2025년 12월 16일과 17일, 이틀 동안 진행한
Move AI는 웨어러블 센서 데이터로 사용자의 활동 상태를 분류하고, 오래 움직이지 않았을 때 바로 실천 가능한 작은 움직임을 제안해 주는 프로젝트였다. 단순히 “분류 정확도”를 높이는 데서 끝나지 않고, 실제 일상생활에서 어떻게 행동 변화를 유도할지까지 연결해 본 점이 이 프로젝트의 핵심이었다.
내 발표 자료를 다시 정리하다 보니 슬라이드 타임라인에는 2025년 12월 15일과 2025년 12월 16일로 표기되어 있었다. 이 글은 내가 정리한 프로젝트 기록 기준인 2025년 12월 16일과 2025년 12월 17일 일정으로 서술하되, 내가 만든 발표 자료 안의 타임라인도 함께 참고해 정리했다.
프로젝트가 다루려던 문제
Move AI는 아주 일상적인 문제에서 시작했다. 운동해야 한다는 건 다 알지만, 실제 생활에서는 오래 앉아 있거나 누워 있는 시간이 훨씬 길다. 이런 비활동 시간이 쌓이면 건강 문제로 이어지기 쉽다.
나는 발표 자료에서 이 문제를 UN SDG Goal 3와 연결해 설명했다. 특히 비전염성 질환(NCDs)과 생활 습관의 관계를 먼저 짚고, 거창한 운동 처방보다도 일상 속에서 바로 실행 가능한 작은 움직임을 유도하는 쪽에 초점을 맞췄다. 즉, 이 프로젝트는 “사람의 활동을 고정밀로 인식하는 AI” 자체보다 “활동 인식을 바탕으로 실제 행동 변화를 만드는 흐름”에 더 가까웠다.
프로젝트가 정의한 서비스 흐름은 아래와 같았다.
- 웨어러블 기기 사용자의 현재 활동 상태를 분류한다.
- 앉아 있음, 누워 있음 같은 비활동 상태가 일정 시간 이상 이어지는지를 감지한다.
- 장시간 움직임이 없으면, 바로 실행 가능한 짧은 활동을 제안한다.
- 예를 들어 “가장 가까운 창가까지 걸어갔다 오세요”처럼 부담이 낮은 행동을 안내한다.
이 지점이 좋았던 이유는, 문제 정의가 기술 중심이 아니라 사용자 행동 중심이었다는 점이다. “분류 모델을 만들었다”가 아니라 “분류 결과를 어떻게 생활 속 개입으로 연결할 것인가”가 처음부터 프로젝트 목적에 포함되어 있었다.
데이터와 분석 방향
이번 프로젝트는 웨어러블 기기에서 수집된 활동 데이터셋을 사용해 진행했다. 발표 자료 기준으로 데이터는 가속도계(accelerometer)와 자이로스코프(gyroscope) 신호에서 추출된 특성들로 구성되어 있었고, 목표는 사람이 수행한 동작을 분류하는 것이었다.
활용한 활동 라벨 예시는 다음과 같은 범주였다.
STANDINGWALKINGSITTING- 그 외 눕기, 계단 이동 등 유사 활동
특성은 시간 영역과 주파수 영역이 함께 포함된 구조였다.
tBodyAcc,tGravityAcc,tBodyGyro,tBodyGyroJerk계열- 각 축의 평균, 표준편차 같은 통계량
- magnitude 기반 파생 특성
fBodyAcc,fBodyGyro계열의 주파수 영역 특성- angle 관련 특성
발표 슬라이드상 전처리는 비교적 명확했다.
rn,activity열 제거- 결측치 없음 확인
- 데이터가 이미
-1 ~ 1범위로 정규화되어 있음 확인
즉, 이번 작업은 데이터 클렌징에 시간을 많이 쓰는 유형이라기보다, “이 고차원 센서 특성에서 어떤 구조가 실제로 드러나는가”를 파악하는 분석 중심 프로젝트에 가까웠다.
이틀 동안 실제로 한 일
발표 자료의 타임라인을 보면 작업 흐름이 꽤 분명하다.
- 초반에는 데이터 구조와 특성을 빠르게 탐색했다.
- 그다음 프로젝트 목적, 즉 왜 이 분석을 하는지를 먼저 구체화했다.
- 전처리 이후
K-Means기반 클러스터링을 진행하고Elbow Method로 적절한k를 찾았다. - 이후 성능 지표를 함께 보며 최종
k를 결정했다. - 차원 축소를 적용한 뒤 실제 데이터 구조를 다시 시각화했다.
- 마지막에는
Random Forest까지 비교해 보면서 지도학습 관점의 기준점도 확인했다. - 최종 산출물은 발표 자료와 HTML 형태의 간단한 결과물로 정리했다.
짧은 프로젝트일수록 이런 순서가 중요하다. 무작정 모델부터 돌리기보다, 문제 정의와 분석 목적을 먼저 고정해 두면 발표도 훨씬 선명해진다. Move AI는 그 점에서 기술 선택보다 문제 구조화가 먼저였던 프로젝트였다.
미니 프로젝트 중간 기록
실제로는 이런 분석 흐름이 아주 차분하게만 진행되지는 않았다. 짧은 일정 안에 데이터 해석, 모델 비교, 발표 자료 정리까지 한 번에 밀어 넣어야 했기 때문에 중간 과정은 꽤 현실적인 체력전이었다.
먼저 자료를 만들고 결과를 정리하던 순간은 거의 계속 노트북 앞에서 슬라이드와 분석 결과를 같이 맞춰 가는 흐름이었다. 단순히 코드만 실행하는 시간이 아니라, “이 결과를 발표에서 어떻게 설명할지”까지 동시에 정리해야 해서 생각보다 손이 많이 갔다.
특히 미니 프로젝트는 결과만 내면 끝나는 게 아니라, 왜 이런 기준으로 k를 골랐는지, 차원 축소는 왜 따로 봤는지, 그리고 이 분석이 실제 서비스 아이디어와 어떻게 연결되는지까지 짧은 시간 안에 설명 가능해야 했다. 그래서 분석, 정리, 발표 준비가 완전히 분리되지 않고 한 덩어리로 움직였다.
점심시간쯤에는 체력이 꽤 떨어져서 잠깐 그대로 쉬어 버릴 정도로 빡빡했다. 아래 사진은 그런 분위기를 그대로 보여준다. 일정은 짧았지만 해야 할 일은 많았고, 그래서 이 프로젝트는 기술 실습이면서 동시에 집중력 관리 싸움이기도 했다.

지금 다시 돌아보면 이 구간이 오히려 프로젝트의 성격을 잘 보여준다. 완성도 높은 장기 프로젝트라기보다, 제한된 시간 안에서 문제를 빠르게 이해하고 핵심 분석을 뽑아 내고, 그 결과를 발표 가능한 형태로 압축하는 훈련에 가까웠다. 그래서 뒤에 나오는 K-Means, 차원 축소, Random Forest 비교도 단순한 실험 나열이 아니라 “짧은 시간 안에 무엇을 우선순위로 두었는가”라는 맥락에서 보는 편이 더 잘 맞는다.
K값 탐색과 클러스터링
핵심 모델링은 K-Means 클러스터링이었다. 발표 자료에서는 먼저 Elbow Method를 사용해 적절한 군집 수를 탐색했고, 내가 정리한 그래프 기준으로는 k=2와 k=5 부근이 후보로 제시됐다.
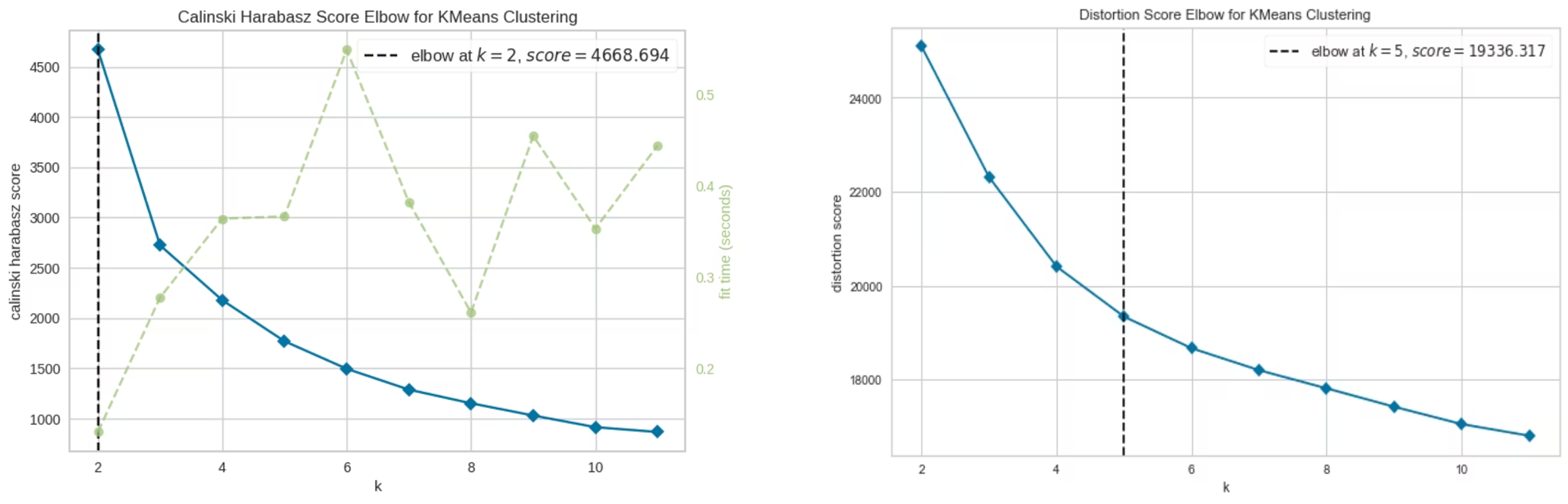
여기서 흥미로웠던 부분은 프로젝트가 k=2와 k=4를 서로 다른 목적에서 해석했다는 점이다.
k=2: 활동과 비활동을 크게 나누는 데 적합k=4: 실제 행동 패턴을 더 세밀하게 나누는 데 적합
즉, 이 프로젝트는 “정답은 하나”라는 식으로 접근하지 않았다. 서비스 목적이 “오래 안 움직인 사용자를 감지하는 것”이라면 k=2가 실용적일 수 있고, 행동 패턴을 더 잘 설명하는 분석 보고서가 목적이라면 k=4가 더 나을 수 있다는 식으로 해석했다.
차원 축소를 하지 않은 상태의 클러스터링 시각화도 포함되어 있었다.
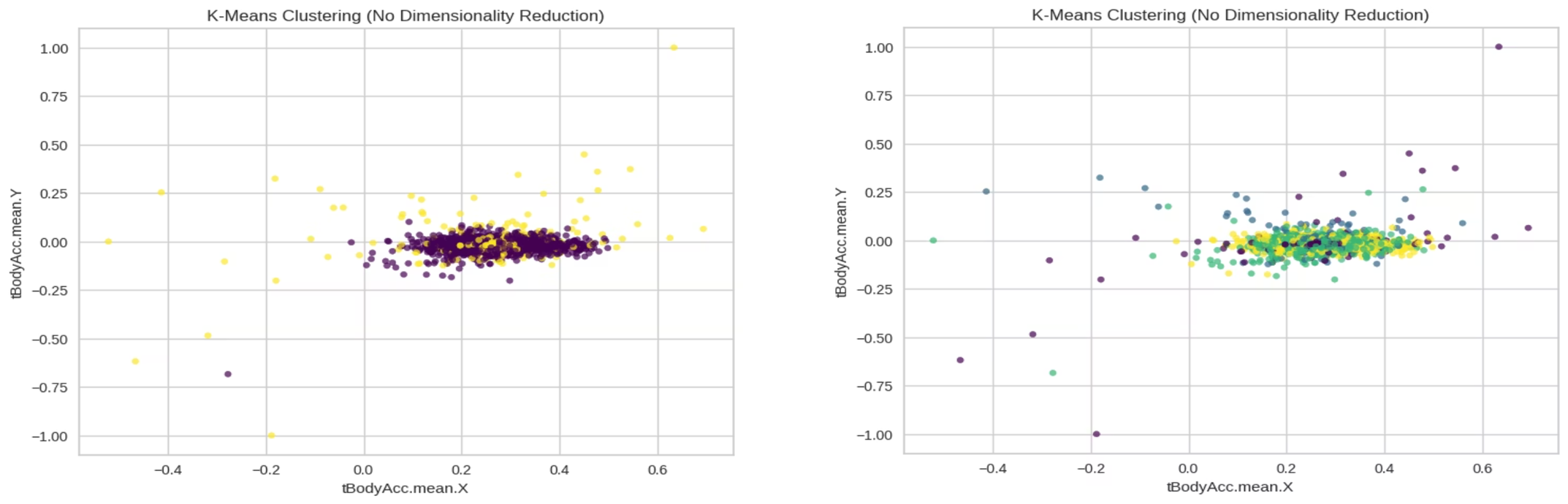
이 슬라이드에서 내가 보여주고 싶었던 건 센서 기반 데이터는 차원이 높아서, 변수 두 개만으로는 활동 구조를 제대로 설명하기 어렵다는 점이었다. 그래서 PCA나 t-SNE 같은 차원 축소를 같이 써야 한다는 쪽으로 자연스럽게 넘어갔다.
차원 축소와 시각화
발표에서는 차원 수에 따라 학습 시간과 성능이 어떻게 달라지는지도 비교했다. 핵심 포인트는 50차원으로 줄였을 때 성능 손실은 크지 않은데 학습 시간은 많이 단축된다는 점이었다.
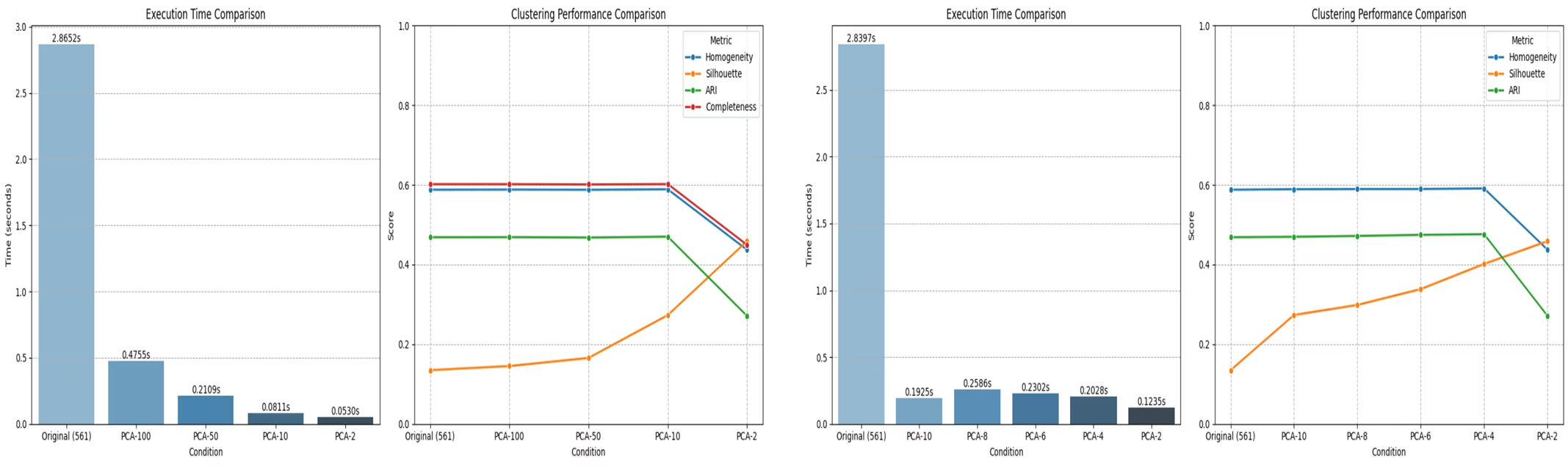
실무에서도 이 해석은 무리가 없다.
- 원본 고차원 데이터를 그대로 쓰면 계산량이 크다.
- 너무 적게 줄이면 정보 손실이 커질 수 있다.
- 적당한 수준의 축소는 성능과 속도의 균형점이 된다.
나는 발표 자료에서 차원 축소 방식도 목적별로 구분해 정리했다.
PCA: 머신러닝 모델링용으로 적절t-SNE: 시각화용으로 적절
즉, 같은 차원 축소라도 용도를 구분해서 써야 한다는 점을 짚은 셈이다. 시각화가 잘 보인다고 해서 바로 모델 입력으로 쓰는 것이 아니라, 어떤 목적의 도구인지 구분하는 태도가 좋았다.
K=2, K=4, K=6 비교에서 보인 해석
차원 축소 후에는 k=2, k=4, k=6 시각화를 각각 비교했다.
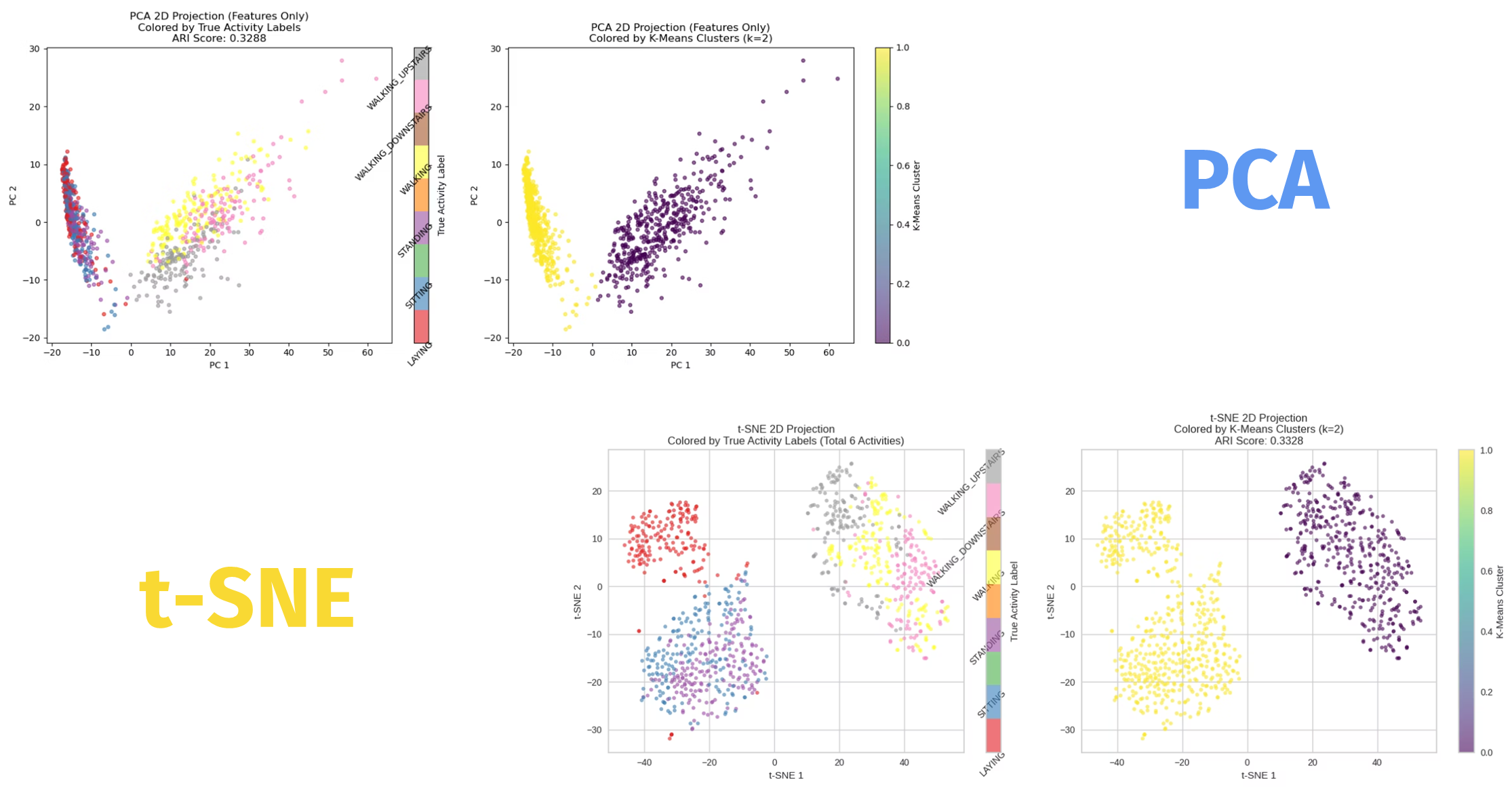
k=2는 정적인 행동과 동적인 행동을 크게 나누는 해석이 가장 잘 맞았다. 서비스 관점에서는 이게 중요하다. 왜냐하면 Move AI의 최종 목표는 세부 행동 이름을 완벽히 맞히는 것보다 “지금 사용자가 오래 안 움직이고 있는가”를 빠르게 판단하는 데 있었기 때문이다.
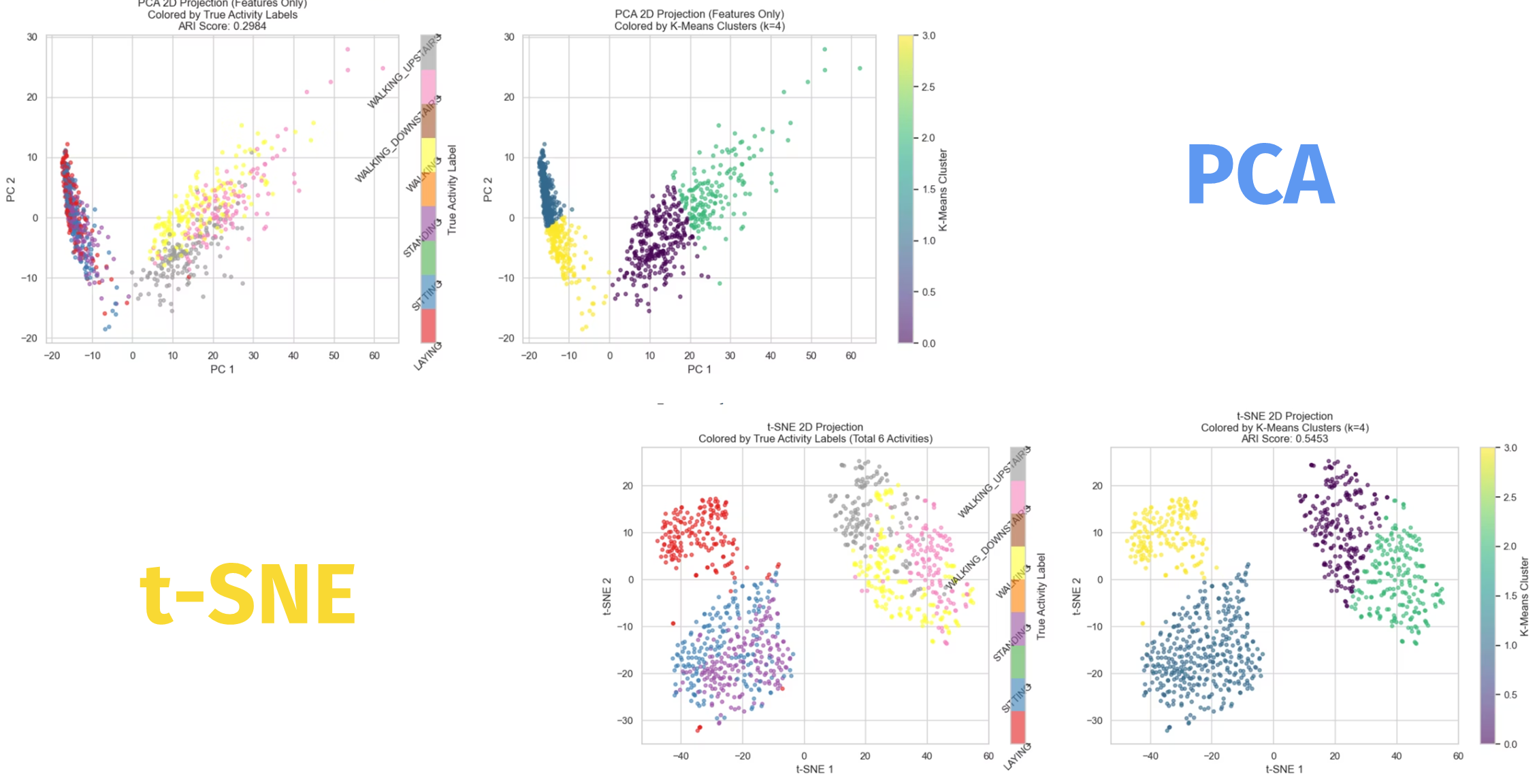
반면 k=4는 성능 지표 측면에서 가장 좋은 균형을 보였다. 발표 표에 따르면 차원 축소를 하지 않은 원본 기준에서도, PCA 10차원 기준에서도 ARI, V-measure, AMI 같은 주요 지표가 k=4에서 최고점을 기록했다. 프로젝트 팀은 이 결과를 바탕으로 “실제 정답 클래스 수가 더 많더라도, 데이터 구조를 통계적으로 가장 신뢰도 있게 재현하는 값은 k=4”라고 해석했다.
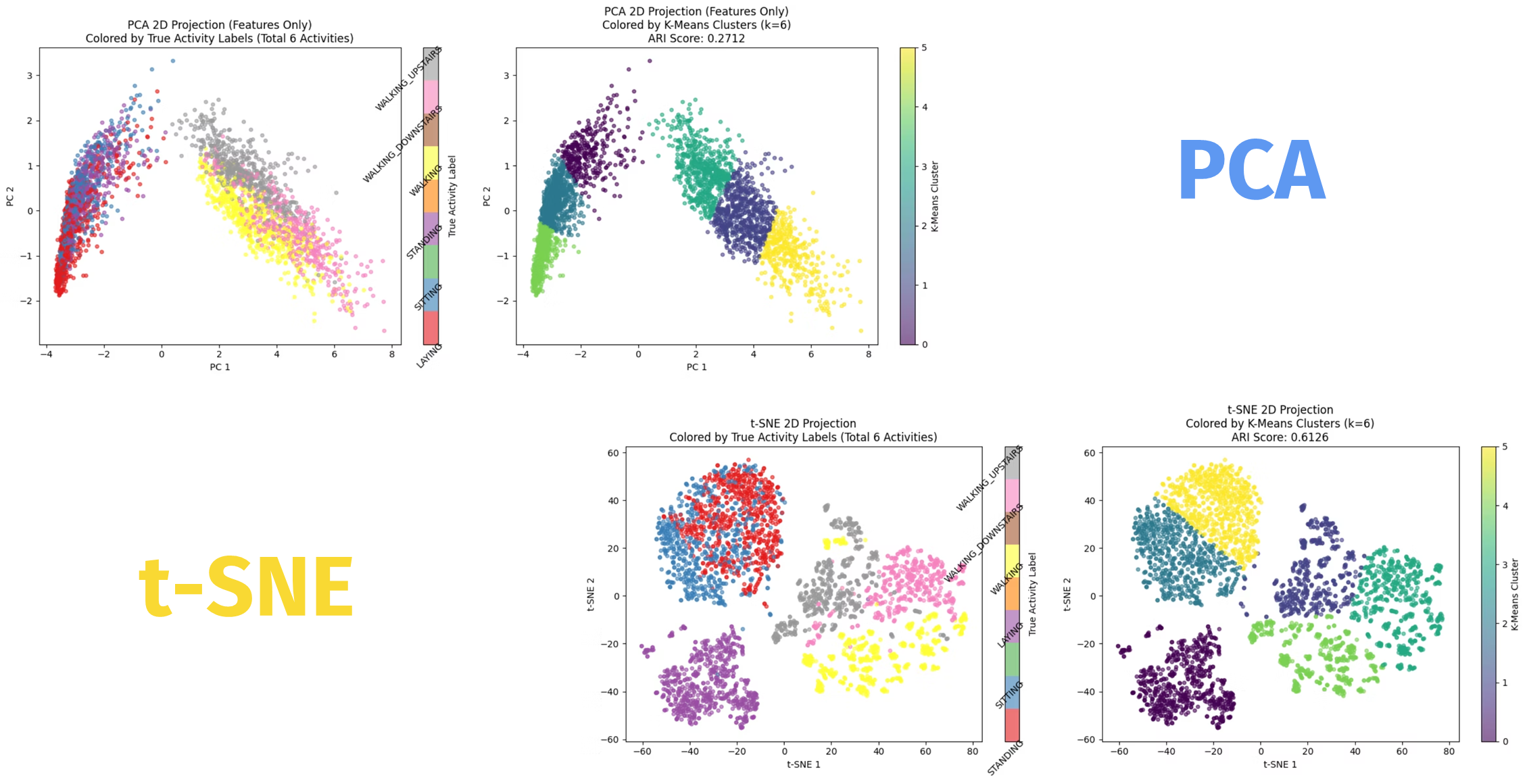
k=6은 언뜻 보면 실제 활동 종류 수에 더 가깝지만, 발표에서는 오히려 과잉 분할 가능성을 지적했다. 비슷한 행동들을 억지로 여러 그룹으로 찢으면서 완전성이나 응집도가 떨어질 수 있다는 해석이었다. 이 부분은 짧은 프로젝트에서도 “정답 클래스 개수와 최적 군집 개수는 항상 같지 않다”는 점을 잘 보여줬다.
모델 평가에서 무엇을 봤는가
이 프로젝트에서는 지표를 숫자 표로만 던지고 끝내지 않으려고 했다. 발표 자료에 각 평가지표가 뭘 뜻하는지도 같이 정리해 뒀다.
Inertia: 군집 내부 응집도Homogeneity: 한 군집이 하나의 정답 클래스에 얼마나 가깝게 묶이는지Completeness: 같은 정답 클래스가 한 군집으로 잘 모였는지V-measure: homogeneity와 completeness의 조화 평균ARI,AMI: 정답 라벨과 군집 결과의 유사도Silhouette: 각 점이 자기 군집에 얼마나 잘 속하는지
짧은 발표일수록 이런 설명이 빠지기 쉬운데, Move AI는 지표 의미를 먼저 설명한 뒤 결과를 해석했다. 그래서 “왜 k=4를 최종값으로 봤는가”가 단순 취향이 아니라 지표 기반 판단으로 보였다.
정리하면 이 프로젝트는 이렇게 결론을 나눠 볼 수 있다.
- 활동/비활동 이분화가 목적이면
k=2 - 패턴 설명력과 통계적 균형이 목적이면
k=4 - 차원 축소는
PCA 50차원이 시간과 성능 균형 면에서 유리 - 시각화는
t-SNE가 더 직관적
Random Forest를 함께 본 이유
발표 말미에는 Random Forest도 비교 대상으로 등장했다. 이 부분은 메인 결과라기보다, 비지도학습 결과를 지도학습 기준과 함께 바라보는 보조 관점에 가까웠다.
슬라이드에서는 Random Forest가 약 96% 정확도를 보였다고 정리되어 있었다. 즉, 라벨이 있는 상태에서 행동 분류를 수행하면 높은 성능이 가능하다는 점을 확인한 것이다.
이 비교가 의미 있었던 이유는 두 가지다.
K-Means는 패턴 탐색과 군집 구조 해석에 강점이 있다.Random Forest는 라벨 기반 분류 정확도를 확보하는 데 강점이 있다.
결국 실제 서비스에서는 둘을 섞어 생각할 수 있다. 예를 들어, 초기 탐색과 행동 패턴 묶음 정의는 클러스터링으로 하고, 실제 운영 단계에서는 지도학습 분류기로 안정적인 추론을 수행하는 식이다. 발표 자료가 이 가능성을 짧게라도 짚고 넘어간 점이 좋았다.
Move AI를 서비스로 보면 어떤 그림이었나
이 프로젝트를 단순 분석 과제로만 보면 “센서 데이터 군집화”에서 끝날 수 있다. 하지만 Move AI는 마지막 배포 슬라이드까지 포함해 보면 훨씬 서비스 지향적이었다.
핵심 아이디어는 이렇다.
- 사용자의 현재 상태를 활동/비활동으로 분류한다.
- 비활동이 일정 시간 이상 이어지면 개입 타이밍으로 판단한다.
- 너무 거창한 운동이 아니라, 바로 실행 가능한 작은 움직임을 제안한다.
이 접근이 현실적인 이유는 행동 변화의 진입 장벽이 낮기 때문이다. “30분 운동하세요”보다 “가까운 창가까지 걸어갔다 오세요”가 훨씬 실행 가능하다. 헬스케어 AI에서 중요한 것은 거대한 권고보다 실제 행동으로 이어지는 작은 유도일 때가 많다. Move AI는 바로 그 지점을 겨냥했다.
발표 현장
아래 사진은 Move AI 발표 당시 모습이다. 실제 발표 화면에는 프로젝트 제목, “일상생활 속 작은 움직임”이라는 부제, 그리고 팀 정보가 함께 표시되어 있었다.

간단한 HTML 데모도 같이 만들었다
프로젝트를 발표용 분석으로만 끝내지 않고, 실제로 비슷한 흐름을 바로 체험해 볼 수 있도록 간단한 HTML도 만들었다. 이 데모는 일정 시간 동안 마우스를 움직이지 않으면 구체적으로 어떤 운동이나 움직임을 하라고 알려주는 아주 단순한 형태로 구성되어 있다.
즉, 센서 기반 웨어러블 데이터를 그대로 재현한 것은 아니지만, Move AI가 지향한 핵심 경험인 “비활동 감지 → 즉시 행동 제안” 흐름을 웹에서 가볍게 확인해 볼 수 있게 만든 버전이라고 보면 된다.
첨부 자료
마무리
이번 미니 프로젝트는 이틀짜리 작업이었지만, 센서 데이터 분석에서 중요한 질문이 무엇인지 꽤 선명하게 보여줬다. 활동 분류 자체도 중요하지만, 더 중요한 것은 그 분류 결과를 실제 사용자 행동 변화로 어떻게 연결할 것인가였다.
Move AI는 바로 그 연결을 시도한 프로젝트였다. 클러스터링으로 활동 패턴을 읽고, 차원 축소와 평가 지표로 적절한 구조를 찾고, 마지막에는 사용자가 실제로 움직이게 만드는 작은 제안으로 이어 붙였다. 짧은 프로젝트였지만 문제 정의, 모델링, 해석, 서비스 연결까지 한 번에 경험해 볼 수 있었던 작업이었다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.