 하나 생성하고
- 그 다음 단어를 또 생성하고
- 문장이 끝날 때까지 반복
5-3. Many-to-Many
입력도 순차적이고 출력도 순차적인 구조다.
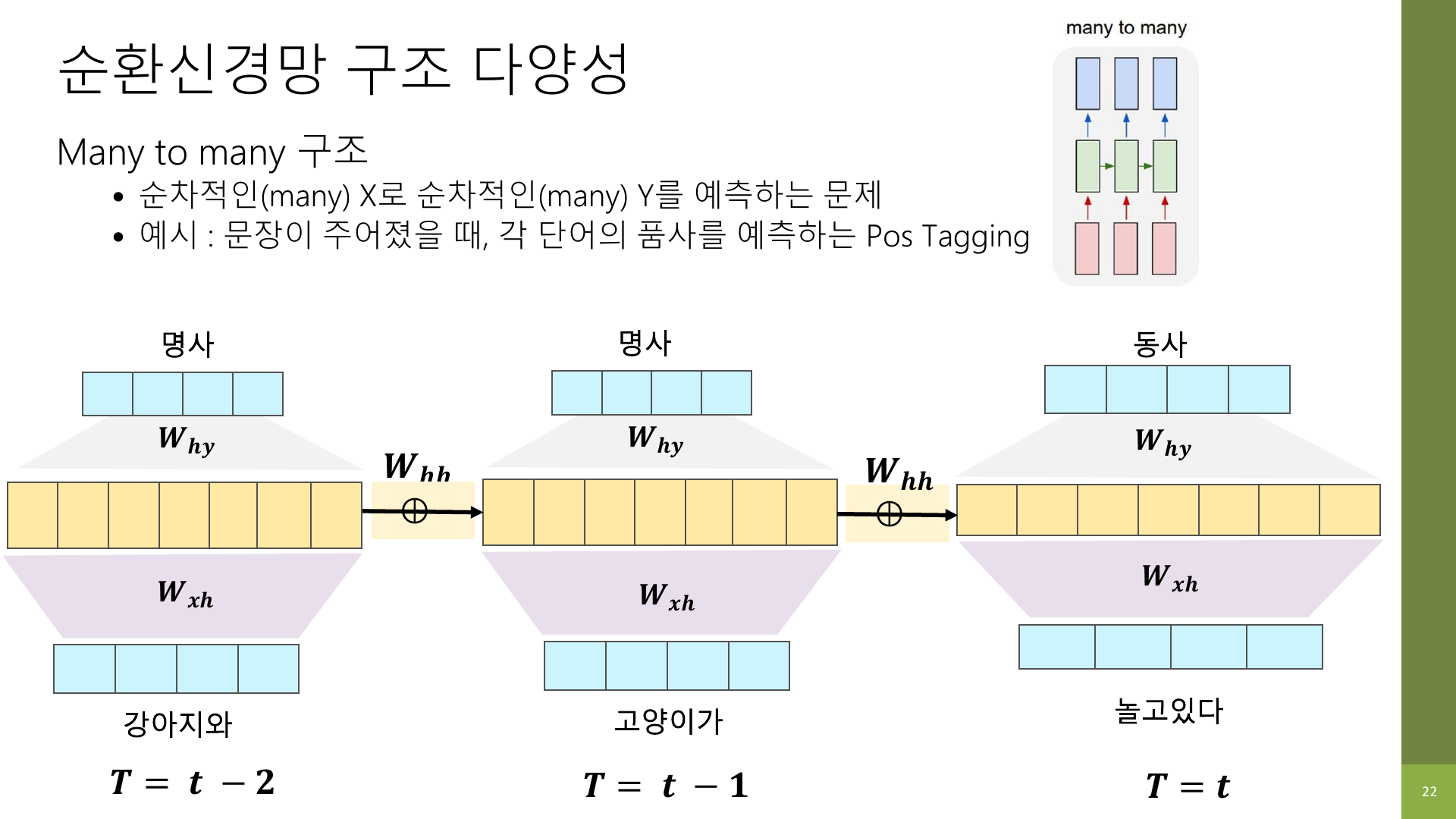
대표적인 예시는 품사 태깅이나 개체명 인식처럼, 입력 단어마다 대응되는 출력이 있는 작업이다.
- 입력:
I / love / Seoul - 출력:
대명사 / 동사 / 고유명사
또는 번역처럼 입력 시퀀스와 출력 시퀀스 모두 길이가 있는 작업도 여기서 발전한 구조로 볼 수 있다.
중요한 것은 모델 이름보다 문제의 입력과 출력이 시간축에서 어떻게 생겼는지 먼저 보는 것이다. 그래야 many-to-one인지, one-to-many인지, many-to-many인지 자연스럽게 구분된다.
6. RNN은 실제로 무엇을 기억하는가
이쯤에서 많이 생기는 오해가 있다. RNN이 이전 단어를 그대로 저장한다고 생각하기 쉽지만, 실제로는 그렇지 않다.
RNN이 넘기는 것은 원문 자체가 아니라 이전까지 읽은 내용을 압축한 hidden state다.
이걸 사람 식으로 바꾸면 아래와 비슷하다.
- 문장을 처음부터 끝까지 모두 외우는 것이 아니라
- “지금까지 읽어 보니 이런 흐름이다”라는 짧은 메모를 남긴다
- 다음 단어를 읽을 때 그 메모를 참고해서 메모를 다시 고친다
문제는 이 메모가 아주 완벽하지 않다는 점이다.
짧은 문장에서는 어느 정도 버티지만, 문장이 길어질수록 초반 정보가 흐려질 수 있다. 이게 뒤에서 나오는 RNN의 핵심 한계와 연결된다.
7. RNN은 어떻게 학습되는가
강의 자료 후반부는 학습 과정을 세 단계로 나눠 설명한다.
- Forward propagation
- Backward propagation
- Parameter update
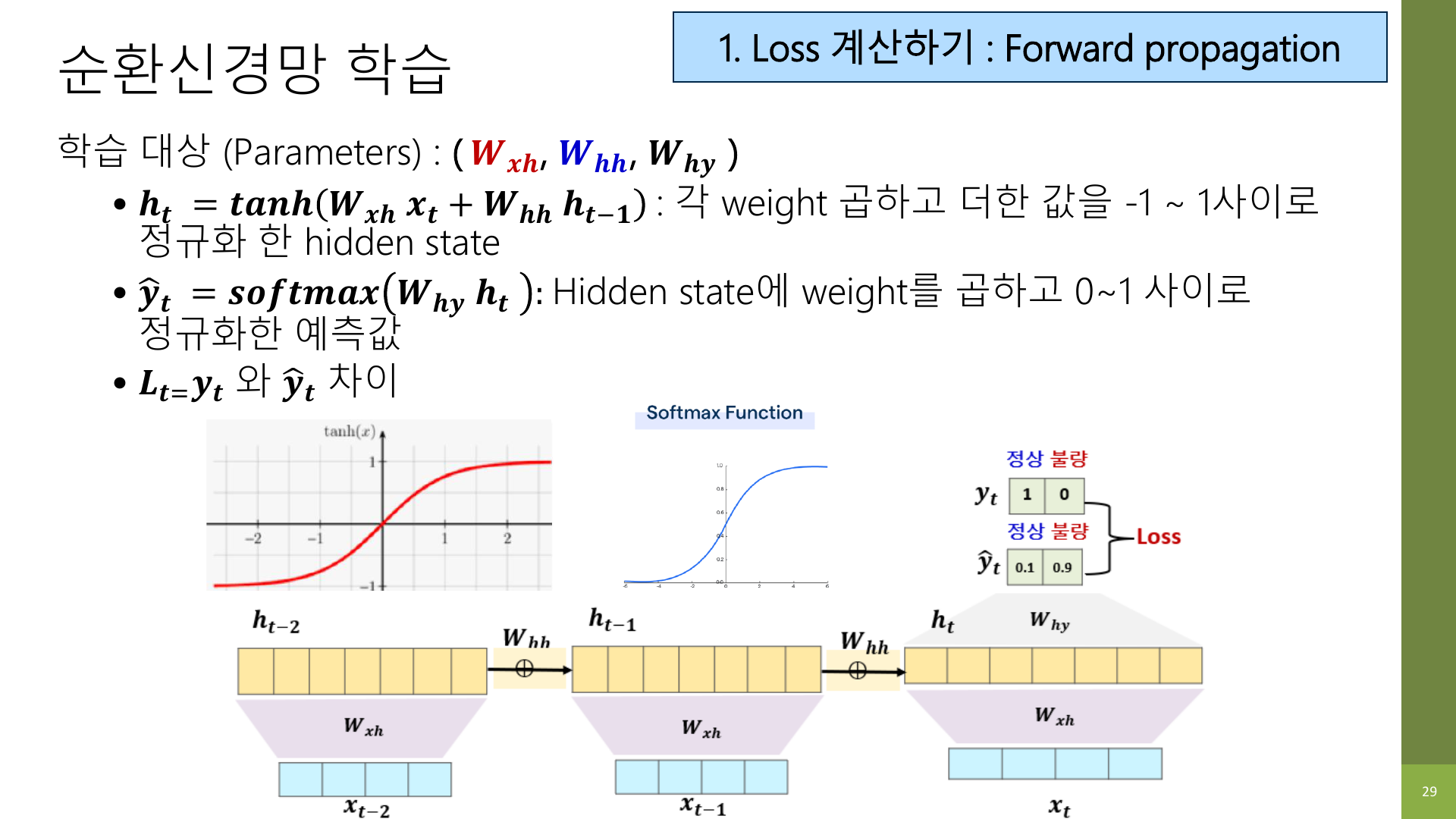
7-1. Forward propagation: 일단 예측해 본다
Forward propagation은 말 그대로 앞에서 뒤로 계산하는 단계다.
- 입력
x_t와 이전 hidden stateh_{t-1}를 이용해 현재 hidden stateh_t를 만든다. h_t로 현재 출력y_hat_t를 만든다.- 정답
y_t와 비교해서 얼마나 틀렸는지 loss를 계산한다.
수식이 복잡해 보여도 흐름은 익숙하다.
입력 받기 → 중간 표현 만들기 → 예측하기 → 정답과 비교하기many-to-one 구조라면 마지막 출력 하나만 보면 된다.
하지만 one-to-many나 many-to-many처럼 출력이 여러 시점에 있으면 각 시점의 loss를 계산한 뒤 평균이나 합으로 전체 loss를 만든다.
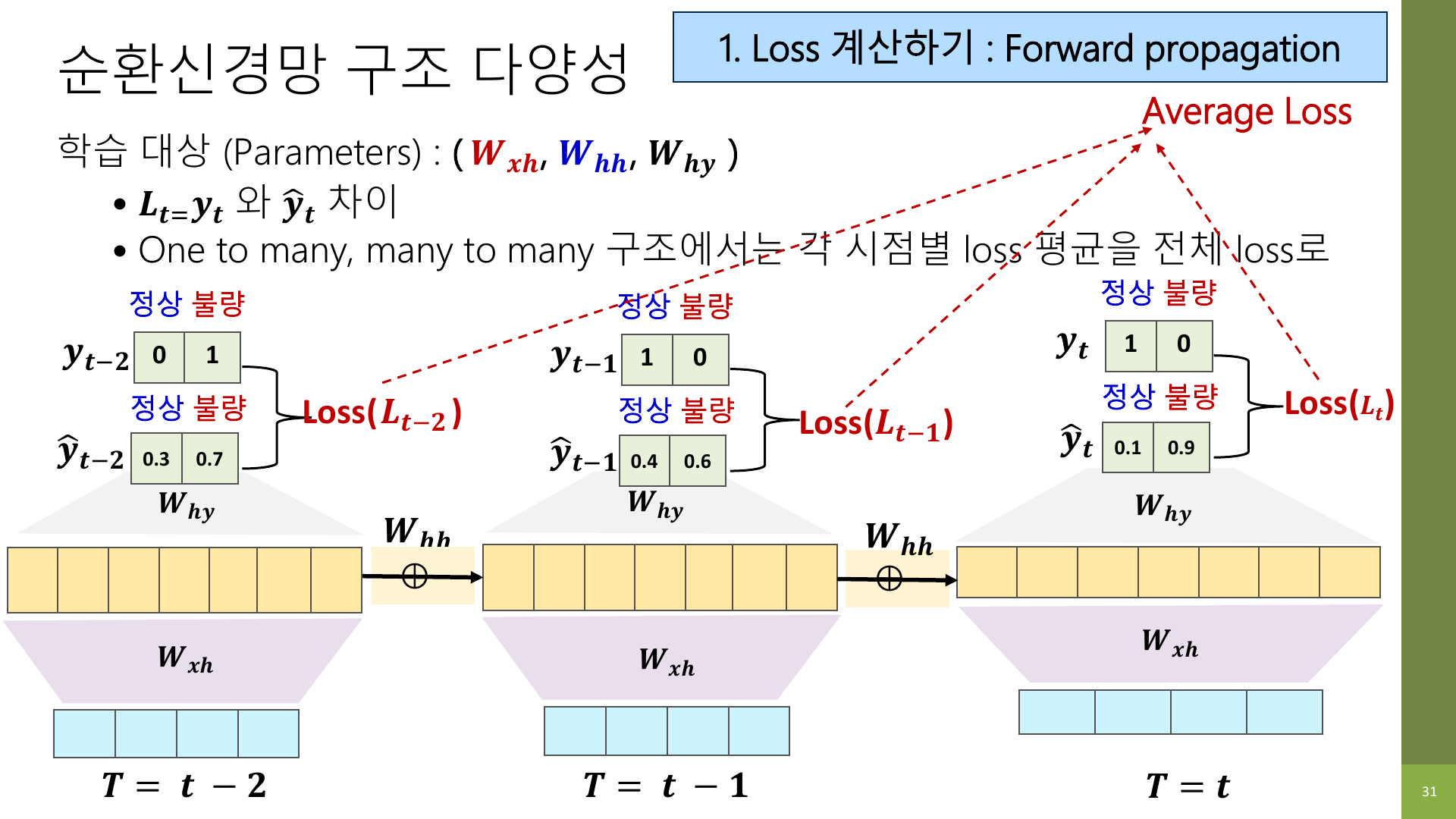
즉, RNN의 학습은 한 시점만 따로 보는 것이 아니라, 시퀀스 전체를 따라가며 생긴 오차를 같이 본다.
7-1-1. 선형결합이라는 말이 뜻하는 것
딥러닝 설명에서 자주 나오는 표현이 “선형결합”이다.
말이 어렵지만 실제로는 아래 뜻이다.
입력마다 중요도를 곱해서 더한다예를 들어 감정 분석에서 현재 단어가 "good"이라고 해 보자.
모델은 실제로 "good"이라는 글자를 그대로 계산하는 것이 아니라, 이 단어를 몇 개의 숫자 특징으로 바꿔서 본다.
이를테면 아주 단순화해서 아래처럼 생각할 수 있다.
x_t = [
긍정 느낌이 얼마나 강한가,
부정 표현과 자주 같이 나오는가,
문장에서 강조 표현으로 자주 쓰이는가
]예를 들어 "good"이라는 단어가 현재 시점에서 아래처럼 표현됐다고 해 보자.
x_t = [0.9, 0.1, 0.6]이 숫자는 아래 뜻이라고 보면 된다.
- 긍정 느낌은 강하다:
0.9 - 부정 표현과 같이 나올 가능성은 낮다:
0.1 - 강조 표현으로도 어느 정도 쓰인다:
0.6
그리고 모델이 현재 hidden state를 만들 때 각 특징을 얼마나 중요하게 볼지 정하는 가중치가 아래처럼 있다고 해 보자.
W_xh = [1.2, -0.8, 0.3]그러면 실제 계산은 아래처럼 된다.
0.9×1.2 + 0.1×(-0.8) + 0.6×0.3이 식을 말로 읽으면 이렇다.
- 긍정 느낌이 강하니 hidden state를 올리는 쪽으로 크게 반영하고
- 부정 표현과 같이 나오는 성향은 낮으니 거의 영향이 없고
- 강조 표현 성분은 조금 반영한다
즉, RNN 수식은 갑자기 새로운 마법을 쓰는 것이 아니라, 결국 “무엇을 더 중요하게 볼지 숫자로 정해서 합치는 과정”이다.
여기에 과거 hidden state까지 같은 방식으로 더해지는 것이다.
7-2. Backward propagation through time: 시간축을 거슬러 올라간다
이 부분이 슬라이드에서 가장 어렵게 보이는 구간이다. 이름도 길다.
BPTT(Backpropagation Through Time)는 그냥 이렇게 이해하면 된다.
마지막에 낸 오답의 책임이 어느 시점까지 거슬러 올라가는지 시간축 전체로 따지는 과정
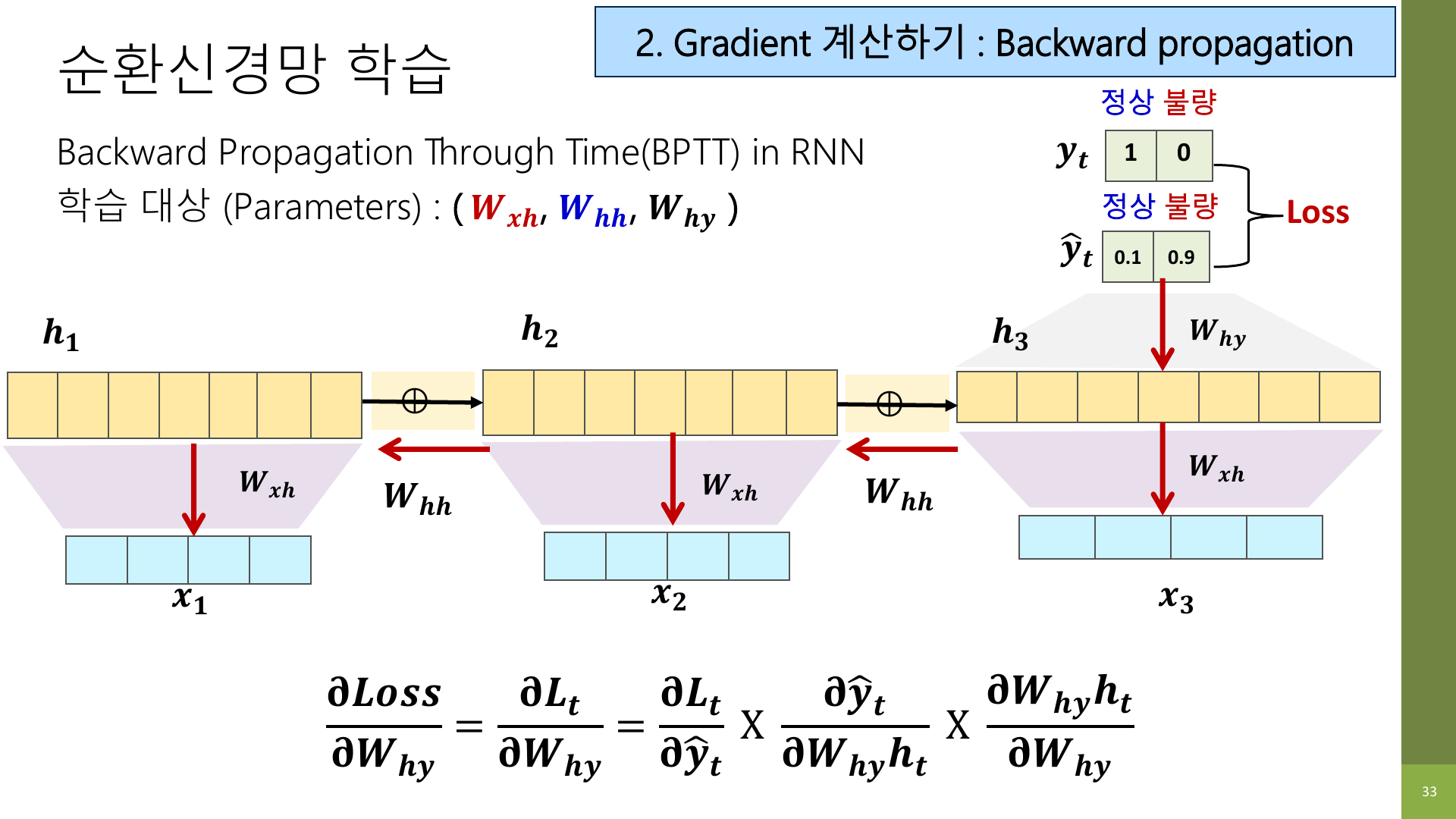
예를 들어 세 번째 단어에서 틀린 예측이 나왔다고 해 보자.
- 세 번째 시점의 hidden state가 직접 영향을 줬을 수 있다.
- 그런데 그 hidden state는 두 번째 시점의 hidden state 영향을 받았다.
- 두 번째 시점은 다시 첫 번째 시점의 hidden state 영향을 받았다.
즉, 마지막 실수의 원인을 뒤로 거슬러 올라가며 같이 계산해야 한다.
그래서 일반적인 신경망보다 gradient 계산이 더 길고 복잡해진다.
이걸 꼭 수학으로 다 따라갈 필요는 없다.
핵심은 **“RNN의 오차는 시간축을 따라 뒤로 전파된다”**는 점만 이해하면 된다.
7-2-1. 왜 시간이 길어질수록 gradient가 약해지는가
수학을 잘 모르는 입장에서는 여기서 가장 답답한 부분이 생긴다.
”왜 뒤로 전달된다는 건 알겠는데, 왜 점점 약해지는 거지?”라는 질문이다.
핵심은 계속 곱해지기 때문이다.
예를 들어 backward 과정에서 어떤 영향력이 매 시점마다 0.8배씩 줄어든다고 가정해 보자.
- 한 번 지나면
0.8 - 두 번 지나면
0.8 × 0.8 = 0.64 - 다섯 번 지나면
0.8^5 ≈ 0.33 - 열 번 지나면
0.8^10 ≈ 0.11
이렇게 반복해서 곱해지면 처음에는 꽤 크던 값도 빠르게 작아진다.
반대로 1보다 큰 값이 반복해서 곱해지면 너무 커질 수도 있다. 이게 기울기 폭주다.
즉, RNN의 수학적 어려움은 식이 복잡해서라기보다,
같은 계산이 시간축에서 반복되고 그 영향이 계속 곱으로 이어진다는 데 있다.
그래서 짧은 문장은 어떻게든 버텨도, 긴 문장에서는 초반 정보에 대한 학습 신호가 약해지기 쉽다.
7-3. Parameter update: 조금씩 수정한다
gradient를 계산하고 나면, 각 가중치를 loss가 줄어드는 방향으로 조금씩 수정한다.
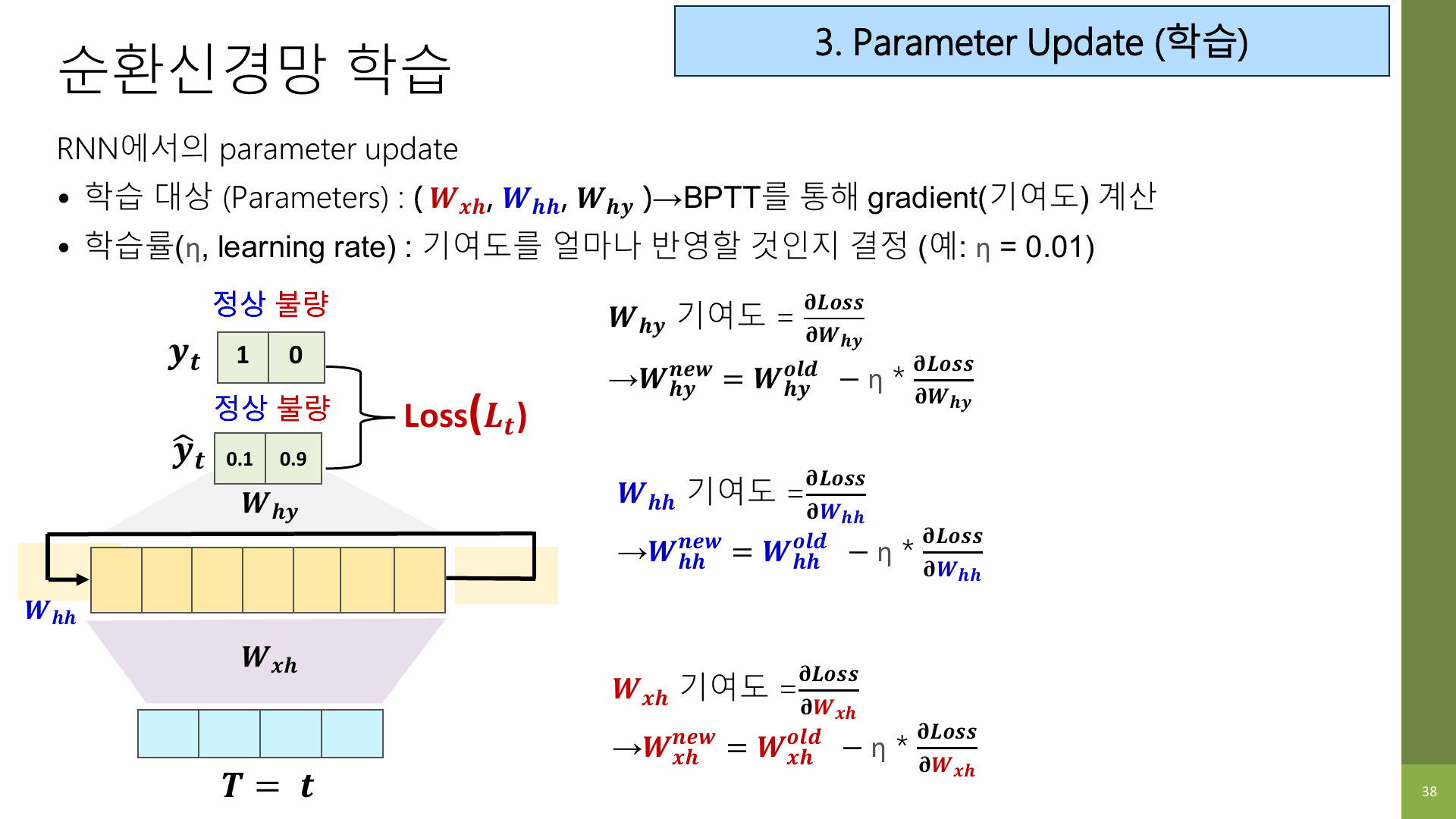
이 단계는 일반 딥러닝과 크게 다르지 않다.
- 틀린 정도를 본다.
- 각 파라미터가 그 실수에 얼마나 기여했는지 본다.
- 기여도가 큰 쪽을 더 조정한다.
즉, W_xh, W_hh, W_hy가 조금씩 바뀌면서 “이전 정보를 어떻게 기억하고 현재 예측에 섞을지”를 점점 더 잘 배우게 된다.
8. RNN의 가장 큰 한계: 긴 문장을 잘 못 버틴다
강의 자료 마지막 부분은 RNN의 핵심 한계를 설명한다. 바로 장기 의존성 문제(long-term dependency problem) 다.

말은 어렵지만 뜻은 간단하다.
- 문장이 짧으면 초반 정보가 뒤까지 어느 정도 전달된다.
- 문장이 길어질수록 앞쪽 정보가 점점 흐려진다.
- 결국 아주 먼 과거 정보는 현재 예측에 제대로 반영되지 못한다.
예를 들어 아래처럼 문장이 길어졌다고 생각해 보자.
The movie that I watched with my friends last weekend at a small theater near the station was not good.
이 문장에서 뒤쪽의 good을 해석할 때는 앞의 not이 중요하다.
그런데 단어 수가 아주 길어지면, RNN은 초반의 not 정보를 끝까지 강하게 유지하기 어려워진다.
강의 자료에서는 그 원인을 기울기 소실(vanishing gradient) 로 설명한다.

수학을 깊게 보지 않더라도, 직관은 이렇게 잡으면 충분하다.
- backward 단계에서 오차 신호가 과거로 계속 전달된다.
- 그런데 전달될 때마다 값이 조금씩 작아질 수 있다.
- 시점이 10개, 50개, 100개로 길어지면 초반까지 갈 때는 거의 0처럼 약해질 수 있다.
- 그러면 모델이 “아주 먼 과거가 중요했다”는 사실을 제대로 배우지 못한다.
즉, RNN은 구조 자체는 자연스럽지만, 긴 시퀀스를 다룰수록 학습이 어려워진다. 이 한계를 해결하려고 나온 것이 바로 LSTM과 GRU다.
8-1. 수학적으로 봤을 때 RNN에서 꼭 잡아야 하는 핵심
RNN의 수학을 전부 계산하지 않아도, 아래 네 가지만 이해하면 상당히 많이 따라온 것이다.
h_t는 현재 입력과 직전 기억을 섞어 만든 새 메모다.W_xh,W_hh,W_hy는 무엇을 얼마나 반영할지 정하는 가중치다.tanh는 값이 너무 커지지 않게 눌러 주는 함수다.- BPTT에서는 오차가 시간축을 따라 뒤로 전달되며, 이때 곱이 반복되기 때문에 기울기 소실이나 폭주가 생길 수 있다.
즉, RNN의 수학은 완전히 새로운 세계라기보다, “현재와 과거를 가중치로 섞고, 그 오차를 다시 시간축으로 되돌려 보낸다”는 구조를 식으로 적어 놓은 것이다.
9. 여기까지 이해하면 충분한 것
RNN 파트를 처음 볼 때는 식 때문에 막히기 쉽다. 하지만 실제로는 아래 내용을 이해하면 다음 단계로 넘어갈 준비가 된 것이다.
9-1. RNN은 왜 필요한가
일반 신경망은 현재 입력만 보기 쉽다.
하지만 자연어와 시계열은 이전 정보가 중요하다.
그래서 RNN은 이전 hidden state를 현재 계산에 함께 넣는다.
9-2. RNN은 무엇을 넘기나
이전 원문을 통째로 넘기는 것이 아니라, 이전까지의 정보를 요약한 hidden state를 넘긴다.
9-3. RNN은 어디에 쓰이나
- many-to-one: 감정 분석, 시계열 분류
- one-to-many: 문장 생성, 이미지 캡셔닝
- many-to-many: 품사 태깅, 번역 같은 시퀀스 작업
9-4. RNN은 왜 한계가 있나
문장이 길어질수록 먼 과거 정보를 학습하기 어렵다.
원인은 backward 단계에서 오차 신호가 약해지는 기울기 소실 문제다.
마무리
RNN은 “이전 정보를 현재에 연결한다”는 점에서 자연어 처리와 시계열 분석의 출발점 같은 모델이다. 구조 자체는 직관적이다. 한 시점씩 읽고, 이전 내용을 hidden state에 담아 다음 시점으로 넘긴다. 그래서 처음 순차 데이터용 신경망을 배울 때 RNN이 기준점이 된다.
다만 실제로 긴 문장을 다뤄 보면, 초반 정보를 끝까지 잘 기억하지 못하는 문제가 생긴다. 강의 자료 39~41페이지가 바로 그 약점을 설명하는 부분이었다. 그래서 다음 글에서는 RNN의 이 약점을 보완하려고 나온 LSTM을 이어서 정리할 예정이다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.