2025년 12월 29일, 30일, 31일 3일 동안 진행한
쓸AI기프로젝트는 폐기물 이미지를 보고organic과recyclable을 자동으로 분류하는 AI 솔루션을 기획하고 검증한 미니 프로젝트였다. 단순히 이미지 분류 모델 하나를 만드는 데서 끝나지 않고, 왜 이 문제가 중요한지, 어떤 모델이 실제 현장에 더 가까운지, 나중에 컨베이어 벨트와 웹캠 환경까지 확장할 수 있는지를 함께 다뤘다.
이번 프로젝트는 문제 진술 PDF에서 요구사항을 먼저 정리하는 것부터 시작했다. 폐기물을 더 정확하게 관리할 수 있도록 유기물과 재활용 가능 폐기물을 두 그룹으로 나누는 모델을 만들고, 최소 두 가지 이상의 모델 또는 방법론을 비교한 뒤, 기본 모델에 적용한 최적화 과정까지 설명해야 했다. 즉, 분류기 하나 돌려보는 데서 끝나는 과제가 아니라 고객을 설득할 만한 제안서와 결과물까지 내야 했다.
문제 정의: 왜 폐기물 분류 AI가 필요한가
문제 PDF는 먼저 폐기물 관리 자체가 왜 중요한지를 설명했다. 대부분의 폐기물은 여전히 매립지로 가고, 이 과정은 토지 오염, 수질 오염, 대기 오염, 독성 물질 노출 같은 문제로 이어진다. 그리고 서로 다른 종류의 폐기물을 잘못 섞으면 재활용 효율이 떨어질 뿐 아니라 이후 처리 비용도 커진다.
우리 팀이 발표에서 특히 강조한 논리는 5W1H의 Why였다. 우리가 만든 발표 자료에는 네 가지 관점이 들어갔다.
- 오염된 재활용품은 선별 비용을 크게 높인다.
- 폐기물 선별 현장은 인력난과 열악한 노동 환경 문제가 크다.
- 사람은 반복 작업에서 집중력이 떨어지지만, 기계는 일관성을 유지할 수 있다.
- 환경 규제는 점점 강화되고 있고, 분류와 추적 가능성은 더 중요해지고 있다.
발표용 Why를 뒷받침하기 위해 팀은 폴더 안의 보조 자료도 함께 참고했다.
2023년 전국 폐기물 발생 및 처리현황(요약본).pdf(붙임) 2025년 정부지원 환경사업 종합안내서.pdf
첫 번째 자료는 국내 폐기물 발생과 처리 현황의 규모를 확인하는 데 유용했다. 두 번째 자료는 정부 차원의 환경 정책과 지원 사업 흐름을 참고하는 데 사용했다. 발표 슬라이드에 숫자를 전부 직접 옮겨 적지는 않았지만, 프로젝트를 “그냥 이미지 분류 과제”가 아니라 실제 정책·산업 맥락 안의 문제로 설명하는 근거로 삼았다.
또 우리가 만든 발표 자료에는 직매립금지 관련 시각 자료도 포함했다.
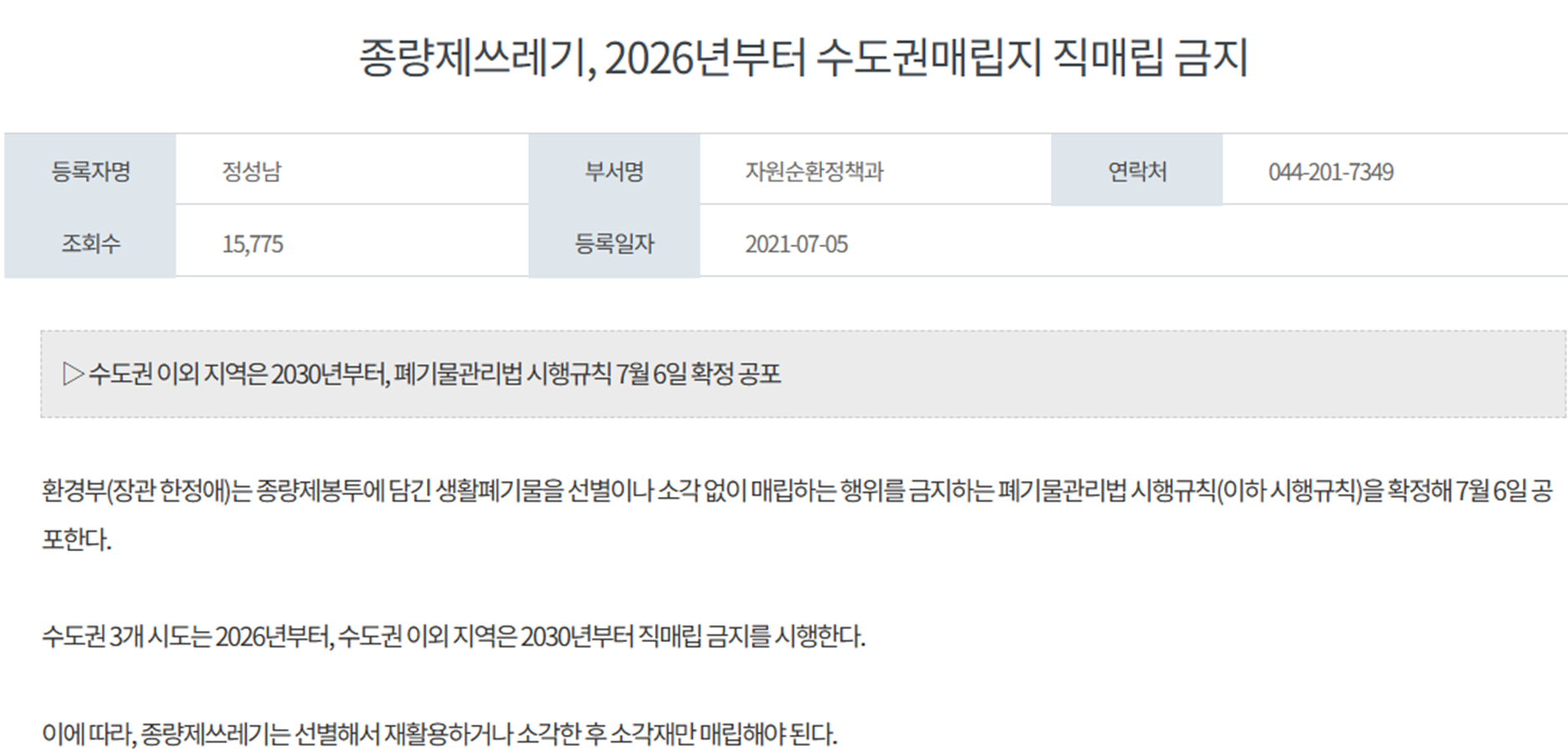
이 자료가 의미 있었던 이유는 명확하다. 분류가 잘못되면 처리 공정 전체의 효율이 떨어지고, 규제 대응 비용도 커진다. 결국 폐기물 자동 분류는 단순 편의 기능이 아니라 운영 효율, 비용, 안전, 규제 대응을 동시에 건드리는 문제였다.
5W1H로 정리한 서비스 그림
발표 자료의 5W1H 슬라이드는 프로젝트를 서비스 관점으로 바꾸는 데 큰 역할을 했다.
What: AI 기반 폐기물 자동 분류 시스템 구축Who: 폐기물 처리 업체, 재활용 센터, 지자체 환경 부서, 기업 시설 관리자Where: 재활용 센터, 처리 시설, 아파트 단지 수거 거점, 공장 폐기물 구역When: 가정·사무실·공공시설에서 폐기물이 배출되는 시점, 입고 전 선별 시점How: 데이터 수집, 모델 학습, 실시간 분류, 통계 모니터링, 피드백 기반 재학습
이 정리가 좋았던 이유는 모델 성능보다 먼저 “누가, 어디서, 왜 쓸 것인가”를 명확히 했기 때문이다. 특히 컨베이어 벨트 + 카메라 + AI 모델 + 운영 대시보드라는 운영 흐름까지 한 슬라이드 안에 정리해 두어서, 발표가 기술 데모에서 사업 제안서로 넘어갈 수 있었다.
3일 동안 실제로 진행한 일
발표 자료 기준 타임라인은 아래와 같았다.
2025년 12월 29일
- 16:00 ~ 17:30: 프로젝트 취지 논의 및 데이터 탐색
첫날은 데이터 자체를 보고, 문제를 어떻게 풀지 방향을 잡는 시간이었다. 과제 요구사항이 “모델 하나 제출”이 아니라 “비교와 최적화까지 설명”이었기 때문에, 초반부터 모델 선택 기준을 세우는 작업이 중요했다.
2025년 12월 30일
- 09:00 ~ 09:45: 노이즈 데이터 수동 제거 여부 논의
- 09:45 ~ 10:00: 어떤 요소가 성능에 가장 큰 영향을 주는지 탐색
- 10:00 ~ 12:30: 5가지 모델 비교
- 13:30 ~ 15:00: 모델 선정 및 optimizer 비교
- 15:00 ~ 16:30: optimizer 선정 및 learning rate 조정
- 16:30 ~ 17:00: 상용화 가능한 모델 구조 분석
둘째 날은 사실상 핵심 개발일이었다. 어떤 CNN 계열을 비교할지 정하고, 전처리와 증강, optimizer, scheduler 같은 실험 축을 빠르게 좁혀 갔다. 짧은 미니 프로젝트일수록 이런 의사결정 속도가 중요하다.
2025년 12월 31일
- 09:00 ~ 09:30: 중간 점검 및 결과 정리
- 09:30 ~ 15:30: PPT 제작 및 발표 연습
셋째 날은 결과를 해석 가능한 형태로 묶는 데 집중했다. 모델 성능 숫자만 보여주는 것이 아니라, 왜 그 모델을 택했고 실제 현장에서는 어떻게 써볼 수 있는지를 발표 스토리로 정리했다.
데이터 획득과 데이터셋 이해
프로젝트의 목표는 이미지 하나를 보고 그것이 organic인지 recyclable인지 분류하는 것이었다. 즉, 다중 클래스가 아니라 이진 분류 문제였다.
내가 발표 자료에 넣은 데이터셋 시각 자료는 아래와 같다.
이 문제에서 어려운 점은 클래스 이름이 단순한데 실제 이미지 난이도는 낮지 않다는 데 있다.
- 유기물은 색깔만으로 구분되지 않는다.
- 재활용품도 병, 캔, 플라스틱, 종이처럼 외형이 매우 다양하다.
- 오염되거나 찌그러진 상태에서는 물체 본래 형태가 손상된다.
- 배경이 더럽거나 여러 사물이 함께 찍힌 이미지가 많으면 분류가 더 어려워진다.
발표 자료에서도 이 점을 짚었다. 전통적 머신러닝처럼 사람이 특정 특징을 직접 뽑아 넣는 방식보다, CNN이 이미지에서 특징을 직접 추출하는 방향이 더 적합하다고 봤다.
왜 CNN 계열을 중심으로 봤는가
이미지 분류는 전통적 머신러닝으로도 시도할 수 있지만, 이 문제는 사람이 handcrafted feature를 만들기 어려운 유형이었다. 발표에서도 유기물과 재활용품 모두 “특별히 특징으로 구별하기 어렵다”는 식으로 정리했다.
예를 들어,
- 유기물이라고 해서 항상 갈색, 주황색만 갖는 것은 아니다.
- 재활용품이라고 해서 항상 차갑고 단단한 외형만 갖는 것도 아니다.
- 모양과 재질, 오염도, 구겨짐 정도가 모두 변수다.
결국 색 하나, 모양 하나만으로 설명할 수 없는 문제였고, 그래서 이미지 전체에서 지역적 특징을 학습하는 CNN 계열 모델 비교가 메인 실험이 됐다.
비교한 모델과 선정 근거
발표 자료에는 내가 비교 대상으로 정리한 5개 모델을 올렸다.
ResNet50V2MobileNetV3-SmallEfficientNet-B0ConvNeXt-TinyDenseNet201
선정 이유도 역할별로 분명히 나눴다.
ResNet50V2: 비교 기준이 되는 baselineMobileNetV3-Small: 저사양 장비나 edge 환경 적합성 확인EfficientNet-B0: 적은 연산량 대비 높은 성능의 효율성 검증ConvNeXt-Tiny: 최신 고성능 구조의 정확도 검증DenseNet201: 데이터가 부족하거나 특징이 모호할 때의 안정성 검증
즉, 아무 모델이나 끌어온 것이 아니라 “기준점”, “속도”, “효율”, “정확도”, “강건성”이라는 서로 다른 평가 축을 하나씩 대표하도록 모델을 골랐다. 짧은 발표에서 이런 선정 이유가 있으면 결과 해석이 훨씬 탄탄해진다.
1차 성능 비교와 최종 기본 모델 선택
초기 비교 결과를 바탕으로 최종 기본 모델은 EfficientNet-B0로 결정했다. 발표 자료의 요지는 이렇다.
epoch=5기준 성능이 높았던 상위 3개 모델 중 하나였다.- 그중에서도
training time이 가장 짧았다. - 성능과 속도를 함께 보면 가장 균형이 좋았다.
모델 비교 결과를 발표용으로 정리한 이미지도 남겨 두었다.
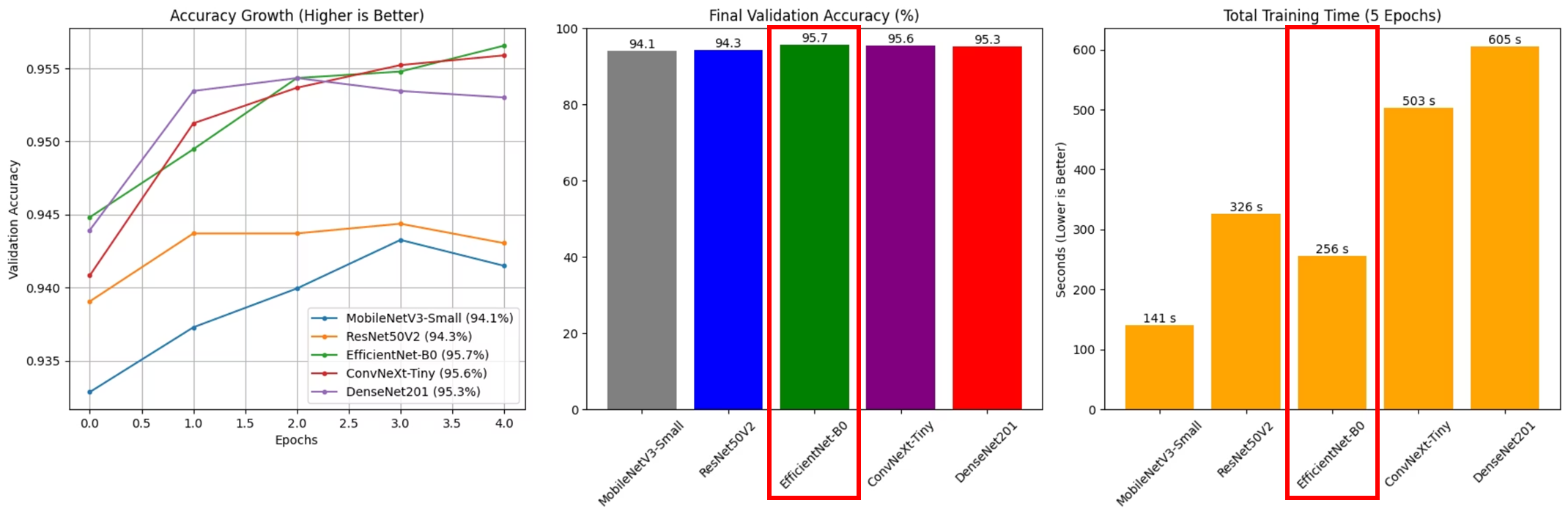
개인적으로 이 선택이 납득됐던 이유는, 이 프로젝트가 연구용 최고 성능보다 실제 현장 적용 가능성을 더 중요하게 봤기 때문이다. 폐기물 분류는 결국 엣지 장비나 저사양 환경과도 연결될 가능성이 높아서, 무조건 가장 큰 모델이 항상 정답은 아니다.
전처리: RGB, HSV, Gray를 왜 비교했는가
둘째 날 실험에서 핵심 중 하나는 입력 이미지 표현 방식을 비교한 것이었다. 발표 자료에는 내가 정리한 RGB vs HSV vs Gray 비교가 따로 들어가 있었다.
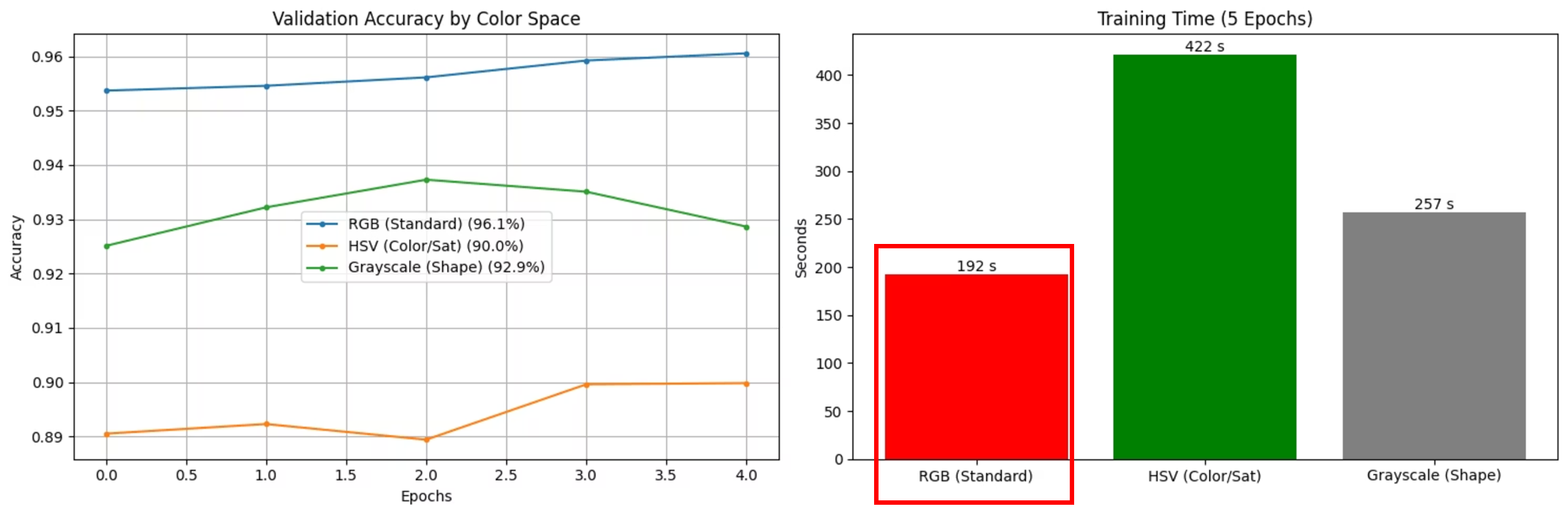
발표 내용을 정리하면 각 방식의 포인트는 이렇다.
RGB: 일반적인 딥러닝 입력 방식이지만 밝기 변화가 세 채널에 동시에 영향을 준다.HSV: 색상, 채도, 명도를 분리해서 다루므로 밝기 변화에 더 강하다.Gray: 색 정보를 버리고 구조와 윤곽에 집중할 수 있어 연산이 빠르다.
이 비교가 중요했던 이유는 폐기물 분류가 조명, 배경, 오염도에 민감한 문제이기 때문이다. 플라스틱 병이 밝은 조명 아래에서 하이라이트를 강하게 받거나, 음식물 쓰레기가 어두운 조명 아래에서 뭉개져 보이면 입력 표현 방식의 차이가 성능에 영향을 줄 수 있다.
데이터 증강 실험
발표 자료는 증강 전략도 세 단계로 나눠 설명했다.
No_Aug: 증강 없음Light_Aug: 좌우 반전, 10도 회전, 상하좌우 10% 이동Heavy_Aug: 상하 반전, 40도 회전, 줌, 전단 변환, 밝기 변화 포함
이 프로젝트는 최고 점수 하나만 보고 결론을 내리지는 않았다.
Light_Aug는 현재 데이터의 본질적 형태를 해치지 않으면서 일반화 성능을 끌어올렸다.Heavy_Aug는 점수가 더 낮게 나올 수 있어도, 실제 현장처럼 물체가 찌그러지거나 일부만 보이는 상황에는 더 강할 수 있다.
즉, “실험실 성능”과 “현장 강건성”을 분리해서 봤다. 이 태도가 좋았다. 미니 프로젝트에서는 보통 가장 높은 숫자 하나만 선택하고 끝내기 쉬운데, 여기서는 실제 배포 환경에서 어떤 변형이 발생하는지까지 고려했다.
Optimizer와 Learning Rate Scheduler 비교
모델을 고른 뒤에는 학습 전략을 좁혀 갔다. 발표 자료에는 내가 넣은 optimizer 비교 슬라이드와 learning rate scheduler 비교 슬라이드가 따로 있었다.
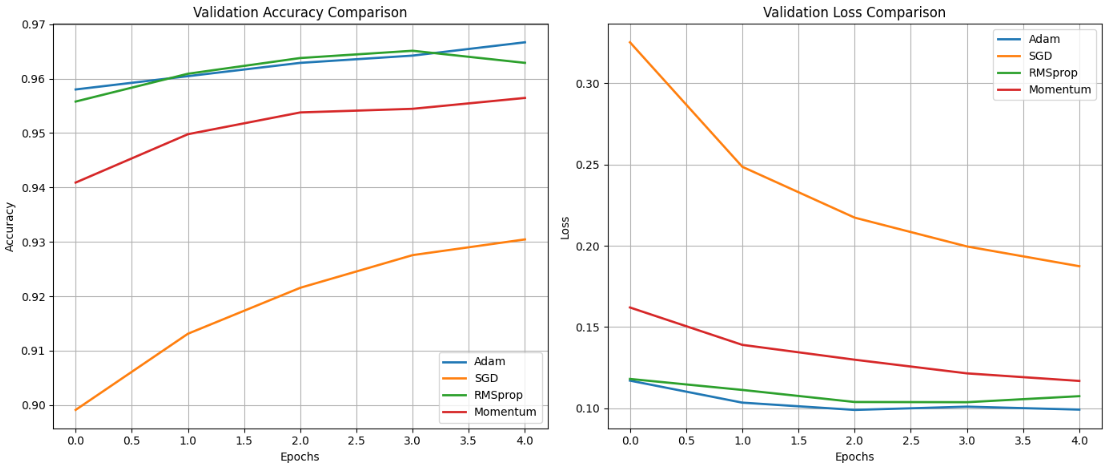
scheduler 쪽에서는 두 전략을 비교했다.
ReduceLROnPlateau: 검증 성능이 정체되거나 나빠질 때 반응적으로 학습률을 낮춤Cosine Annealing: 미리 정해진 코사인 곡선에 따라 부드럽게 학습률을 낮춤
발표 정리 기준 최종 선택은 아래와 같았다.
- 모델:
EfficientNet-B0 - 데이터 증강:
Light_Aug - Optimizer:
Adam - LR Scheduler:
CosineAnnealing - Epochs:
20
이 조합은 “속도와 안정성을 갖춘 효율형 모델”에 “과하지 않은 증강”과 “무난한 최적화 전략”을 붙인 구성이었다. 짧은 프로젝트에서 지나치게 복잡한 튜닝보다 재현 가능하고 설명 가능한 설정을 택했다는 점에서 합리적이었다.
최종 분류 성능과 혼동행렬 해석
나는 발표 자료에서 최종 성능을 설명하면서 Precision, Recall, F1-score를 직관적으로 풀어 설명했다. 특히 epoch=5 기준 혼동행렬을 통해 모델이 얼마나 안정적으로 분류하는지 보여줬다.
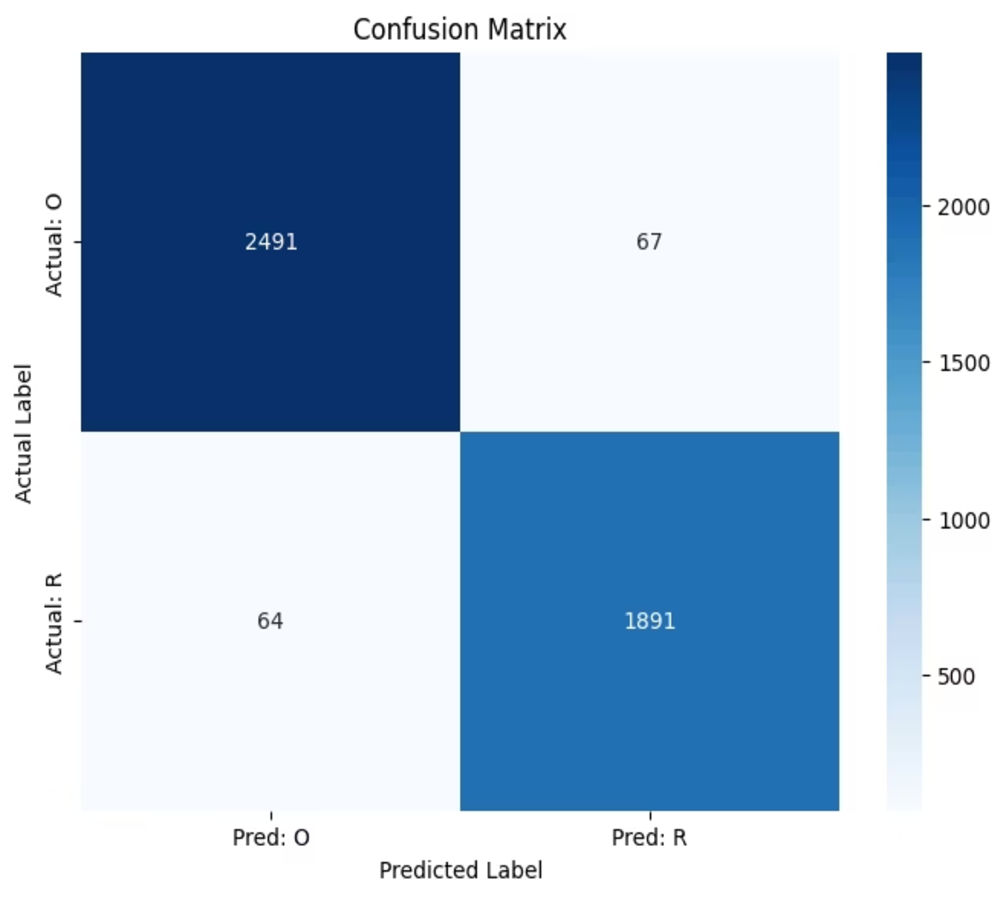
슬라이드 해석을 정리하면 다음과 같다.
- 정밀도 약
0.97: “유기물이다”라고 예측했을 때 실제로 맞을 확률이 매우 높다. - 재현율 약
0.97: 실제 유기물 중 대부분을 놓치지 않고 잡아낸다. - F1-score 약
0.97: 정밀도와 재현율이 모두 균형 있게 높다.
이 점수가 의미 있는 이유는 어느 한쪽으로 치우친 모델이 아니라는 데 있다. 예를 들어, 유기물을 거의 다 잡아내지만 재활용품도 자꾸 유기물로 오판하는 모델이라면 정밀도와 재현율 사이에 큰 차이가 날 수 있다. 그런데 이번 결과는 두 지표가 모두 높아서, 발표에서 말한 것처럼 “균형 잡힌 성능”이라고 설명하기 좋았다.
여기서 끝나지 않고 YOLO까지 본 이유
이 프로젝트가 흥미로운 지점은 여기서 분류 모델만 끝내지 않았다는 데 있다. 발표 후반부에는 컨베이어 벨트 같은 실제 환경에서 활용 가능한 실시간 분류 모델 방향도 다뤘다.
핵심 아이디어는 이랬다.
- 이미지 분류는 한 장의 이미지 전체를 보고
organic/recyclable을 맞춘다. - 하지만 실제 현장에서는 한 프레임 안에 여러 물체가 있고, 위치도 알아야 한다.
- 그래서 객체 탐지 기반 접근이 필요하다.
이를 위해 YOLOv8 pre-trained 모델을 사용해 바운딩 박스를 자동 생성하고, 새 모델 학습용 라벨로 활용하는 아이디어를 발표 자료에 넣었다. 즉, 수만 장의 박스를 사람이 수동으로 그리는 대신, pre-trained detector로 자동 라벨링을 수행하는 흐름이었다.
물론 한계도 분명히 짚었다.
- pre-trained 모델이 틀리면 잘못된 박스가 라벨로 저장된다.
- 그러면 새 모델이 그 noise까지 학습할 수 있다.
발표에서는 이 한계까지 숨기지 않고 적었다. 이런 식의 정직한 기술 설명이 오히려 발표를 더 신뢰하게 만든다.
왜 YOLOv8n이었는가
발표 자료에는 YOLO 계열 비교 표와 YOLOv8n.pt 설명도 함께 넣었다.
YOLOv8n은 Nano 버전이라 모델이 매우 작고 빠르다. 발표에서 이 버전을 선택한 이유는 명확하다.
- 실시간 웹캠, 모바일, CCTV 같은 환경과 더 잘 맞는다.
- 빠른 추론 속도가 중요하다.
- 미니 프로젝트 단계에서 상용 가능성을 검토하기에 부담이 적다.
발표 자료에는 기존 사진에서 객체를 탐지하는 예시와, 학습 완료된 best.pt를 웹캠 프레임에 바로 적용하는 코드 흐름도 넣었다. cv2.VideoCapture(0)로 프레임을 받고, YOLO("best.pt").predict()로 추론한 뒤, 결과 박스와 클래스 라벨을 화면에 오버레이하는 구조였다.
즉, 이 프로젝트는 “이미지 분류 정확도 실험”으로 시작했지만, 마지막에는 “실시간 선별 설비에 붙일 수 있는가”라는 질문까지 갔다.
현장에서 바로 걸릴 문제: 조도 변화와 오인식
발표 자료 후반부에서는 에러를 그냥 넘기지 않고 현장 문제로 다시 묶었다. 해당 슬라이드에는 아래 내용이 정리돼 있었다.
- 밝기가 올라가면
recyclable객체를organic으로 오인식하는 오류가 발생했다. - 원인은 모델의 밝기 변화 대응력 부족으로 해석했다.
- 대응책으로는 다양한 밝기 조건을 포함하는 데이터 증강과 재학습을 제시했다.
이 해석은 앞서 RGB/HSV/Gray 비교와 증강 실험을 왜 했는지 다시 설명해 준다. 폐기물 선별은 통제된 스튜디오 환경이 아니라 조도 변화, 배경 오염, 부분 가림이 많은 환경에서 이뤄질 가능성이 높다. 결국 실제로 중요한 것은 최고 점수 하나보다 이런 변화에 얼마나 덜 흔들리는가다.
발표 자료에 들어간 툴과 협업 방식
발표 자료에는 사용한 도구도 같이 정리해 뒀다.
- 개발 환경:
Kaggle Notebook,VS Code,Anaconda - 발표/문서:
Microsoft PPT,Google Drive - 라이브러리:
Ultralytics,PyTorch,OpenCV,Scikit-learn,Matplotlib,Seaborn,Pandas,Numpy,YAML - 협업/버전 관리:
Discord,GitHub,Git,Google Drive
짧은 기간이었지만 구성은 꽤 현실적이었다. 실험은 노트북 환경에서 빠르게 돌리고, 발표 자료는 Drive와 PPT로 묶고, 코드와 협업은 GitHub와 Discord로 이어가는 구조였다. 작은 팀 프로젝트에서 자주 쓰는 조합이지만, 발표 자료에 이런 도구 구성을 명시해 두면 우리가 어떤 흐름으로 작업했는지가 더 잘 보인다.
폴더 안에 남겨 둔 이미지들
reference/capstone/3 폴더에는 발표용 시각 자료 외에도 결과물 제작 과정에서 쓴 이미지들이 들어 있었다.
Code_Generated_Image (1).pngCode_Generated_Image (2).pngimage-Photoroom.pngimage.png
이 파일들은 결과 설명이나 시연 화면을 정리하는 과정에서 만든 보조 시각 자료로 보관해 두었다. 프로젝트 본질은 모델링과 발표였지만, 마지막 산출물을 보여줄 때는 이런 정리용 이미지가 꽤 중요했다.
예시 이미지는 아래처럼 따로 남겨 둘 수 있다.

발표 자료와 문제 정의 PDF
프로젝트 전체 스토리를 이해하려면 문제 정의 PDF와 최종 발표 자료를 같이 보는 편이 좋다.
첨부 자료
프로젝트 문제 정의와 최종 발표 자료는 아래에 같이 정리해 둔다.
마무리: 발표에서 영상까지
이 프로젝트는 단순히 “폐기물 이미지를 분류했다”에서 끝나지 않았다. 문제 정의를 읽고, 왜 이 문제를 풀어야 하는지 근거를 만들고, 여러 CNN 계열 모델을 비교하고, 전처리와 증강과 optimizer와 scheduler를 조정하고, 마지막에는 YOLO 기반 실시간 활용 가능성까지 확장해 보는 흐름으로 진행됐다.
아래 사진처럼 발표 준비와 시연 과정을 거쳐,

최종적으로는 이런 결과물을 영상 형태로도 정리해 냈다.
3일짜리 미니 프로젝트였지만, 문제 정의, 데이터 탐색, 모델 비교, 최적화, 현장 적용 가능성, 발표용 스토리텔링까지 짧은 시간 안에 한 번에 경험해 볼 수 있었던 작업이었다. 특히 이번 프로젝트는 “좋은 모델”을 만드는 것만큼이나 “왜 이 모델이 현실 문제를 푸는 데 의미가 있는가”를 설명하는 일이 중요하다는 걸 다시 확인하게 해 줬다.
덤으로 만든 사람 감지 HTML
캡스톤 본편과는 별개로, 그냥 재미로 웹캠에서 사람을 감지해보는 HTML도 하나 만들어뒀다. TensorFlow.js와 COCO-SSD를 붙여서 브라우저에서 바로 켜볼 수 있는 가벼운 실험 파일이다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.