RNN 다음에 LSTM을 보면 “기억을 더 잘하게 만든 구조”라는 느낌이 든다. 그런데 LSTM까지 이해하고 나면 또 다른 질문이 생긴다.
”좋은 건 알겠는데, 구조가 너무 복잡한 것 아닌가?”
GRU는 바로 이 지점에서 나온 모델이다. 강의 자료에서도 GRU를 LSTM 구조를 간단하게 개선하여 파라미터 개수를 줄인 모델로 설명한다.
이번 글에서는 강의 자료 64~67페이지를 기준으로, GRU를 아래 네 가지 중심으로 정리해 보려고 한다.
- GRU는 왜 나왔는가
- LSTM과 무엇이 다른가
- reset gate와 update gate는 각각 무슨 역할을 하는가
- GRU를 언제 더 편하게 쓸 수 있는가
1. GRU는 왜 나왔는가
LSTM은 RNN의 장기 의존성 문제를 완화한 구조였지만, 그만큼 내부가 복잡해졌다.
- cell state가 따로 있다
- hidden state가 따로 있다
- forget gate, input gate, output gate 세 개를 계산한다
즉, 기억을 잘 관리하도록 만든 대신 계산해야 할 것도 많아졌다.
강의 자료 64페이지는 이 차이를 아주 직접적으로 보여 준다.
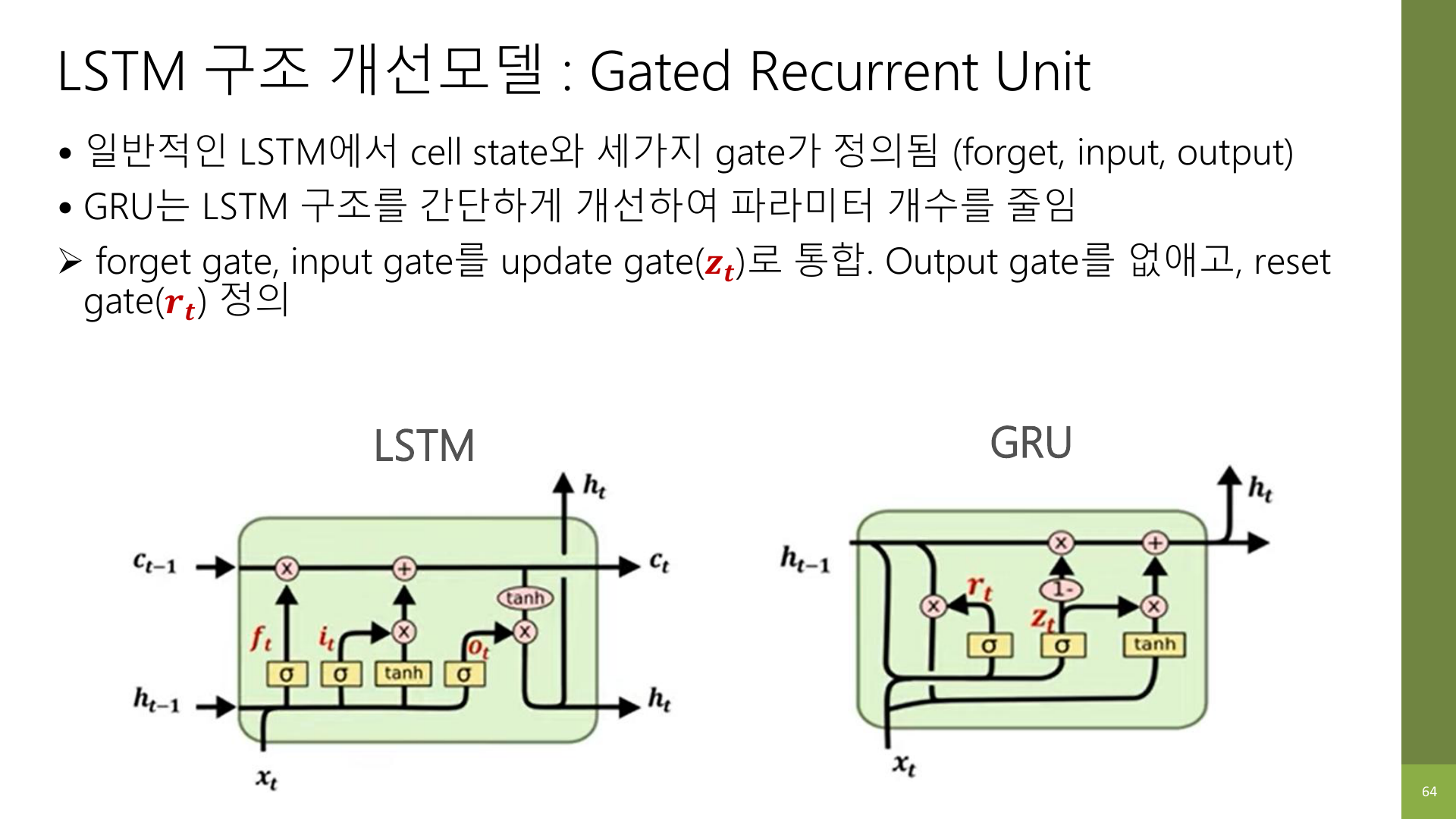
GRU의 방향은 분명하다.
LSTM이 하던 기억 관리를 유지하되, 구조는 더 단순하게 만들자.
즉, GRU는 “LSTM의 아이디어를 유지한 경량화 버전”이라고 이해하면 가장 자연스럽다.
2. GRU가 LSTM과 다른 가장 큰 점
강의 자료의 설명을 그대로 정리하면 GRU는 세 가지를 한다.
- forget gate와 input gate를
update gate하나로 합친다 - output gate를 없앤다
- cell state와 hidden state를 하나로 통합한다
이 세 줄이 GRU의 핵심이다.
LSTM을 다시 떠올려 보면:
- 오래 들고 갈 메모: cell state
- 지금 출력에 쓸 메모: hidden state
- 버릴지/넣을지/보여줄지: gate 3개
GRU는 이걸 훨씬 단순하게 바꾼다.
- 메모 통로를 하나로 줄인다
- gate도 2개만 둔다
즉, LSTM이 “기억 관리가 아주 세분화된 모델”이라면, GRU는 “덜 복잡하게 비슷한 효과를 노리는 모델”에 가깝다.
3. GRU의 두 gate를 먼저 큰 그림으로 보기
GRU에는 두 개의 gate가 나온다.
reset gate (r_t)update gate (z_t)
강의 자료 65페이지와 66페이지는 이 두 gate를 순서대로 설명한다.
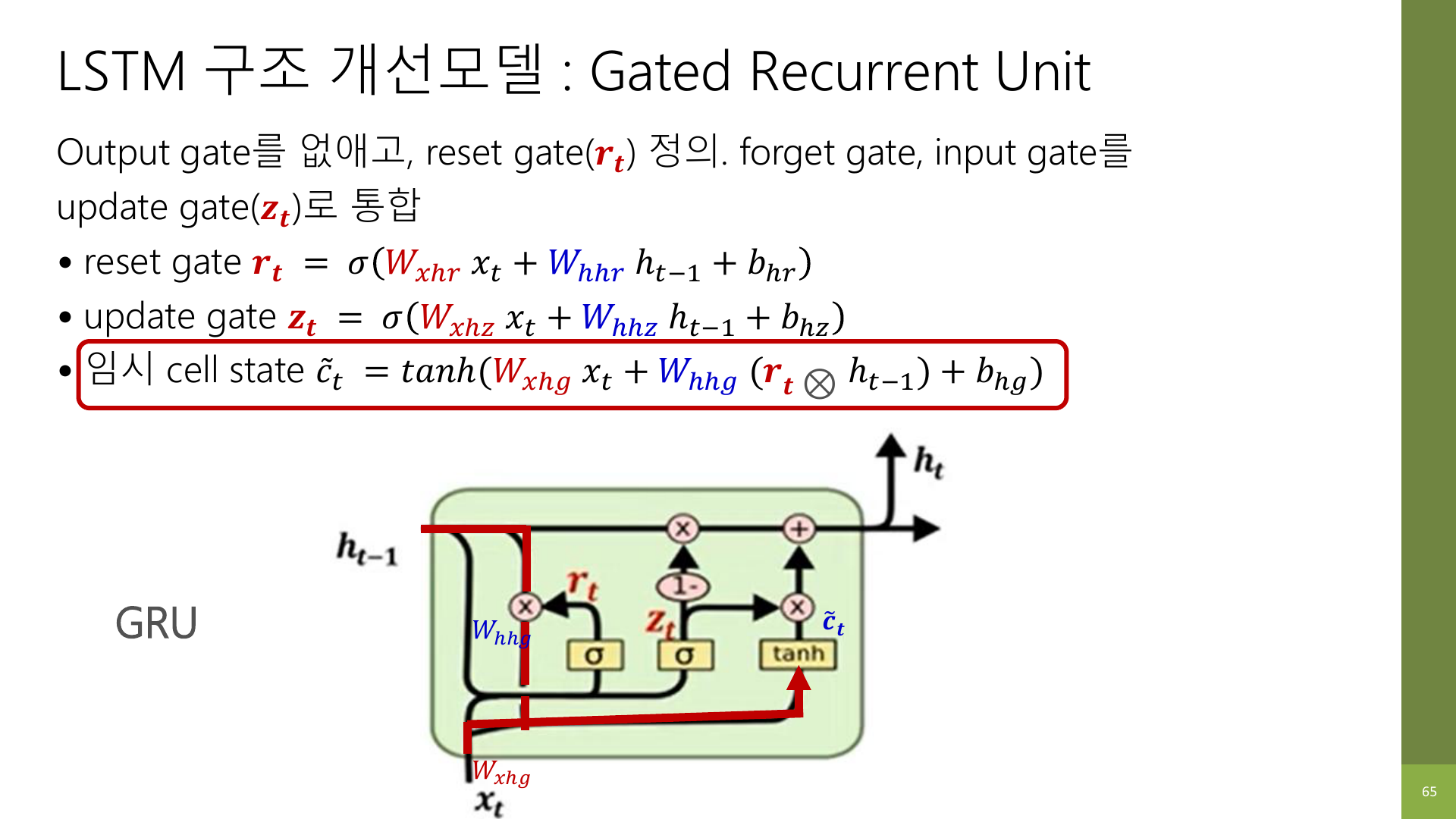
아직 수식은 몰라도 된다. 역할만 먼저 보면 아래처럼 정리된다.
3-1. Reset gate
이전 hidden state를 현재 후보 상태를 만들 때 얼마나 참고할지 정한다.
3-2. Update gate
이전 hidden state를 얼마나 유지하고, 새 후보 상태를 얼마나 반영할지 정한다.
즉, GRU는 두 가지 질문만 한다고 보면 된다.
- 과거를 지금 계산에 얼마나 섞을까?
- 최종 메모를 갱신할 때 과거와 현재를 어느 비율로 섞을까?
이 두 질문만으로도 LSTM이 하던 기억 관리의 상당 부분을 대신하려는 것이다.
3-3. GRU 식을 한 문장으로 읽는 법
GRU 수식은 LSTM보다 적지만, 처음 보면 오히려 더 압축돼 보여서 낯설 수 있다.
하지만 아래처럼 읽으면 구조가 단순하게 보인다.

reset gate: 과거를 지금 계산에 얼마나 섞을까
update gate: 예전 메모를 얼마나 유지하고 새 메모로 얼마나 바꿀까
candidate hidden state: 지금 입력을 바탕으로 새 메모 후보를 만들자
final hidden state: 예전 메모와 새 메모 후보를 섞자즉, GRU는 “기억을 지우고 넣고 꺼내는 세 단계”를 따로 두는 대신,
과거를 얼마나 참고할지와 최종적으로 얼마나 갱신할지를 두 개의 gate로 압축한 구조라고 보면 된다.
4. Reset gate는 무슨 역할을 하는가
reset gate는 이름 그대로, 과거 정보를 얼마나 초기화해서 볼지 정하는 게이트다.
직관적으로 말하면:
- 값이 크면: 이전 정보를 많이 참고한다
- 값이 작으면: 이전 정보를 덜 참고한다
즉, reset gate는 현재 시점의 후보 정보를 만들 때 “과거를 얼마나 끌고 올지”를 조절한다.
예를 들어 문맥이 갑자기 전환되는 상황을 생각해 보자.
I was talking about the weather. Now let me review the movie.
이럴 때는 뒤쪽에서 새 문맥을 해석할 때 앞 문맥을 강하게 끌고 오지 않는 편이 더 나을 수 있다. reset gate는 이런 경우에 과거 영향을 줄이는 쪽으로 작동할 수 있다.
다르게 말하면, reset gate는 현재를 계산할 때 과거를 얼마나 지운 상태로 볼지 정하는 장치다.
4-1. reset gate 식은 어떻게 읽으면 되는가
reset gate는 보통 아래처럼 적는다.
r_t = sigmoid(W_r · [h_{t-1}, x_t] + b_r)이 식에서 중요한 것은 sigmoid와 입력 구성이다.
sigmoid는 값을 0과 1 사이로 만들어 준다h_{t-1}와x_t를 같이 보는 것은 과거와 현재를 함께 참고해서 판단하겠다는 뜻이다
즉, reset gate는 “지금 들어온 입력을 과거 문맥까지 고려해서 봤을 때, 이전 메모를 얼마나 끌고 와야 하는가”를 숫자로 정한다.
여기서 r_t가 작아지면, 과거 hidden state의 영향은 줄어든다.
반대로 r_t가 커지면, 후보 상태를 만들 때 과거 정보가 더 많이 반영된다.
5. Update gate는 사실 GRU의 핵심이다
update gate는 GRU에서 가장 중요한 gate다.
강의 자료 67페이지는 이 gate가 LSTM의 forget gate와 input gate 역할을 함께 한다고 설명한다.
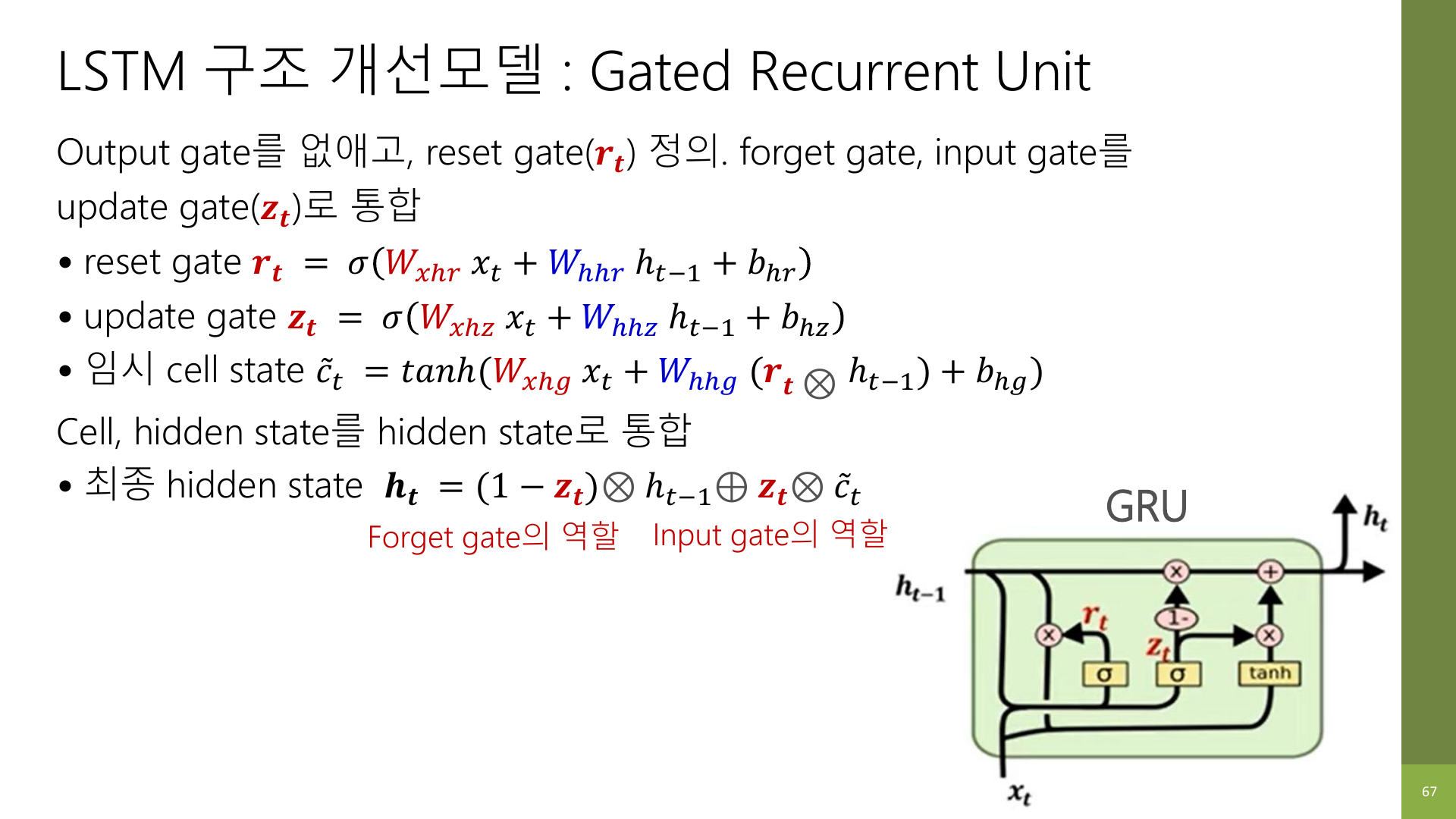
이걸 직관적으로 바꾸면 다음과 같다.
- update gate 값이 작으면: 예전 hidden state를 더 유지한다
- update gate 값이 크면: 새 후보 상태를 더 많이 반영한다
즉, update gate는 아래 둘을 한 번에 결정한다.
- 예전 기억을 얼마나 남길까
- 새 기억으로 얼마나 바꿀까
그래서 LSTM에서는
- forget gate로 과거를 줄이고
- input gate로 새 정보를 넣었다면
GRU에서는 그 판단을 update gate 하나가 더 간단하게 맡는다.
5-1. update gate 식은 왜 중요한가
update gate는 보통 아래처럼 쓴다.
z_t = sigmoid(W_z · [h_{t-1}, x_t] + b_z)이 식만 보면 reset gate와 비슷해 보인다.
실제로 형태는 비슷하다. 차이는 역할이다.
reset gate는 후보 메모를 만들 때 과거를 얼마나 참고할지 정하고,
update gate는 최종 hidden state를 만들 때 예전 메모와 새 메모 후보를 어느 비율로 섞을지 정한다.
즉, update gate는 GRU 전체에서 가장 핵심적인 결정권을 가진다.
z_t가 작으면 예전 hidden state를 더 많이 유지한다z_t가 크면 새 후보 hidden state를 더 많이 반영한다
LSTM의 forget gate와 input gate를 하나로 합쳤다는 말은, 결국 이 update gate 하나가 “과거를 얼마만큼 남길지”와 “현재를 얼마만큼 받아들일지”를 동시에 조절한다는 뜻이다.
6. GRU에는 왜 cell state가 없을까
이 부분이 처음 보면 가장 낯설 수 있다. LSTM에서는 cell state가 핵심이었는데, GRU는 그걸 따로 두지 않는다.
강의 자료 표현을 그대로 따르면:
Cell, hidden state를 hidden state로 통합
즉, GRU는 “장기 메모리용 통로”와 “현재 출력용 통로”를 분리하지 않고, 하나의 hidden state 안에서 같이 다루려는 구조다.
이 말은 곧 장점과 trade-off가 같이 있다는 뜻이다.
장점
- 구조가 더 단순하다
- 파라미터 수가 줄어든다
- 계산량이 상대적으로 적다
trade-off
- LSTM처럼 역할이 세밀하게 분리되어 있지는 않다
- 따라서 문제에 따라서는 LSTM이 더 안정적일 수도 있다
즉, GRU는 “LSTM보다 무조건 우수한 모델”이라기보다,
덜 복잡한 구조로 비슷한 목적을 이루려는 모델이다.
6-1. hidden state 하나만으로 버틸 수 있는 이유
이 지점에서 자연스럽게 이런 의문이 생긴다.
LSTM은 cell state를 따로 둬야 기억이 잘 된다고 했는데, GRU는 왜 hidden state 하나만으로도 괜찮을까?
GRU의 생각은 이렇다.
- 메모 통로를 두 개로 나누지 않더라도
- gate가 충분히 잘 조절해 주면
- hidden state 하나 안에서도 과거 유지와 현재 반영을 동시에 할 수 있다
즉, 구조를 단순하게 만드는 대신 update gate가 훨씬 중요한 역할을 맡는다.
그래서 GRU를 이해할 때는 “메모 통로가 하나다”보다,
“그 하나의 메모를 gate로 얼마나 잘 갱신하느냐”가 더 중요하다.
7. GRU 계산을 사람 말로 바꾸면
수식을 다 보지 않아도 GRU는 아래처럼 이해할 수 있다.
7-1. 먼저 과거를 얼마나 참고할지 본다
reset gate가 이전 hidden state를 현재 후보 상태 계산에 얼마나 섞을지 정한다.
7-2. 현재 후보 메모를 만든다
현재 입력과 조절된 과거 정보를 합쳐서 “이번 시점의 새 메모 후보”를 만든다.
7-3. 예전 메모와 새 메모를 섞는다
update gate가 예전 hidden state를 얼마나 유지하고, 새 후보 상태를 얼마나 반영할지 정한다.
즉, 최종 hidden state는 아래처럼 이해하면 된다.
새 hidden state
= 예전 메모 일부
+ 새 메모 후보 일부이 구조만 이해해도 GRU의 핵심은 거의 다 이해한 셈이다.
7-4. 후보 hidden state는 어떻게 만들어지는가
GRU 식에서는 보통 후보 hidden state를 아래처럼 쓴다.
\tilde{h_t} = tanh(W_h · [r_t * h_{t-1}, x_t] + b_h)이 식을 말로 바꾸면:
- 이전 hidden state에 reset gate를 먼저 적용한다
- 그 값을 현재 입력과 함께 합친다
- 새 메모 후보를 만든다
즉, 후보 hidden state는 “과거를 어느 정도 정리한 뒤 현재와 합쳐서 만든 새 메모 초안”이라고 보면 된다.
여기서 tanh가 나오는 이유는 RNN, LSTM과 비슷하다.
- 값이 너무 커지지 않게 정리하고
- 양수/음수 방향의 정보를 함께 담기 쉽게 만들기 위해서다
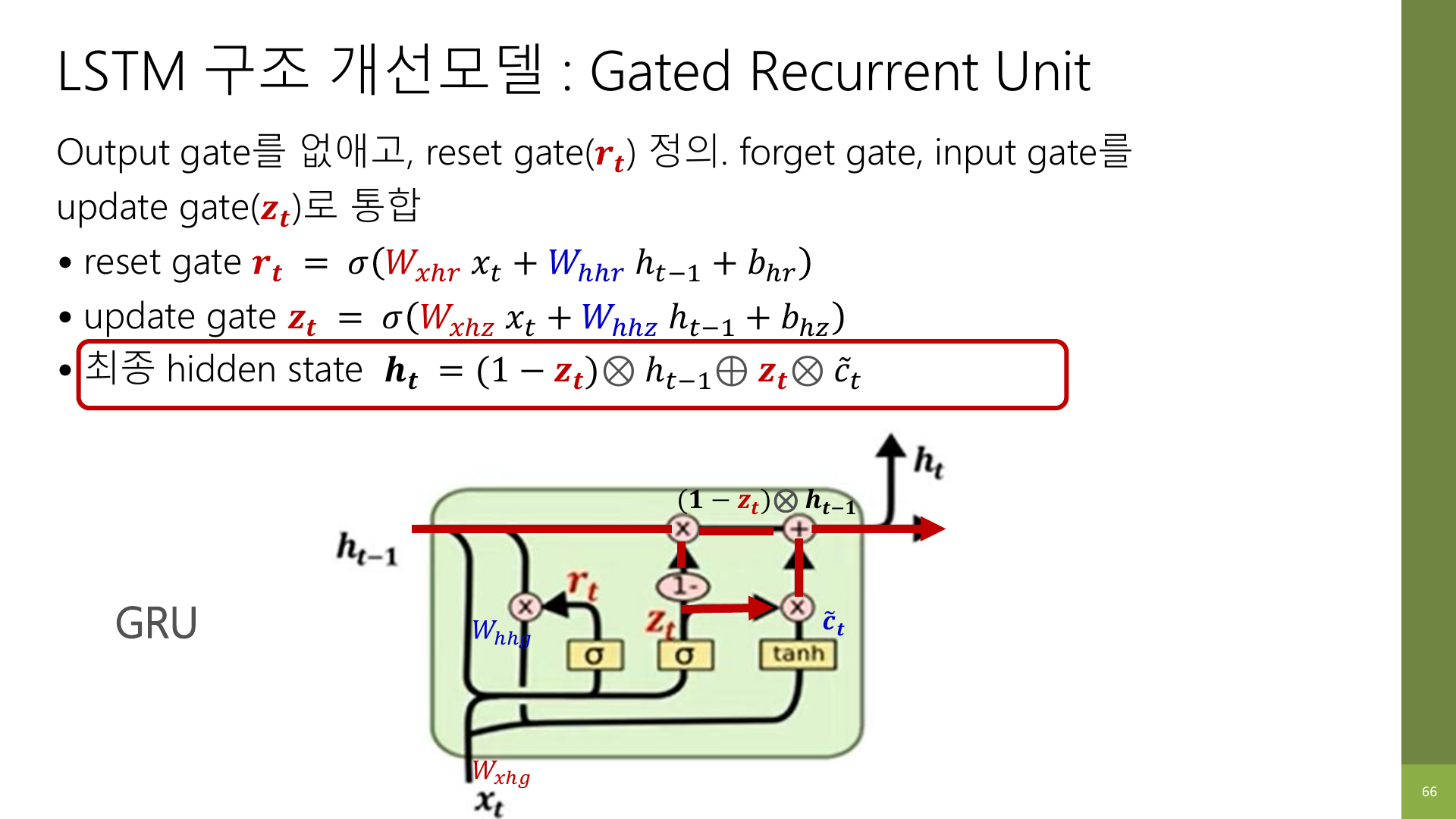
7-5. 최종 hidden state 업데이트 식의 의미
GRU의 핵심 식은 보통 아래처럼 적는다.
h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h_t}이 식은 정말 중요하다.
왜냐하면 GRU가 LSTM 없이도 기억을 관리하는 방식이 그대로 들어 있기 때문이다.
뜻은 단순하다.
- 예전 메모
h_{t-1}를 일부 유지하고 - 새 메모 후보
\tilde{h_t}를 일부 반영해서 - 최종 메모
h_t를 만든다
즉, GRU는 기억을 “덮어쓰기”보다 “비율을 섞어서 갱신하기”에 가깝다.
문장으로 바꾸면 이런 느낌이다.
"The movie looked boring at first"까지 읽은 상태에서는 “지루할 것 같다”는 메모가 꽤 강하게 남아 있다- 그런데 뒤에
"but it was actually fun"이 나오면 update gate는 새 문맥을 더 많이 반영해야 한다고 판단할 수 있다 - 반대로 그냥 덧붙이는 설명만 나오면 예전 메모를 더 많이 유지할 수 있다
즉, update gate는 숫자 하나라기보다 “지금 이 단어가 들어왔을 때 기존 해석을 유지할지, 새로 바꿀지”를 정하는 비율이라고 보면 된다.
8. LSTM과 GRU를 비교해서 보면 더 쉬워진다
8-1. LSTM
- cell state 따로 있음
- hidden state 따로 있음
- gate 3개
- 기억 관리가 더 세분화됨
8-2. GRU
- cell state 따로 없음
- hidden state 하나로 통합
- gate 2개
- 구조가 더 단순함
즉, LSTM은 세밀하고, GRU는 간결하다.
8-3. 어떤 쪽이 더 좋다고 단정할 수 있을까
실제로는 문제와 데이터에 따라 다르다.
- 데이터가 충분하고 긴 의존성이 특히 중요하면 LSTM을 먼저 떠올릴 수 있다
- 더 단순한 구조와 빠른 학습이 필요하면 GRU가 편할 수 있다
실무에서는 둘 다 돌려 보고 더 잘 맞는 쪽을 선택하는 경우도 많다.
즉, GRU는 이론적으로만 배우는 구조가 아니라 실제로 자주 비교되는 대안이다.
8-4. 수학적으로 보면 GRU가 간단한 이유
LSTM은 cell state와 hidden state를 나누고, gate도 세 개를 둔다.
반면 GRU는 hidden state 하나와 gate 두 개만 둔다.
그래서 수식 관점에서도 차이가 난다.
- 계산해야 할 게이트 수가 적다
- 별도의 cell state 업데이트 식이 없다
- 최종 hidden state 식 하나에 기억 유지와 갱신이 같이 들어 있다
즉, GRU는 수학적으로도 “같은 목적을 더 적은 구성으로 풀어낸 모델”이라고 볼 수 있다.
9. GRU를 자연어 예시로 다시 생각해 보기
예를 들어 문장을 읽는다고 해 보자.
I thought the movie would be boring, but it was actually fun.
이 문장에서 뒤쪽 fun을 해석할 때는 중간의 but 이후 문맥이 중요하다.
GRU는 이때
- reset gate로 과거 문맥을 얼마나 다시 참고할지 조절하고
- update gate로 예전 메모를 유지할지, 새 문맥 중심으로 바꿀지 조절한다
즉, LSTM처럼 복잡하게 메모장을 두 칸으로 나누지는 않았지만,
여전히 “기억을 선택적으로 바꾸는” 발상은 유지하고 있다.
10. 강의 자료 기준으로 꼭 남겨야 할 핵심
강의 자료 64~67페이지를 한 문장씩 줄이면 아래처럼 정리할 수 있다.
10-1. GRU는 LSTM을 단순화한 모델이다
파라미터 수를 줄이고 구조를 간단하게 하려는 목적이 있다.
10-2. reset gate가 있다
현재 후보 상태를 만들 때 과거 정보를 얼마나 참고할지 조절한다.
10-3. update gate가 있다
예전 hidden state와 새 후보 상태를 어떤 비율로 섞을지 정한다.
10-4. cell state와 hidden state를 따로 나누지 않는다
하나의 hidden state 안에서 기억 갱신과 출력 역할을 함께 처리한다.
10-5. 수학적으로 꼭 잡아야 하는 핵심
GRU 수학을 전부 계산하지 않아도, 아래 다섯 줄이 이해되면 충분하다.
sigmoid는 gate 값을 0~1 사이로 만들어 정보 반영 비율을 조절한다.- reset gate는 후보 메모를 만들 때 과거를 얼마나 참고할지 정한다.
- update gate는 예전 메모와 새 메모 후보를 어떤 비율로 섞을지 정한다.
- 후보 hidden state는 “현재 입력 + 조절된 과거”로 만든 새 메모 초안이다.
- 최종 hidden state는 예전 메모와 새 메모 후보를 가중합해서 만든다.
마무리
GRU는 LSTM을 배운 다음 보면 오히려 이해가 쉬운 편이다. “gate를 줄였고, 메모 통로도 하나로 합쳤다”는 방향이 분명하기 때문이다. 그래서 GRU는 LSTM의 대체재라기보다, 비슷한 목적을 더 단순한 구조로 풀어낸 모델이라고 보는 편이 맞다.
정리하면, RNN은 이전 정보를 넘기는 기본 구조였고, LSTM은 그 기억 관리를 더 정교하게 만든 모델이었다. GRU는 그 정교함을 조금 덜어내고 더 간단하게 만든 버전이다. 다음 글에서는 같은 날짜로 Transformer를 정리하면서, 왜 결국 RNN 계열에서 Attention 기반 구조로 넘어가게 됐는지 이어서 정리할 예정이다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.