RNN을 이해하고 나면 자연스럽게 다음 질문이 생긴다.
”이전 정보를 넘긴다는 건 알겠는데, 왜 RNN은 긴 문장만 가면 자꾸 약해질까?”
LSTM은 바로 그 문제를 줄이기 위해 나온 구조다. 강의 자료에서는 LSTM을 “장기 의존성 문제를 완화한 RNN 개선 모델”이라고 설명한다.
이번 글에서는 강의 자료 42~63페이지를 기준으로, LSTM을 수식보다 역할 중심으로 다시 정리해 보려고 한다. 핵심은 아래 네 가지다.
- LSTM이 왜 필요한가
- cell state와 hidden state는 무엇이 다른가
- forget, input, output gate는 각각 무슨 일을 하는가
- LSTM이 RNN보다 긴 문장에서 왜 더 유리한가
1. RNN 다음에 바로 LSTM이 나온 이유
RNN 글 마지막에서 봤듯이, RNN은 구조는 자연스럽지만 긴 시퀀스를 학습할수록 초반 정보를 잘 유지하지 못한다. 강의 자료 42페이지는 먼저 그 문제를 완화하는 한 가지 실무적 방법으로 Truncated BPTT를 언급한다.
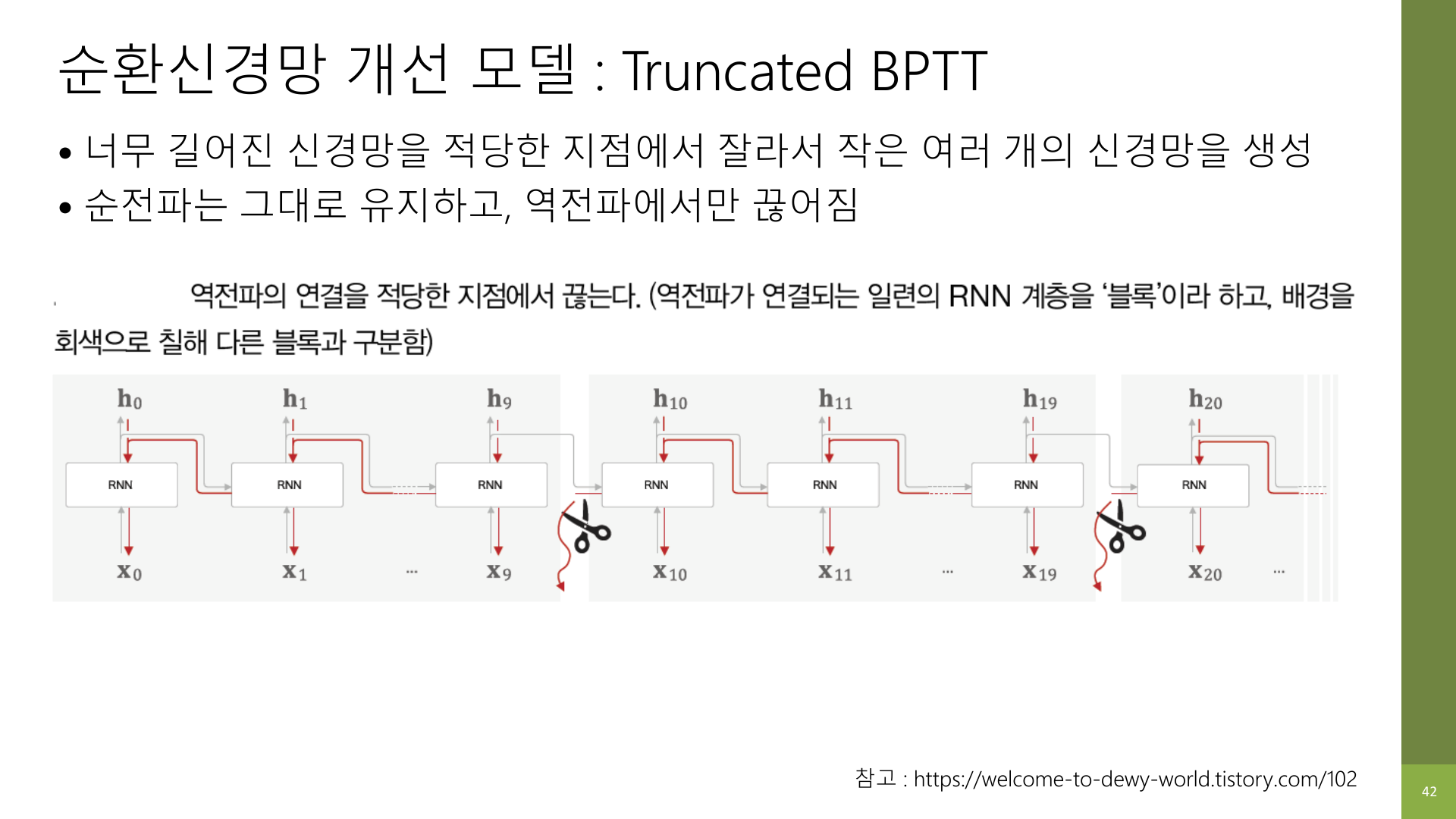
이 방식은 아주 긴 시퀀스를 적당히 끊어서 역전파를 짧게 하는 방법이다.
즉, 너무 긴 시간축 전체를 한 번에 학습하지 않고 구간을 나눠 처리한다.
다만 이 방법은 근본적으로 기억 구조를 바꾸는 것은 아니다.
그래서 등장한 것이 LSTM이다.
2. LSTM은 RNN에 무엇을 추가했는가
강의 자료에서는 LSTM을 설명하면서 두 가지를 강조한다.
cell state (c_t)구조를 제안했다.- 세 가지 gate를 추가했다.
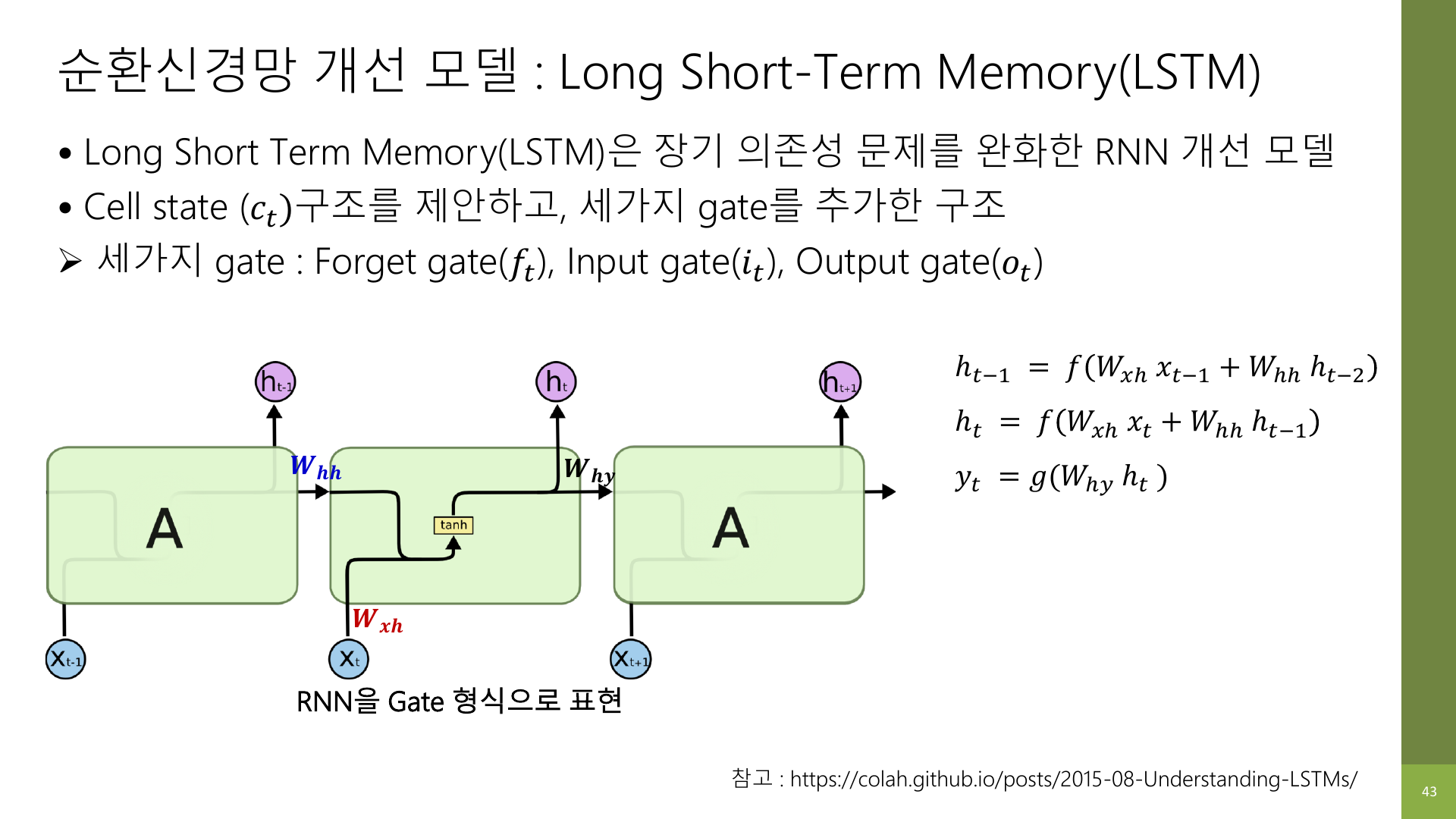
RNN을 간단히 말하면 이랬다.
이전 hidden state + 현재 입력 → 현재 hidden stateLSTM은 여기에 “기억 전용 통로”를 하나 더 둔다.
이전 hidden state + 현재 입력 → gate 계산
이전 cell state와 새 후보 정보 → 현재 cell state
현재 cell state → 현재 hidden state즉, LSTM은 RNN처럼 단순히 메모를 하나만 넘기는 방식이 아니라,
- 오래 들고 갈 기억용 통로
- 지금 바로 출력에 쓸 정보용 통로
를 구분한 구조라고 이해하면 훨씬 쉽다.
3. cell state와 hidden state를 따로 두는 이유
이 부분이 LSTM에서 가장 중요하다. 강의 자료 45페이지는 cell state와 hidden state를 분리해서 설명한다.
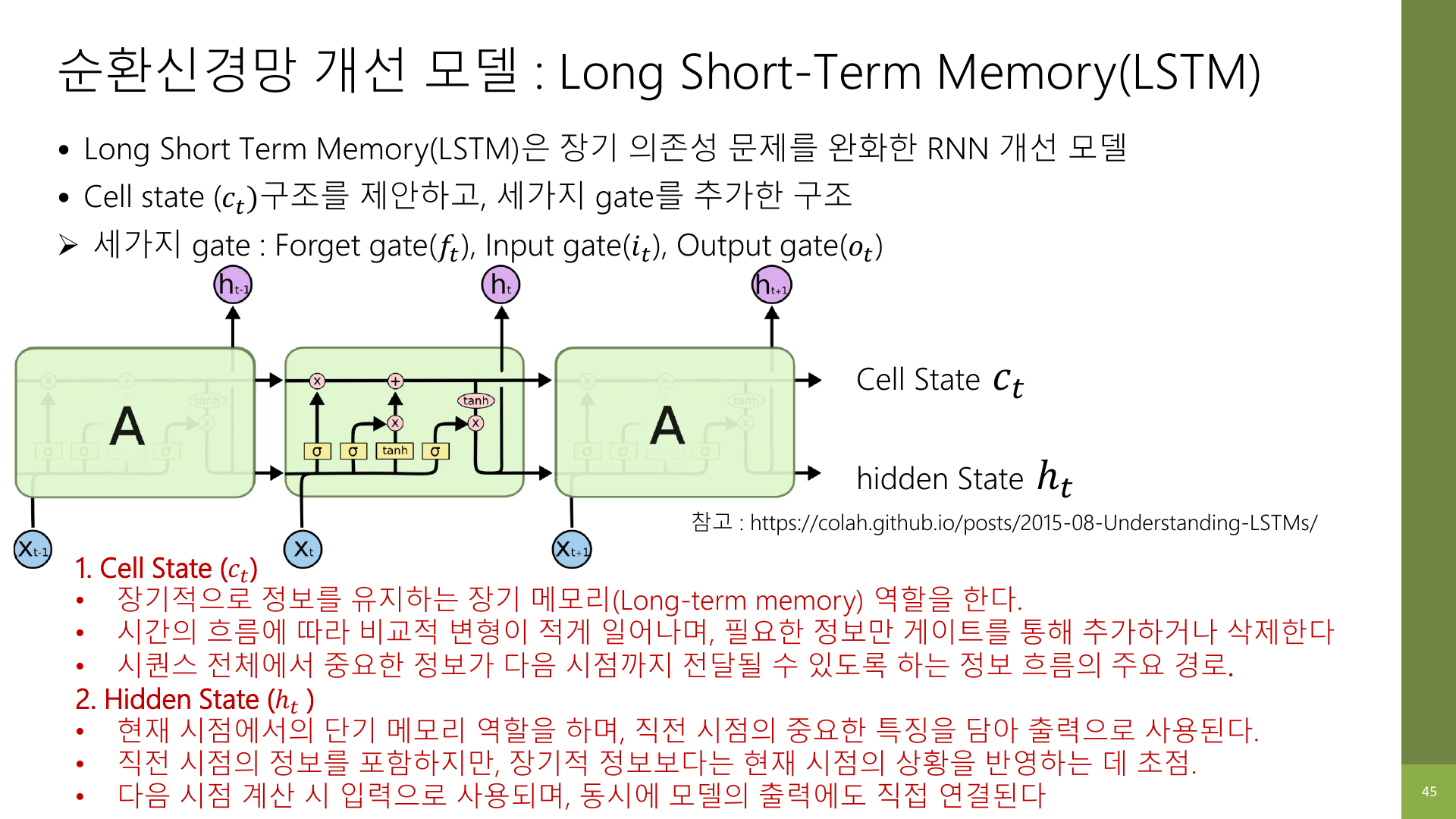
3-1. Cell state는 장기 메모리
강의 자료 표현대로 보면 cell state는 장기적으로 정보를 유지하는 통로다.
- 시퀀스 전체에서 중요한 정보를 오래 유지하려고 한다.
- 필요 없는 것은 지우고, 필요한 것만 추가한다.
- 시간축을 따라 비교적 안정적으로 흐른다.
사람으로 비유하면 이런 느낌이다.
- 수업을 들으면서 핵심 개념만 노트에 남겨 두는 것
- 세부 문장 하나하나보다 “이건 중요한 내용”이라는 요약을 계속 들고 가는 것
3-2. Hidden state는 현재 시점 요약
hidden state는 현재 시점에서 바로 쓸 요약 정보다.
- 지금 순간의 상태를 반영한다.
- 출력 계산에 직접 연결된다.
- 다음 시점 계산에도 들어간다.
즉, LSTM은 기억을 두 층으로 나눈다고 보면 된다.
cell state: 오래 가져갈 메모hidden state: 지금 바로 꺼내 쓸 메모
RNN이 메모 하나만 쓰는 구조였다면, LSTM은 메모장을 두 칸으로 나눈 셈이다.
4. LSTM의 전체 흐름을 먼저 한 번 보기
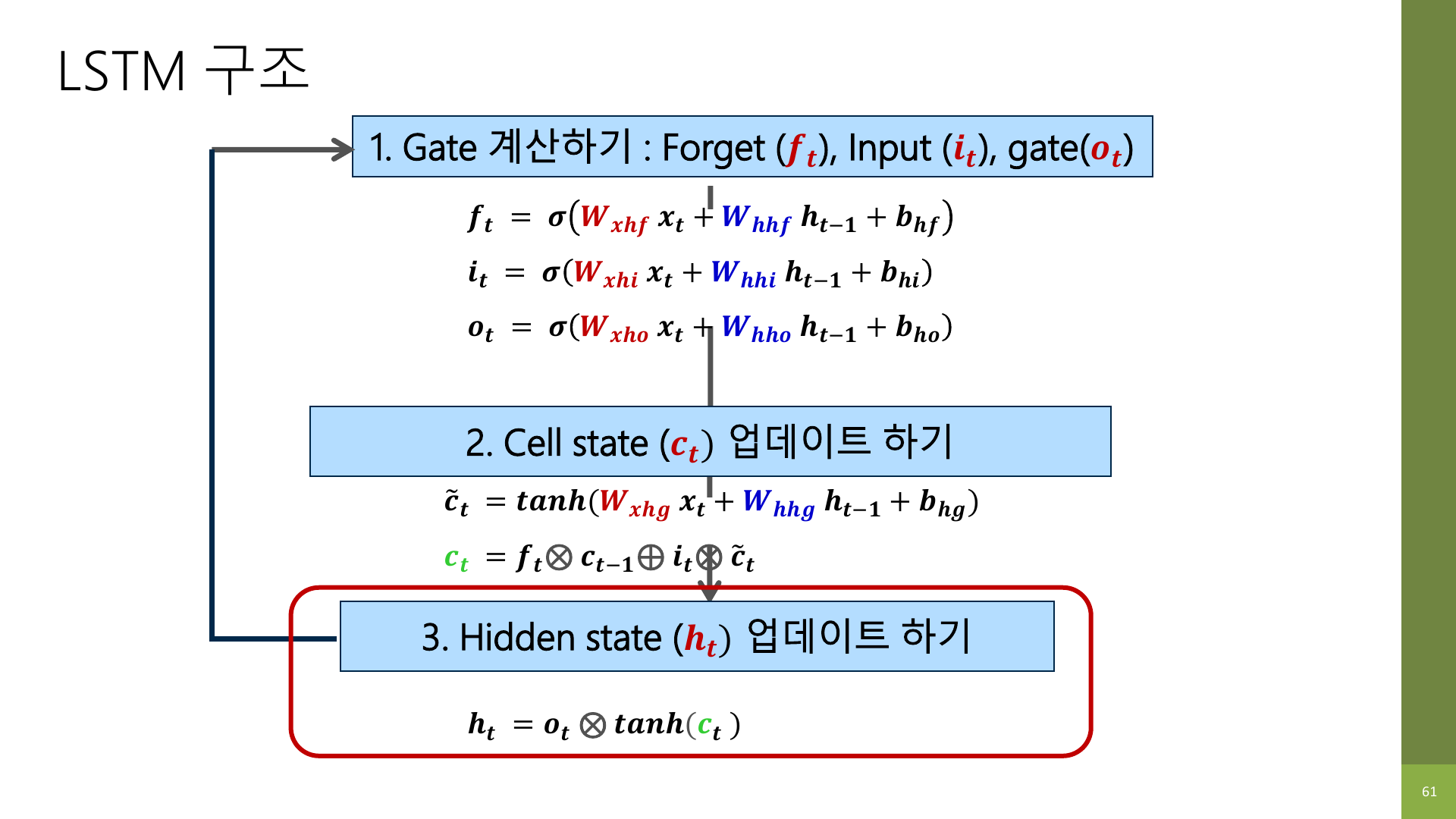
강의 자료는 LSTM 계산을 세 단계로 정리한다.

- gate 계산하기
- cell state 업데이트하기
- hidden state 업데이트하기
이걸 먼저 큰 흐름으로 이해하면 수식이 훨씬 덜 부담스럽다.
4-1. gate 계산
현재 입력 x_t와 이전 hidden state h_{t-1}를 보고 세 개의 gate 값을 만든다.
- forget gate
f_t - input gate
i_t - output gate
o_t
4-2. cell state 업데이트
이전 cell state에서 무엇을 남길지 결정하고,
현재 입력에서 새로 기억할 후보 정보를 더해서
새로운 cell state를 만든다.
4-3. hidden state 업데이트
업데이트된 cell state 중에서 지금 출력으로 꺼낼 부분만 골라 hidden state를 만든다.
즉, LSTM은 아무 정보나 무조건 기억하는 것이 아니라,
- 버릴 것
- 새로 넣을 것
- 밖으로 꺼낼 것
을 따로 관리한다.
4-4. LSTM 식을 한 문장으로 읽는 법
LSTM을 처음 볼 때 가장 부담스러운 부분은 식이 여러 개로 쪼개져 있다는 점이다.
하지만 아래처럼 읽으면 생각보다 단순하다.

forget gate: 과거를 얼마나 남길까
input gate: 새 정보를 얼마나 넣을까
candidate: 지금 들어온 정보로 어떤 새 메모를 만들까
cell state: 남길 과거 + 새로 넣을 현재
output gate: 지금 무엇을 밖으로 보여 줄까즉, LSTM 식은 복잡한 계산 여러 개가 아니라,
기억을 관리하는 질문을 단계별로 식으로 쓴 것이라고 보면 된다.
5. Gate는 무엇인가
강의 자료 51페이지는 gate를 0~1 사이 값을 가지는 벡터라고 설명한다.
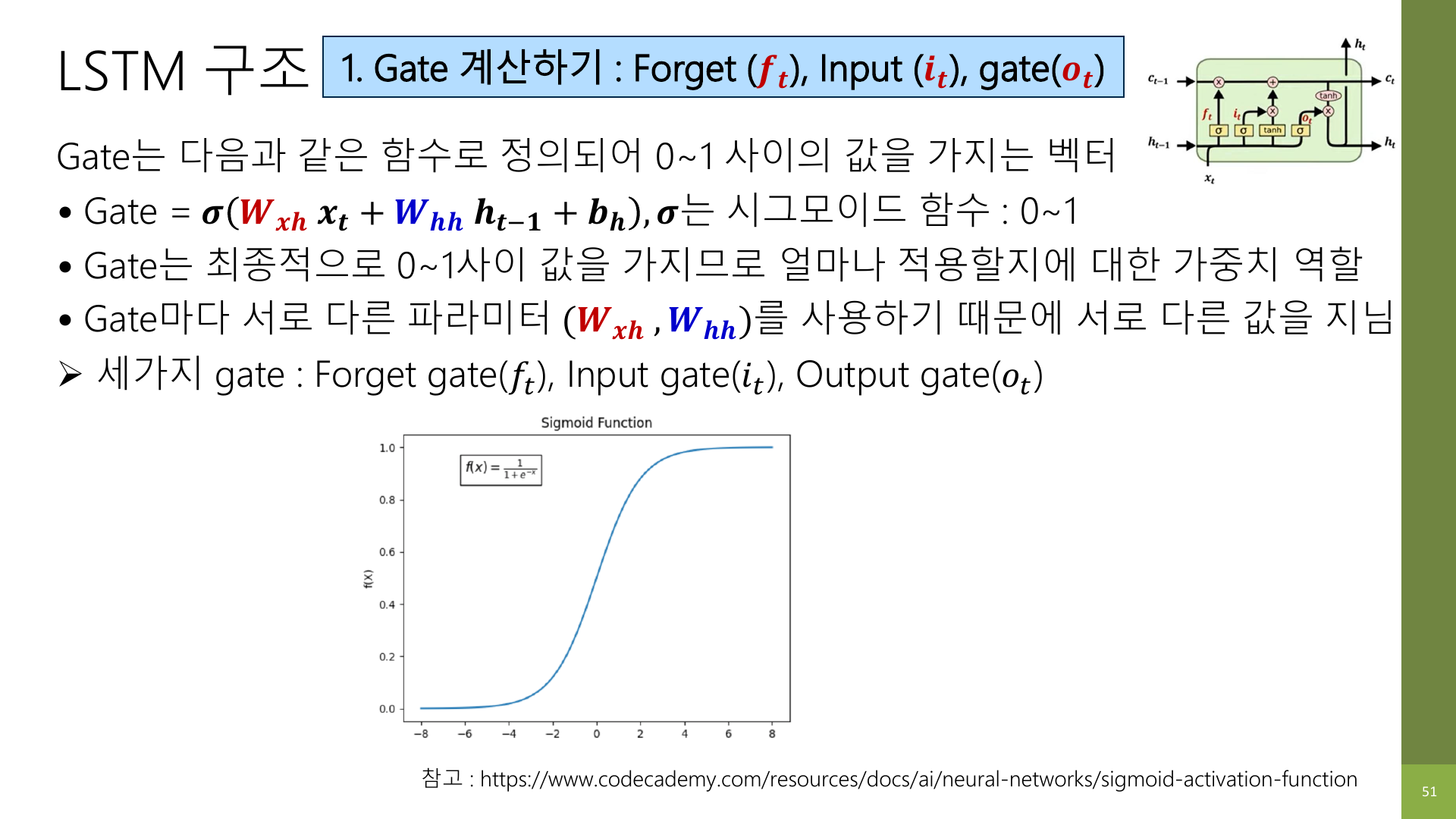
수학을 깊게 몰라도 이건 이렇게 이해하면 된다.
- 0에 가까우면: 거의 안 통과시킨다
- 1에 가까우면: 거의 그대로 통과시킨다
- 중간값이면: 일부만 반영한다
즉, gate는 일종의 조절 밸브다.
수도꼭지를 조금 열지, 많이 열지 정하듯 정보가 얼마나 지나갈지 조절한다.
그리고 중요한 점은 세 gate가 서로 같은 역할을 하지 않는다는 것이다.
각 gate는 서로 다른 가중치를 써서, 서로 다른 판단을 하도록 학습된다.
5-1. Gate 식에서 sigmoid가 나오는 이유
LSTM 식을 보면 gate마다 비슷한 형태가 반복된다.
f_t = sigmoid(W_f · [h_{t-1}, x_t] + b_f)
i_t = sigmoid(W_i · [h_{t-1}, x_t] + b_i)
o_t = sigmoid(W_o · [h_{t-1}, x_t] + b_o)여기서 중요한 것은 기호를 다 외우는 게 아니라, 왜 sigmoid를 쓰는지를 이해하는 것이다.
sigmoid는 값을 0과 1 사이로 바꿔 준다.
그래서 gate 역할과 아주 잘 맞는다.
- 0에 가까우면 거의 막는다
- 1에 가까우면 거의 통과시킨다
- 0.4, 0.7 같은 값이면 일부만 반영한다
즉, gate는 “예/아니오”처럼 딱 자르는 스위치가 아니라,
얼마나 통과시킬지를 부드럽게 조절하는 밸브다.
5-2. 왜 현재 입력과 이전 hidden state를 같이 보나
게이트 식에는 항상 현재 입력 x_t와 이전 hidden state h_{t-1}가 같이 들어간다.
이것도 의미가 분명하다.
x_t만 보면 지금 들어온 정보만 안다h_{t-1}만 보면 과거 흐름만 안다
그런데 LSTM은 “지금 들어온 정보가 과거 문맥을 봤을 때 얼마나 중요한가”를 판단해야 한다.
그래서 두 정보를 함께 보고 gate 값을 만든다.
예를 들어 not 뒤에 오는 감정 단어는 평소와 다르게 해석해야 할 수 있다.
그 판단은 현재 단어만 봐서는 안 되고, 직전 문맥도 같이 봐야 한다.
6. Forget gate: 무엇을 잊을지 정한다
forget gate는 이름 그대로, 이전 기억 중 무엇을 지울지 정한다.
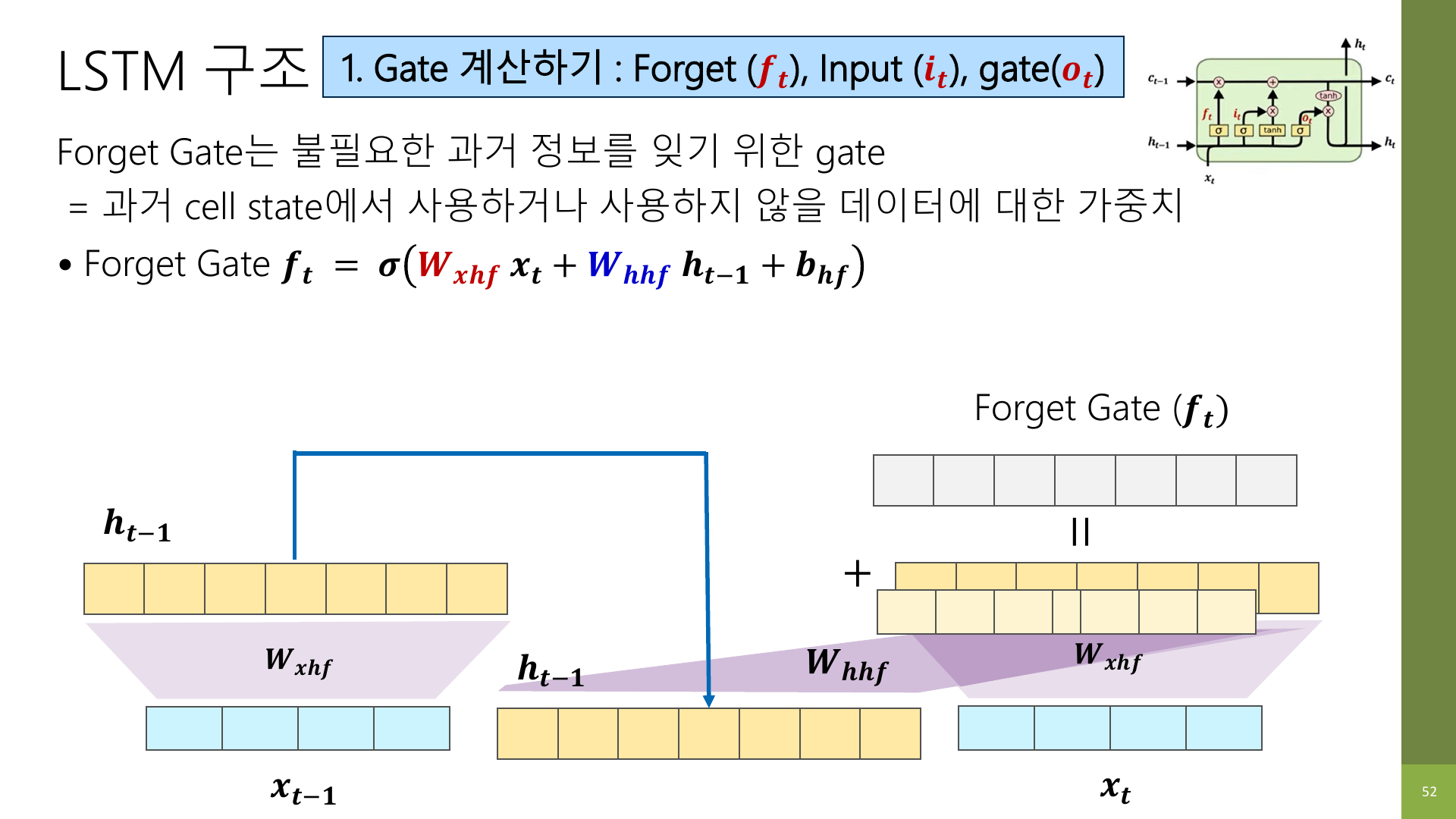
강의 자료 표현대로 보면 forget gate는 과거 cell state에서 사용하거나 사용하지 않을 데이터에 대한 가중치다.
이걸 문장 예시로 바꾸면 이해가 쉽다.
예를 들어 문장을 읽다가 주제가 바뀌는 경우가 있다.
I was talking about the weather, but now I want to discuss the movie.
이럴 때 앞쪽의 날씨 관련 정보는 뒤로 갈수록 덜 중요해질 수 있다.
forget gate는 이런 과거 정보를 얼마나 남길지 조절한다.
강의 자료 57~59페이지는 forget gate가 실제로 어떻게 작동하는지 숫자 예시로 보여 준다.
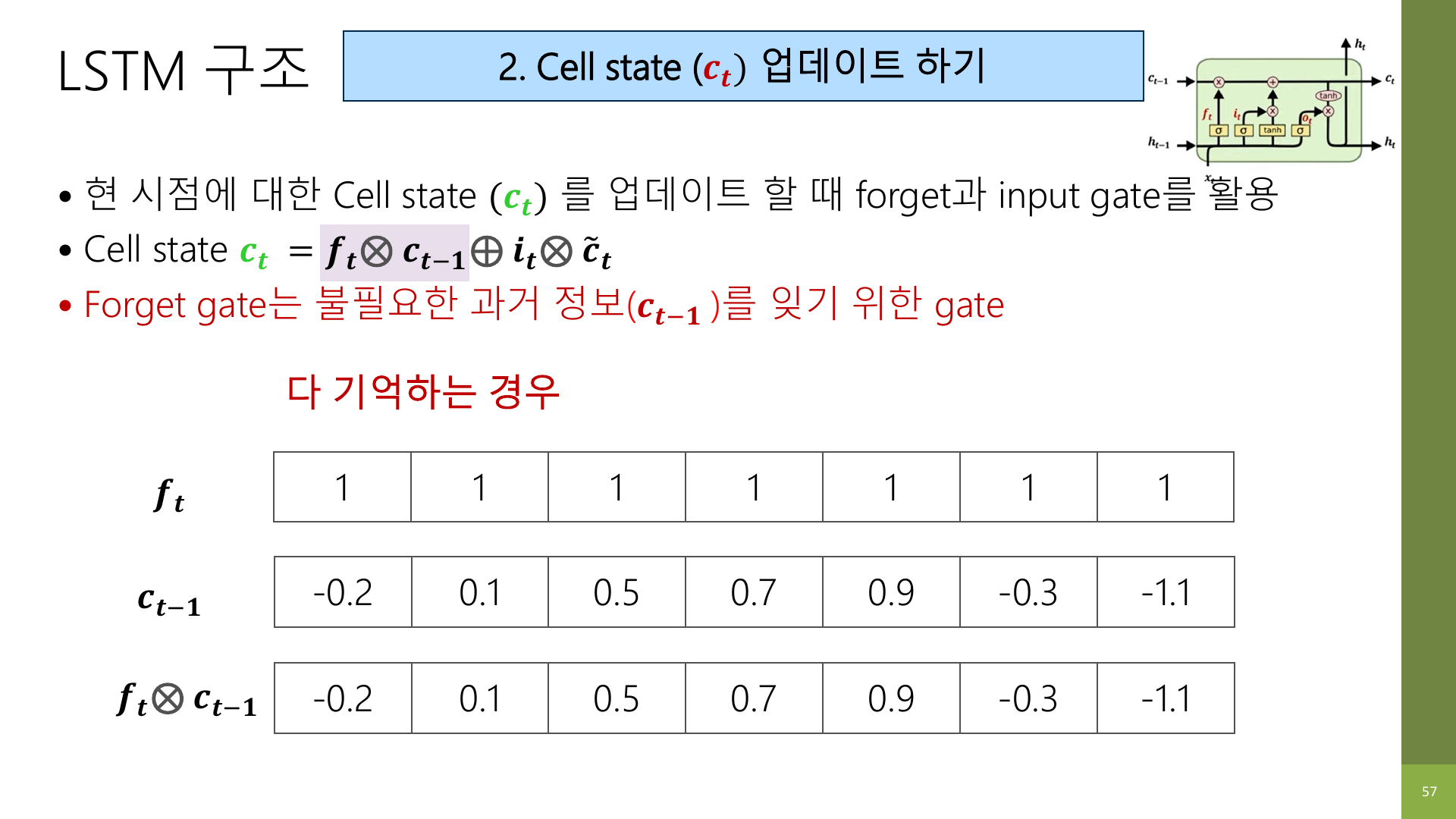
gate 값이 전부 1에 가깝다면, 예를 들어 문장에서 주어가 계속 유지되는 상황처럼 기존 문맥을 거의 그대로 들고 간다고 이해하면 된다.
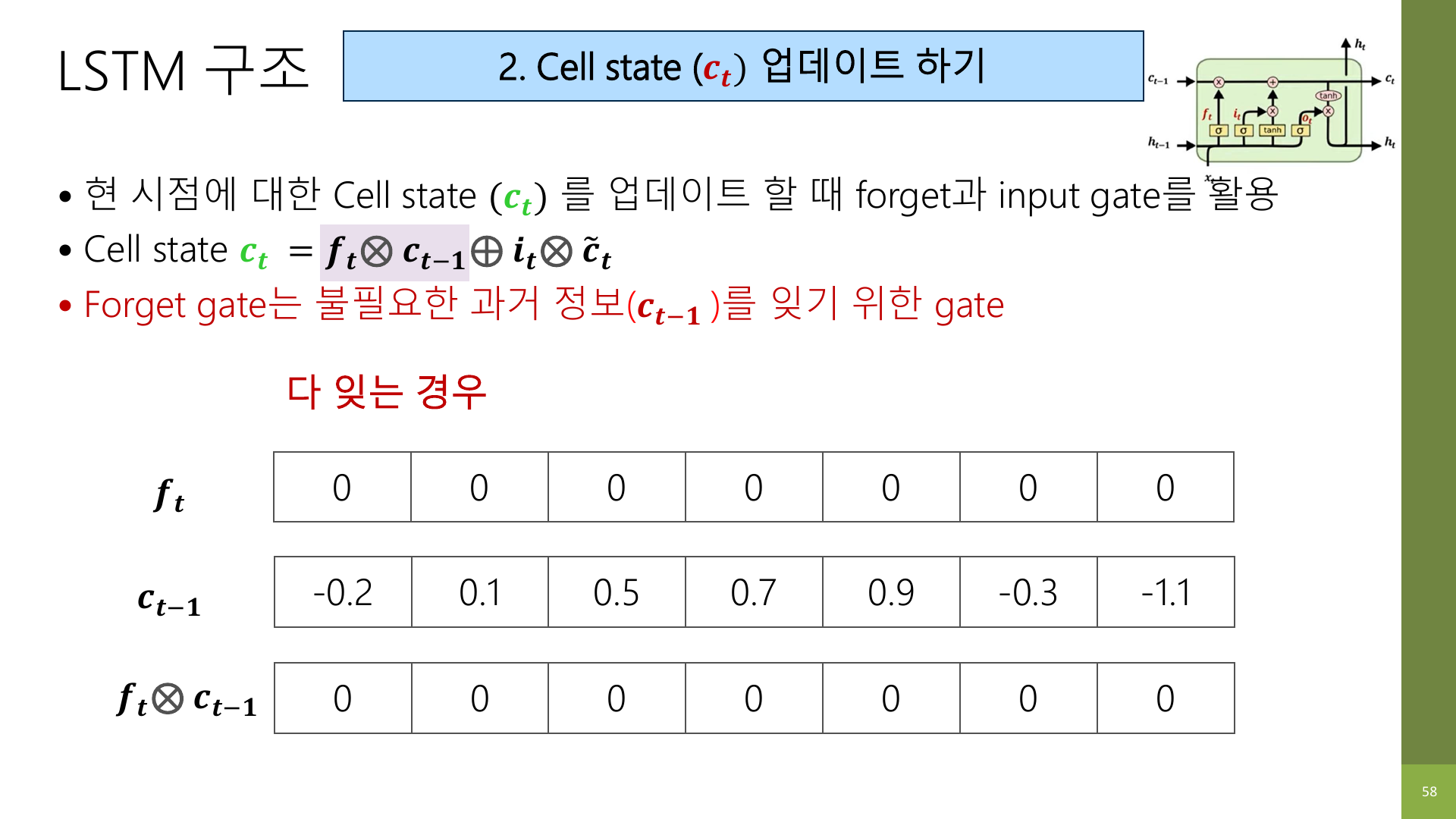
반대로 gate 값이 전부 0에 가깝다면, 문장이 완전히 다른 주제로 넘어가서 예전 문맥을 거의 버리는 상황에 가깝다.
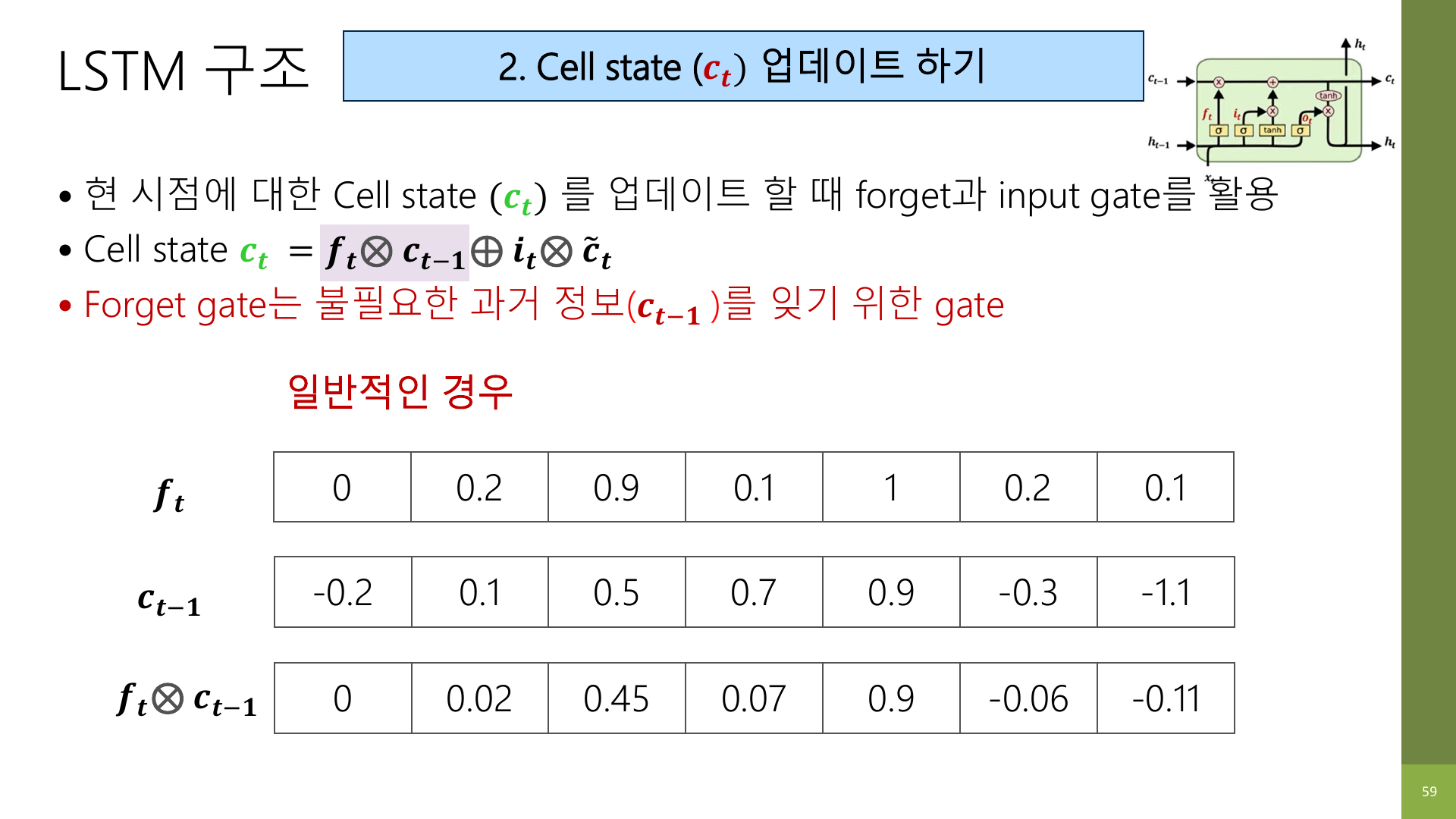
실제로는 0과 1 사이의 값이 나오므로, 어떤 정보는 많이 남기고 어떤 정보는 조금만 남긴다.
즉, forget gate는 “무조건 다 기억”도 아니고 “무조건 다 삭제”도 아니라,
과거 정보에 선택적으로 감쇠를 주는 장치라고 보면 된다.
6-1. 수학적으로 forget gate는 무엇을 하는가
forget gate를 수학적으로 쓰면 보통 아래 형태다.
f_t × c_{t-1}이 식은 사실 아주 직관적이다.
- 이전 cell state
c_{t-1}가 과거 메모이고 f_t가 그 메모를 얼마나 남길지 정하는 비율이다
예를 들어 어떤 성분의 forget gate 값이 1이면 그대로 남는다.
0이면 완전히 지워진다.
0.3이면 30% 정도만 남긴다.
문장으로 바꾸면 더 쉽게 볼 수 있다.
"I went to a movie theater ..."처럼 영화 이야기가 계속 이어지면 관련 메모는 많이 남긴다- 그런데 뒤에서
"Now let me talk about today's weather"처럼 주제가 바뀌면 영화 관련 메모는 크게 줄일 수 있다 - 완전히 버리지는 않더라도 중요도를 낮춰 뒤로 보내는 식이다
즉, forget gate는 과거 메모를 “삭제할지 말지”만 정하는 것이 아니라,
얼마나 약하게 만들지까지 포함해서 조절하는 장치다.
7. Input gate: 지금 정보를 얼마나 새로 넣을지 정한다
input gate는 현재 시점에서 새로 들어온 정보를 얼마나 기억할지 정한다.
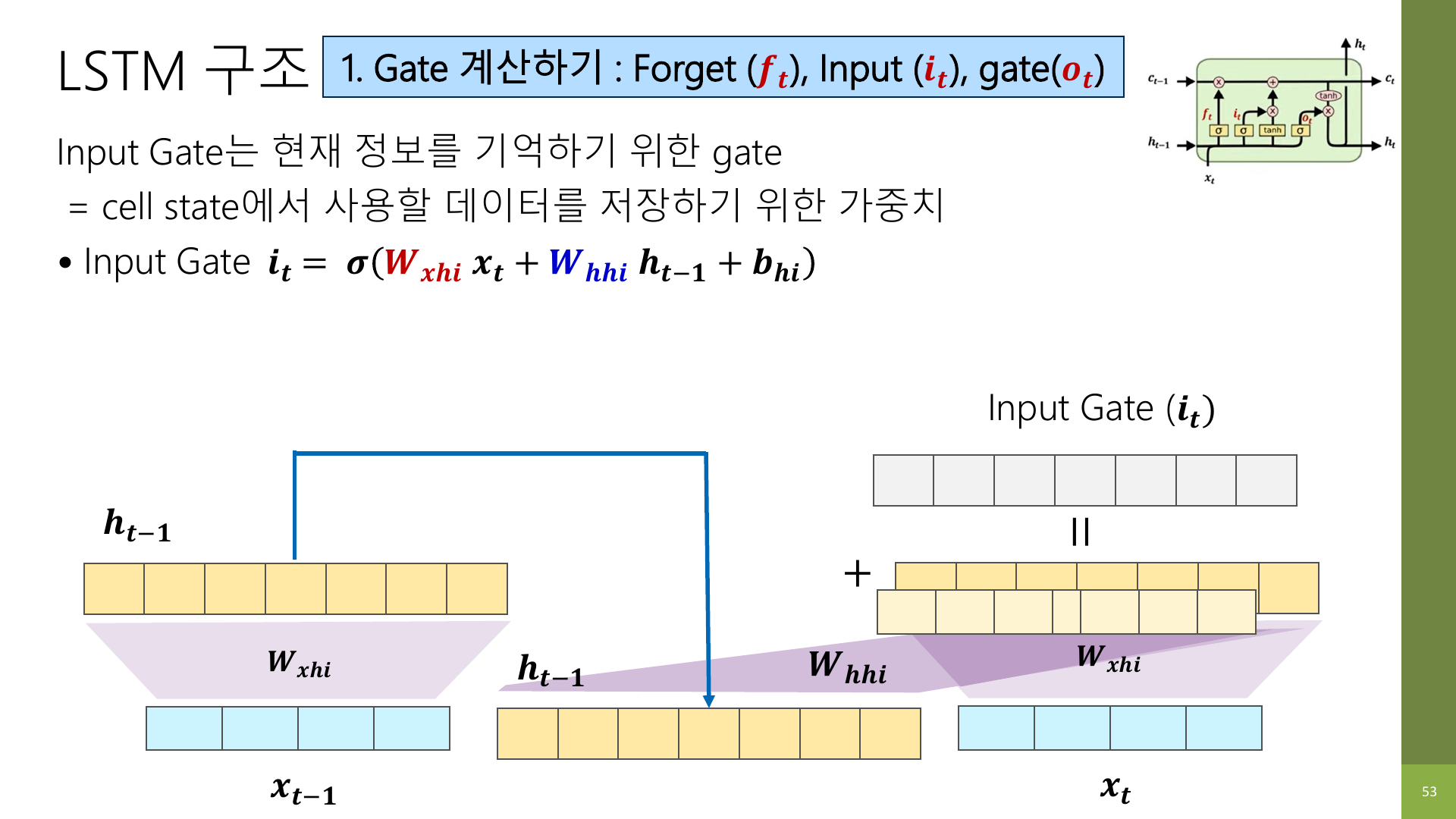
forget gate가 과거 정리 담당이라면, input gate는 새 정보 입력 담당이다.
예를 들어 아래 문장을 보자.
The movie was boring at first, but the ending was amazing.
문장 후반부에서 amazing 같은 강한 단어가 나오면, 지금 시점의 정보는 더 강하게 기억할 필요가 있다. 반대로 의미가 약한 정보는 조금만 반영해도 된다.
강의 자료 56페이지는 먼저 현재 입력과 이전 hidden state를 바탕으로 임시 cell state 후보를 만들고,

60페이지에서는 input gate가 그 후보 정보에 얼마나 가중치를 줄지 보여 준다.
즉, input gate는 “새로운 정보를 얼마나 강하게 기억할지”를 정하는 게이트다.
forget gate가 과거를 정리한다면, input gate는 현재를 받아 적는 역할이다.
7-1. 후보 메모 \tilde{c_t}는 무엇인가
LSTM 식에서는 gate 외에 하나 더 자주 나오는 값이 있다.
바로 “후보 cell state”다. 보통 아래처럼 적는다.
\tilde{c_t} = tanh(W_c · [h_{t-1}, x_t] + b_c)이건 “지금 입력을 바탕으로 새로 메모한다면 어떤 내용을 적을까”에 해당한다.
즉,
- forget gate는 과거 메모를 얼마나 남길지 정하고
- input gate는 새 메모를 얼마나 받아들일지 정하고
- 후보 메모는 실제로 새로 들어올 내용 자체를 만든다
라고 보면 된다.
여기서 tanh가 쓰이는 이유도 RNN과 비슷하다.
값이 너무 커지지 않게 정리하면서, 양수와 음수 방향의 의미를 모두 담기 쉽기 때문이다.
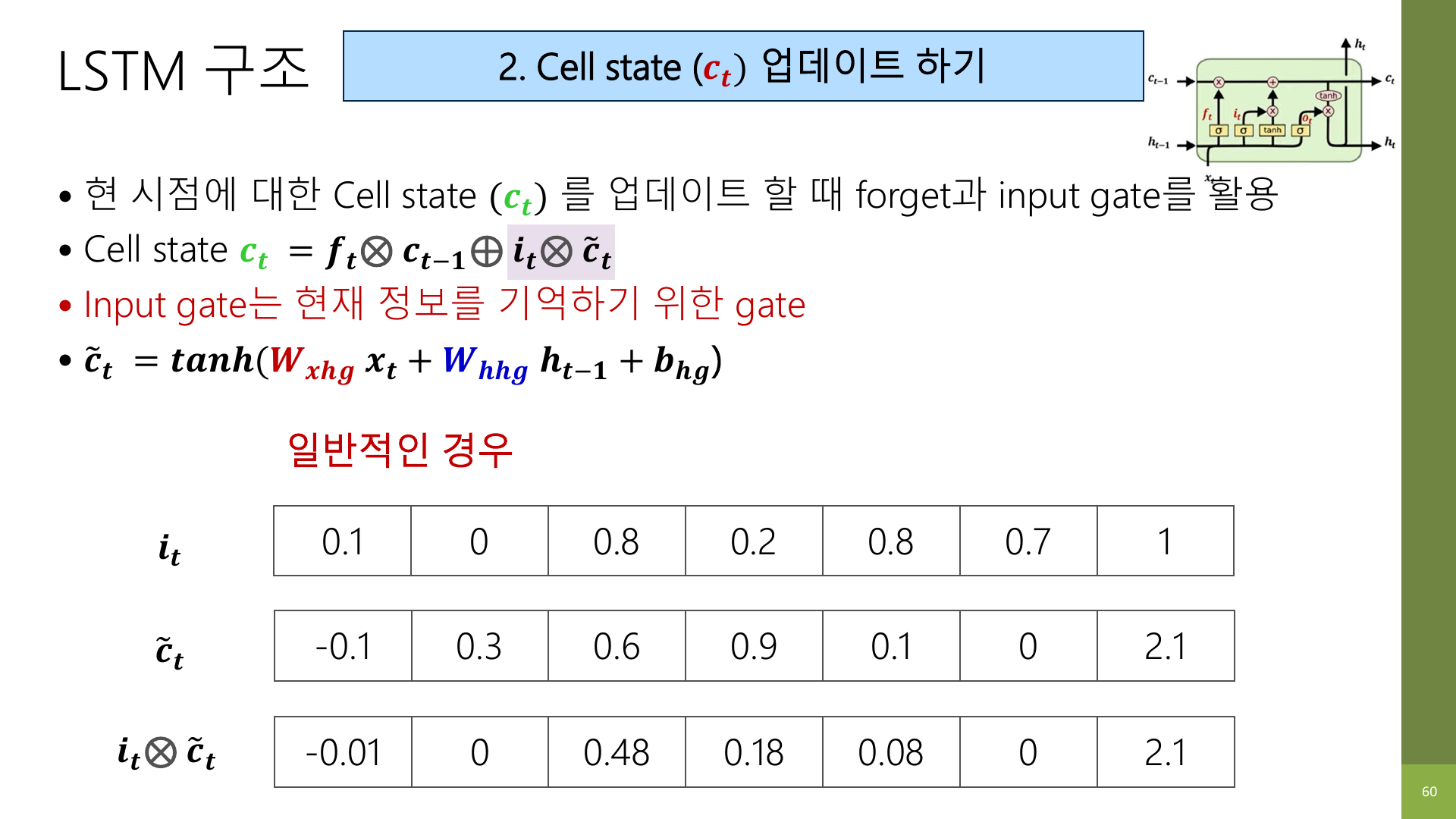
8. Cell state 업데이트는 결국 두 가지의 합이다
강의 자료의 핵심 수식은 결국 아래 뜻으로 읽으면 된다.
새 cell state
= 남겨 둘 과거 기억
+ 새로 쓸 현재 기억조금 더 LSTM답게 쓰면:
c_t = (forget gate × 이전 c_t-1) + (input gate × 현재 후보 정보)이 구조가 중요한 이유는, RNN보다 훨씬 명시적으로 기억을 관리한다는 점이다.
- 과거는 forget gate를 통해 정리하고
- 현재는 input gate를 통해 반영한다
즉, LSTM은 “한 번에 뒤섞어 계산”하는 느낌보다, 기억을 관리하는 절차가 분리되어 있다.
그래서 긴 시퀀스에서 더 안정적으로 동작할 여지가 생긴다.
8-1. 이 식이 LSTM의 핵심인 이유
사실 LSTM 수학에서 가장 중요한 식은 이 c_t 업데이트 식 하나라고 봐도 된다.
c_t = f_t * c_{t-1} + i_t * \tilde{c_t}이 식이 중요한 이유는, RNN처럼 모든 걸 한 번에 뒤섞지 않기 때문이다.
- 왼쪽 항
f_t * c_{t-1}는 과거를 관리하는 부분 - 오른쪽 항
i_t * \tilde{c_t}는 현재를 반영하는 부분
즉, 과거와 현재의 역할이 분리되어 있다.
그래서 어떤 정보는 오래 유지하고, 어떤 정보는 새로 덮어쓰는 식의 제어가 가능해진다.
이걸 사람식으로 바꾸면 아래와 같다.
- 예전 노트 중 필요한 부분은 남긴다
- 오늘 새로 들은 내용 중 중요한 것만 추가한다
- 이 둘을 합쳐서 최신 핵심 노트를 만든다
9. Output gate: 지금 무엇을 밖으로 보여 줄지 정한다
output gate는 cell state 전체를 다 노출하지 않고, 지금 시점에서 필요한 부분만 hidden state로 꺼내는 역할을 한다.
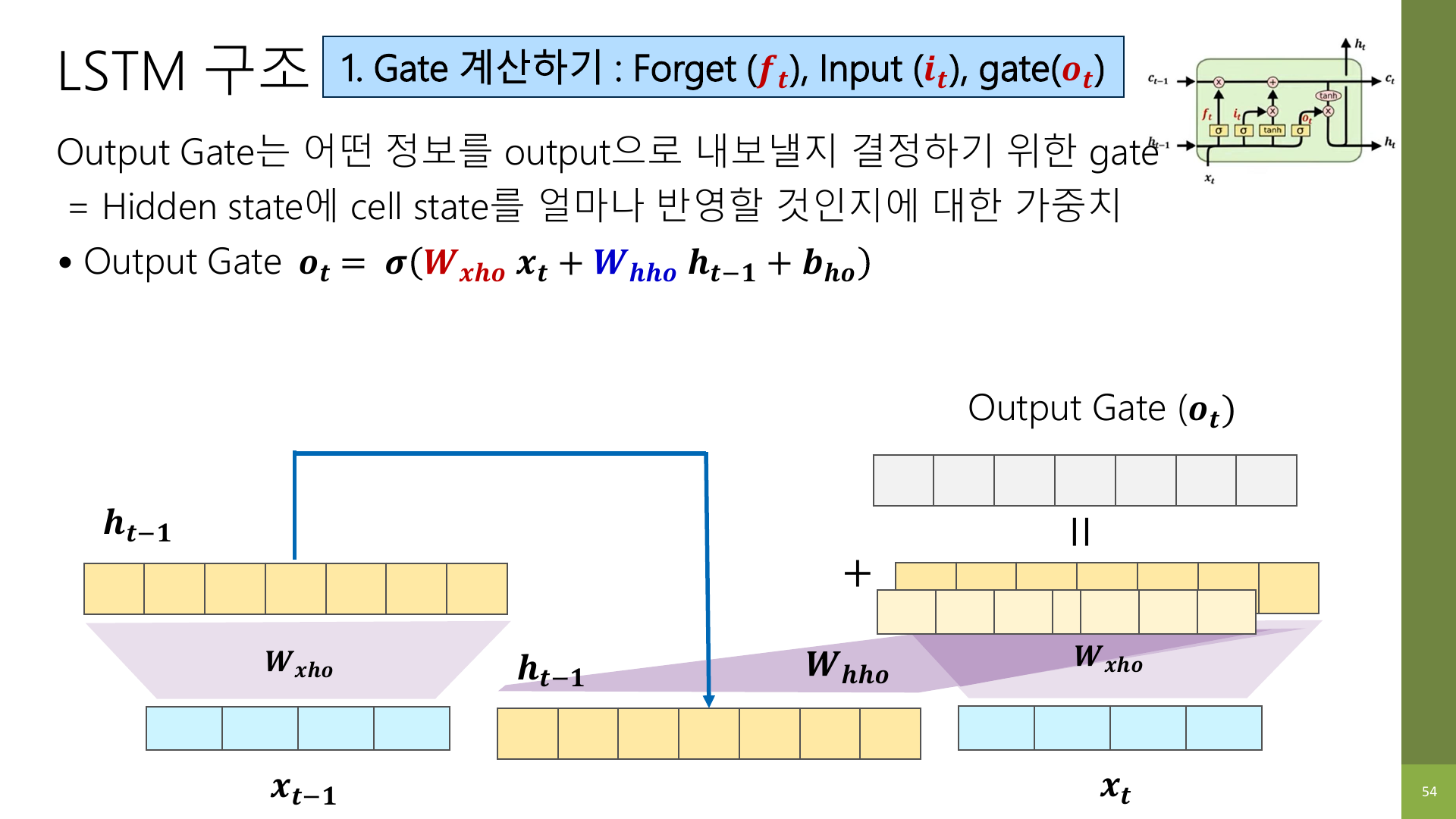
그리고 강의 자료 61~62페이지는 hidden state 업데이트를 따로 정리한다.
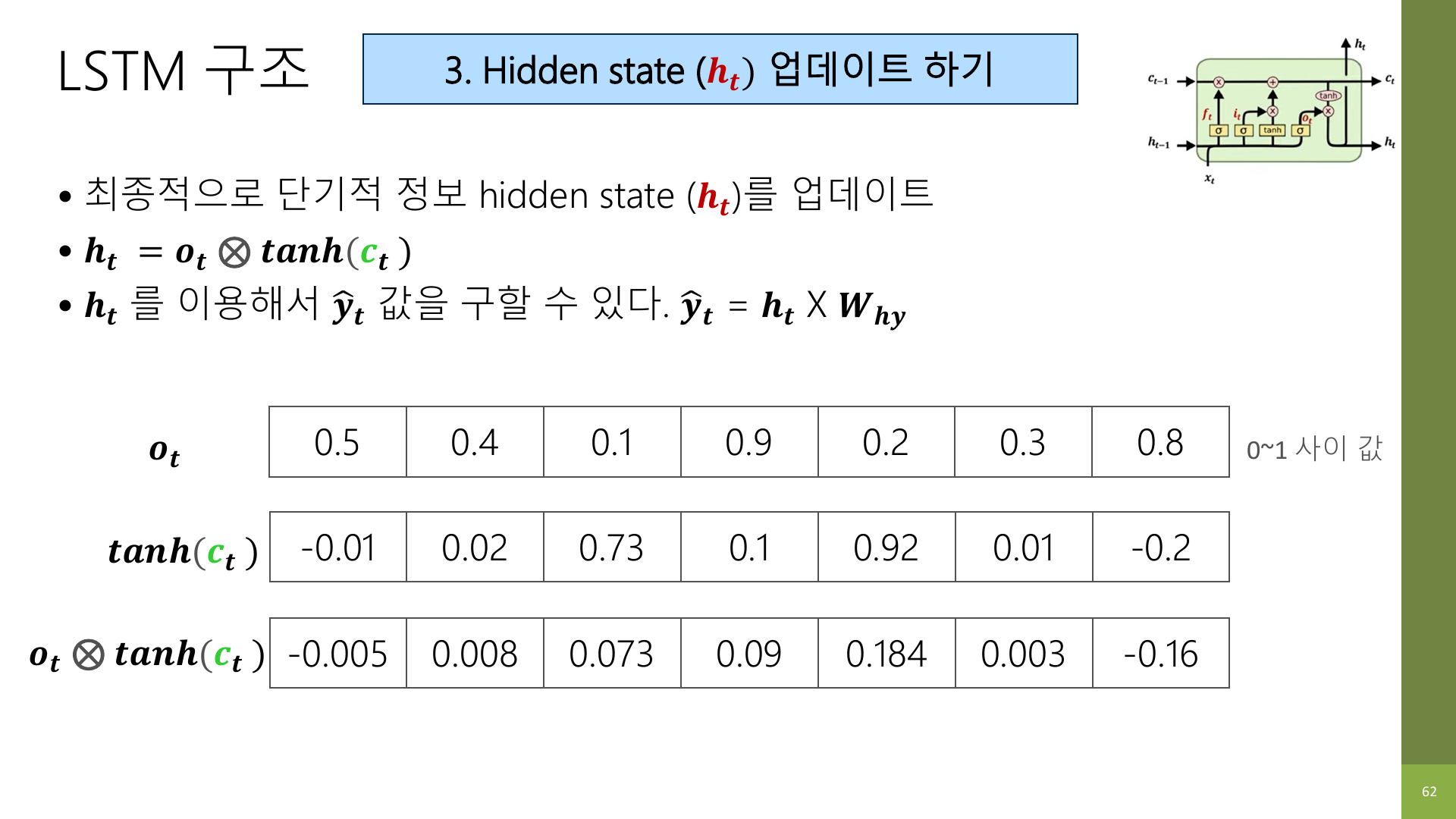
직관은 이렇다.
- cell state는 장기 메모리라 비교적 많이 들고 간다.
- 하지만 모든 걸 그대로 출력으로 쓰지는 않는다.
- output gate가 “지금 필요한 부분”만 걸러서 hidden state를 만든다.
즉, output gate는 메모장을 통째로 펼치는 것이 아니라,
지금 발표에 필요한 부분만 발췌해서 말하는 역할에 가깝다.
9-1. hidden state는 왜 cell state와 같지 않은가
초반에는 이런 의문이 생기기 쉽다.
이미 cell state에 중요한 정보가 들어 있으면, 그걸 그대로 출력하면 되는 것 아닌가?
하지만 LSTM은 그렇게 하지 않는다. 보통 아래처럼 계산한다.
h_t = o_t * tanh(c_t)이 식의 의미는 두 단계다.
tanh(c_t)로 cell state를 출력에 적합한 형태로 한 번 정리한다o_t로 지금 필요한 만큼만 꺼낸다
즉, cell state는 장기 보관용 메모이고, hidden state는 지금 발표용 요약본이다.
둘을 아예 같은 값으로 두면 “오래 보관하는 역할”과 “지금 바로 보여 주는 역할”이 다시 섞여 버린다.
예를 들어 긴 영화 리뷰 문장을 읽는다고 해 보자.
- cell state에는 “이 문장은 전반적으로 영화 평가에 대한 이야기다”, “중간에 반전 표현이 나왔다” 같은 흐름을 오래 들고 갈 수 있다
- 하지만 hidden state는 지금 이 순간 예측에 필요한 내용, 예를 들어
boring,amazing,not같은 현재 주변 문맥을 더 직접적으로 반영한다
즉, LSTM은 “전체 메모”와 “지금 발표용 요약”을 구분하려고 두 상태를 나눈다.
10. LSTM을 사람식으로 다시 풀어 보면
여기까지를 아주 일상적으로 바꾸면 아래처럼 이해할 수 있다.
10-1. Forget gate
“예전에 적어 둔 내용 중 지금은 덜 중요한 건 좀 흐리게 하자.”
10-2. Input gate
“방금 들어온 정보 중 중요한 건 새로 적어 두자.”
10-3. Cell state
“지금까지 유지해 온 핵심 메모”
10-4. Output gate
“그 메모 전체를 다 말하지 말고, 지금 필요한 부분만 꺼내서 쓰자.”
이렇게 보면 LSTM은 수식 덩어리가 아니라,
기억을 지우고, 추가하고, 꺼내는 세 단계를 명확하게 나눈 모델이라고 이해할 수 있다.
11. LSTM이 RNN보다 긴 문장에 유리한 이유
강의 자료의 첫 줄 요약은 결국 이것이다.
LSTM은 장기 의존성 문제를 완화한 RNN 개선 모델이다.
왜 완화되는가를 직관적으로 보면 다음과 같다.
11-1. 기억 전용 통로가 따로 있다
RNN은 hidden state 하나에 모든 역할이 몰려 있었다.
LSTM은 cell state를 따로 둬서 장기 기억 통로를 분리했다.
11-2. gate로 선택적으로 관리한다
정보를 무조건 다 전달하는 것이 아니라,
- 지울 것
- 새로 넣을 것
- 출력할 것
을 나눠서 관리한다.
11-3. 긴 문장에서 중요 정보가 덜 흐려진다
완벽하게 기억하는 것은 아니더라도,
RNN처럼 단순 반복 곱으로만 밀려가는 구조보다
중요한 정보를 좀 더 오래 유지할 수 있다.
즉, LSTM은 “기억을 잘하기 위해 더 복잡하게 만든 RNN”이라고 보면 된다.
11-4. 수학적으로 보면 왜 더 버티는가
수학을 잘 몰라도 여기까지 오면 이 질문이 남는다.
왜 LSTM은 RNN보다 긴 문장에서 덜 무너질까?
핵심은 cell state 업데이트 식에 있다.
c_t = f_t * c_{t-1} + i_t * \tilde{c_t}RNN은 hidden state를 계속 새로 섞어서 만들기 때문에, 오래된 정보가 반복 계산 속에서 희미해지기 쉽다.
반면 LSTM은 cell state라는 비교적 직접적인 통로를 두고, forget gate가 1에 가까우면 중요한 정보를 상당 부분 유지할 수 있다.
물론 LSTM도 완벽하지는 않다.
하지만 “과거를 얼마만큼 남길지”를 모델이 직접 배우게 했기 때문에, RNN보다 장기 정보 유지에 유리한 구조가 된다.
12. 강의 자료 기준으로 꼭 기억할 것
강의 자료 63페이지는 LSTM 전체를 다시 한 번 요약한다.
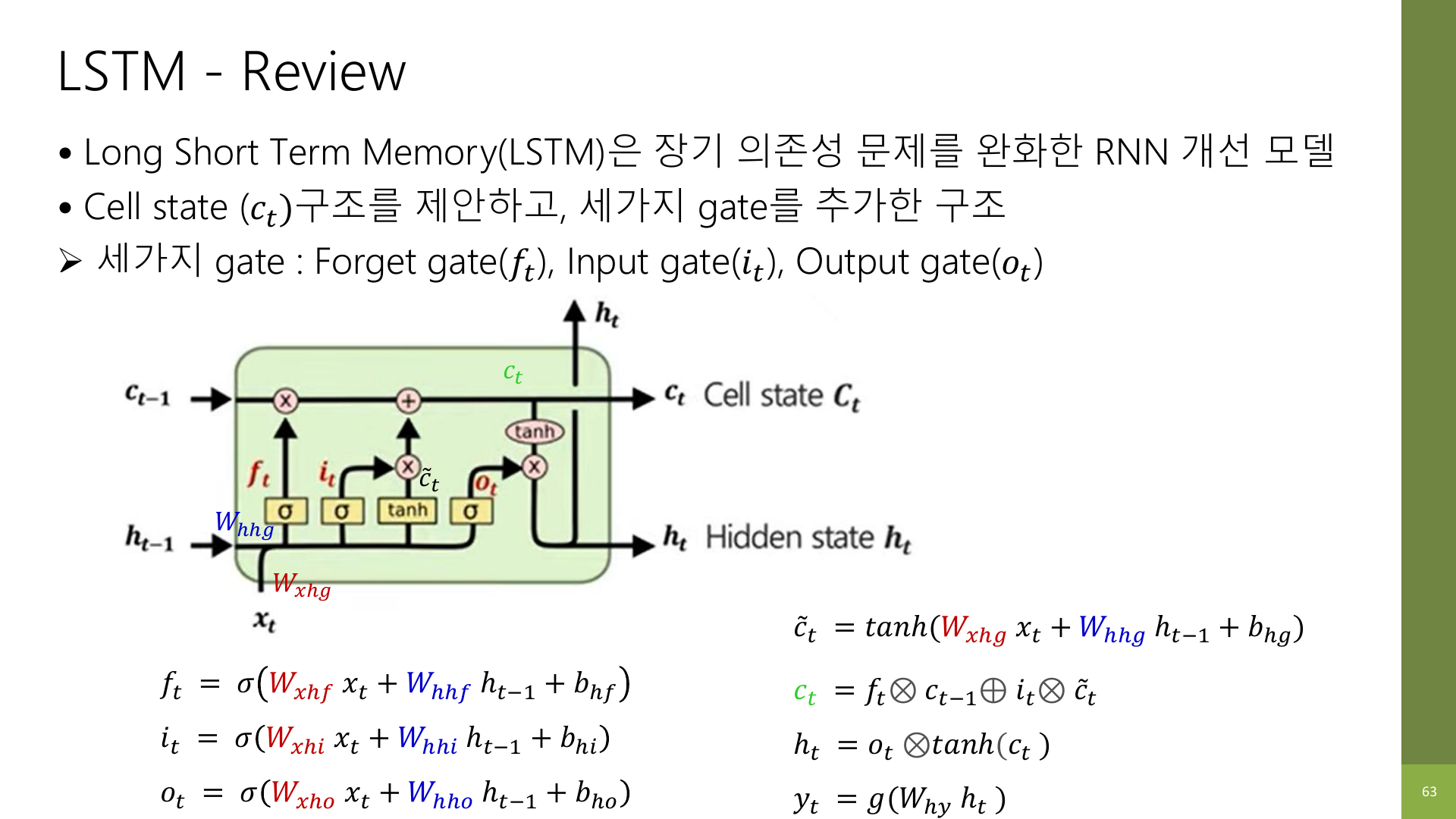
이 페이지 기준으로 꼭 남겨야 할 것은 아래 네 줄이다.
12-1. LSTM은 RNN의 개선형이다
긴 시퀀스에서 RNN이 약한 문제를 줄이기 위해 나왔다.
12-2. Cell state와 hidden state를 나눈다
- cell state: 장기 기억
- hidden state: 현재 시점 출력용 요약
12-3. 세 gate가 있다
- forget gate: 무엇을 잊을지
- input gate: 무엇을 새로 기억할지
- output gate: 무엇을 밖으로 보여 줄지
12-4. 결국 기억 관리 모델이다
LSTM은 단순히 값을 전달하는 모델이 아니라,
기억을 선택적으로 관리하는 순차 모델이다.
12-5. 수학적으로 꼭 잡아야 하는 핵심
LSTM 수학을 전부 계산하지 않아도, 아래 다섯 줄이 이해되면 충분하다.
sigmoid는 gate 값을 0~1 사이로 만들어 정보 통과량을 조절한다.tanh는 후보 메모나 출력용 값을 적당한 범위로 정리한다.- forget gate는 과거 메모를 얼마나 남길지 정한다.
- input gate는 새 메모를 얼마나 쓸지 정한다.
- output gate는 장기 메모 중 지금 보여 줄 부분만 hidden state로 꺼낸다.
마무리
RNN을 이해한 뒤 LSTM을 보면, 구조가 갑자기 복잡해진 것처럼 느껴진다. 하지만 역할 단위로 나눠 보면 생각보다 단순하다. LSTM은 RNN에 기억 관리 장치를 덧붙인 모델이다. 과거를 얼마나 잊을지, 현재를 얼마나 기록할지, 그리고 지금 무엇을 출력할지를 따로 정하도록 만든 구조다.
그래서 긴 문장이나 긴 시계열처럼 “먼 과거 정보가 아직 중요할 수 있는 문제”에서 RNN보다 더 안정적으로 쓰일 수 있다. 다음 글에서는 이 LSTM을 조금 더 단순하게 만든 GRU를 같은 방식으로 이어서 정리할 예정이다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.