2025년 12월 8일과 12월 9일, 이틀 동안 Rossmann 매장 데이터를 바탕으로 “매출에 영향을 주는 특성이 무엇인지”를 찾고, 마지막에는 실제로 쓸 수 있는 매출 증대 방안까지 제안하는 미니 프로젝트를 진행했다.
이번 프로젝트는 store.csv와 train.csv 두 개의 파일을 중심으로 진행했다. 발표 자료를 만들 때 다시 정리해 보니, 단순히 예측 모델 점수를 비교하는 과제가 아니라 “어떤 특성이 매출을 움직이는가”를 설명하고, 그 설명을 바탕으로 실행 가능한 액션을 제안하는 과제에 더 가까웠다.
프로젝트 과제와 데이터
과제 PDF 기준으로 내가 해야 할 일은 명확했다.
- Rossmann 매장 데이터를 탐색한다.
- 매출에 영향을 주는 특성을 찾는다.
- 여러 모델을 비교해 본다.
- 마지막 발표에서는 매출 증대 방안을 제안한다.
데이터 구조도 꽤 명확했다.
store.csv: 1,115개 매장의 고정 정보train.csv: 1,017,209건의 일자별 매출 기록
train.csv에는 Sales, Customers, Open, Promo, StateHoliday, SchoolHoliday 같은 일별 운영 정보가 있고, store.csv에는 StoreType, Assortment, CompetitionDistance, Promo2 같은 매장 속성이 들어 있었다. 두 파일을 합치면 “매장의 고정 특성 + 날짜별 운영 조건”을 함께 볼 수 있어서, 매출 영향 요인을 해석하기 좋은 구조였다.
참고로 전체 train.csv를 기준으로 보면 운영일(Open=1) 비율은 약 83.0%, 프로모션 진행 비율은 약 38.2%, 학교 휴일 비율은 약 17.9%였다. 발표를 준비하면서 다시 보니, 이 기본 분포만으로도 Rossmann 매출이 단순 상시 매출이 아니라 운영 상태와 행사 여부에 꽤 크게 반응하는 데이터라는 점이 보였다.
이틀 동안 실제로 한 작업
프로젝트 진행 흐름은 생각보다 정석적이었다. 다만 시간 제한이 짧아서, “완벽한 분석”보다 “설명 가능한 분석”에 더 집중했다.
1일 차에는 데이터 탐색과 전처리에 대부분의 시간을 썼다.
store.csv와train.csv의 컬럼 의미를 먼저 정리했다.- 결측치와 이상치를 확인했다.
store기준으로 데이터를 merge했다.- 날짜에서
Year,Month,Day,WeekOfYear,Quarter,IsMonthEnd같은 파생 변수를 만들었다. - 경쟁점 오픈 기간과
Promo2지속 기간 같은 기간형 변수도 추가했다.
내가 발표 자료에 정리한 기준 중 특히 중요했던 것은 아래와 같다.
Open=0인데 매출이 0인 행은 영업하지 않은 날로 보고 분석 대상에서 조정했다.Promo2=0일 때 관련 컬럼이 비어 있는 것은 결측이라기보다 “장기 프로모션 미참여” 상태로 해석했다.CompetitionDistance가 비어 있는 일부 매장은 경쟁 매장 정보가 없는 케이스로 따로 다뤘다.Sales상위 구간은 boxplot 기준으로 튀어 보였지만, 실제 이벤트성 고매출일 수 있다고 보고 무조건 제거하지 않았다.
2일 차에는 인사이트 정리, 모델 비교, 발표 자료 구조화에 집중했다. 툴은 Tableau, Jupyter Notebook, pandas, scikit-learn 계열과 함께 XGBoost, LightGBM, CatBoost, RandomForest, MLP, LSTM까지 폭넓게 써 봤다. 발표 주제가 “매출 영향 특성 항목 찾기”였기 때문에, 모델 점수만 보는 대신 feature 관점 설명을 PPT의 중심으로 잡았다.
EDA에서 먼저 확인한 그래프들
처음에는 모델부터 돌리고 싶었지만, 발표를 준비하는 입장에서는 데이터의 모양을 먼저 이해하는 게 훨씬 중요했다. 특히 Sales, Customers, CompetitionDistance는 분포가 한쪽으로 치우쳐 있을 가능성이 높아서 boxplot으로 먼저 확인했다.
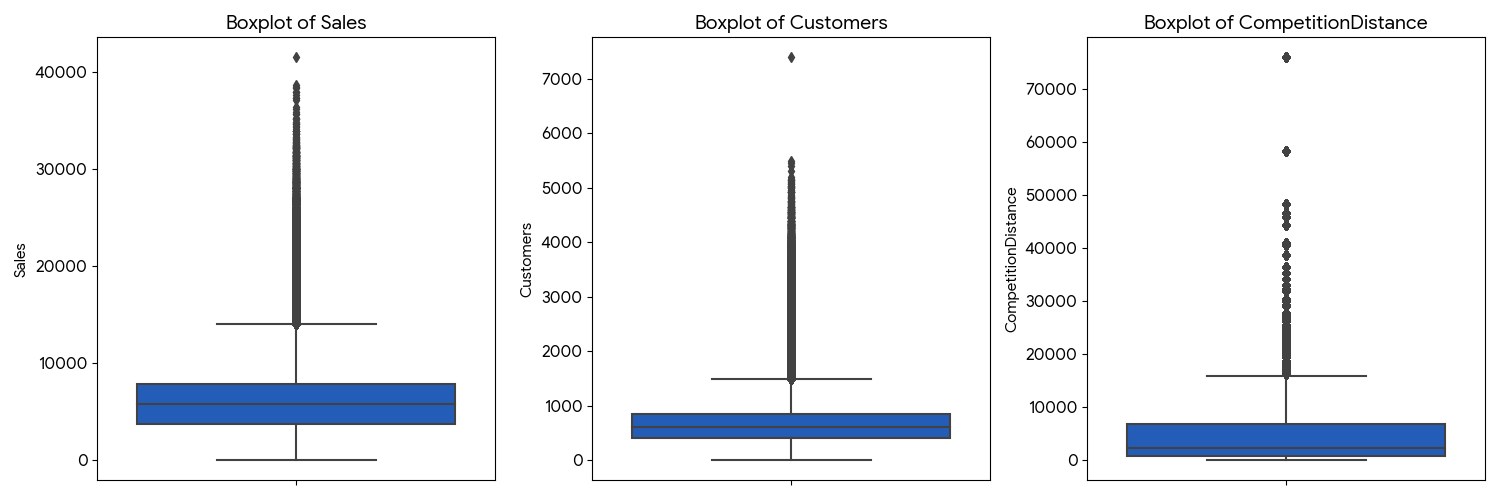
이 그래프에서 바로 보였던 건 세 가지였다.
Sales는 상단 이상치가 매우 많다.Customers도 일부 날짜에 매우 큰 값이 튄다.CompetitionDistance는 긴 꼬리를 가진 분포다.
처음에는 상위 구간을 전부 이상치로 잘라내고 싶은 유혹이 있었다. 그런데 발표 자료를 정리하면서 다시 생각해 보니, 이 값들은 단순 오류라기보다 실제 이벤트성 매출, 대형 매장 효과, 혹은 특정 상권 조건을 반영하는 값일 가능성이 높았다. 그래서 이번 프로젝트에서는 “무조건 제거”보다 “왜 튀는지 설명 가능한가” 쪽으로 접근했다.
특히 Sales boxplot의 상단 구간은 오히려 중요한 힌트였다. Rossmann 같은 리테일 데이터에서는 평소 매출만 보는 것보다, 고매출이 발생하는 상황을 이해하는 것이 매출 증대 전략에 더 직접적으로 연결된다. 그래서 이 이상치들을 노이즈라기보다 “운영 이벤트가 강하게 작동한 날”로 보고 해석하기로 했다.
Promo2 PNG에서 읽은 인사이트
별도로 정리해 둔 Promo2.png도 발표 흐름을 만드는 데 도움이 컸다. 이 이미지는 단순히 Promo2를 했는지 안 했는지를 보는 수준을 넘어서, StoreType과 묶어서 봤을 때 어떤 차이가 나는지를 보여준다.
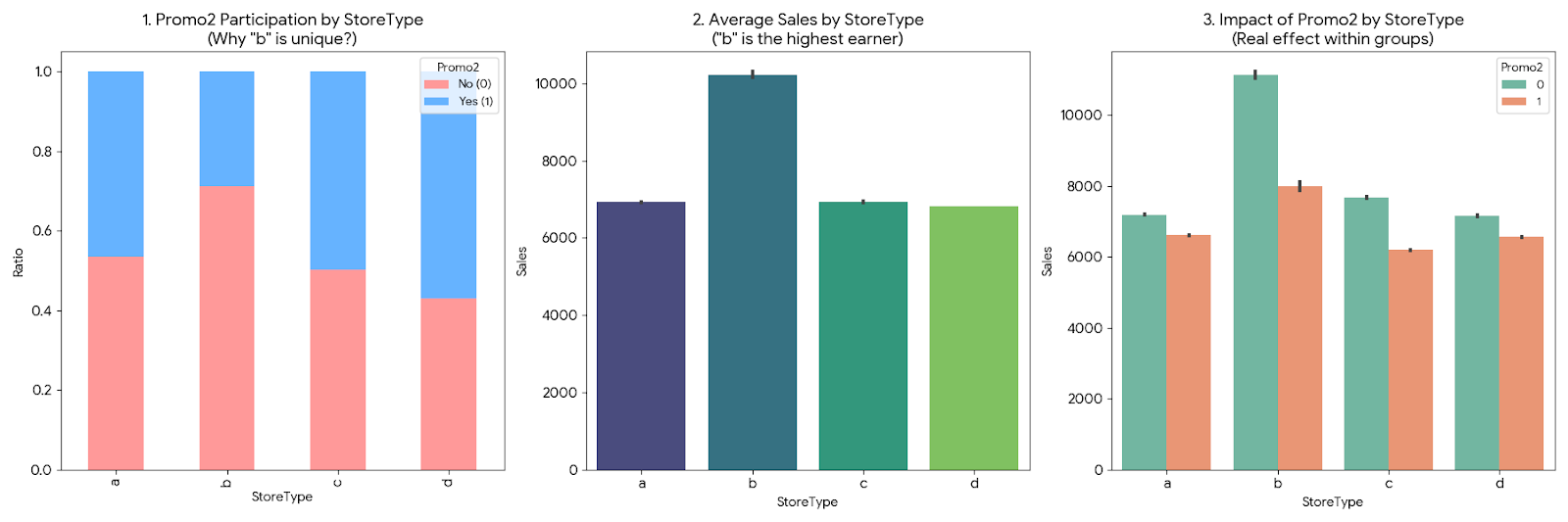
왼쪽 그래프는 StoreType별 Promo2 참여 비율이다. 여기서 바로 보이는 건 b 타입 매장이 다른 타입보다 참여 패턴이 다르다는 점이었다. 가운데 그래프는 StoreType별 평균 매출인데, b 타입이 가장 높은 매출을 만들고 있다. 오른쪽 그래프는 같은 StoreType 내부에서 Promo2 유무에 따라 매출이 어떻게 달라지는지를 보여준다.
이 그림을 보면서 정리한 해석은 이랬다.
StoreType자체가 이미 매출 수준을 크게 나누는 변수다.Promo2의 효과는 전체 평균으로 보면 평평하게 보일 수 있지만, 그룹 내부로 들어가면 차이가 생긴다.- 따라서 프로모션 전략은 전체 일괄 적용보다
StoreType별 설계가 훨씬 합리적이다.
이 부분은 나중에 매출 증대 방안을 제안할 때도 그대로 연결됐다. “Promo2를 더 하자”가 아니라, “어떤 매장 유형에 어떤 장기 프로모션이 유리한가”로 질문을 바꾸게 된 계기였다.
Random forest-2.ipynb에서 실제로 본 코드
이번에 사용한 노트북 중 하나가 Random forest-2.ipynb였다. 제목 그대로 Random Forest를 중심으로 성능을 보고, feature importance와 가상 시나리오 분석까지 이어지는 구조였다. 전체 코드를 다 옮길 필요는 없지만, 발표에 직접 반영한 핵심 셀은 아래 흐름으로 정리할 수 있다.
먼저 타깃과 입력 데이터를 나누고, 범주형 컬럼을 더미 변수로 바꿨다.
TARGET = "Sales"
X = df.drop(columns=[TARGET])
y = df[TARGET]
cat_cols = X.select_dtypes(include="object").columns
X = pd.get_dummies(
X,
columns=cat_cols,
drop_first=True
)
X.columns = [
re.sub(r'[\[\]<]', '_', str(col))
for col in X.columns
]여기서 눈에 띄는 점은 PromoInterval, PromoList 같은 범주형 컬럼이 실제로 one-hot encoding 대상이었다는 것이다. 발표 자료를 만들 때는 간단히 “범주형 처리 후 학습” 정도로 말했지만, 실제 노트북에서는 모델이 먹을 수 있는 입력 형태로 꽤 꼼꼼하게 정리하고 있었다.
학습 자체는 아래처럼 비교적 정석적인 Random Forest 설정으로 진행했다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
rf_model = RandomForestRegressor(
n_estimators=300,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
random_state=42,
n_jobs=-1
)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)성능 지표는 아래처럼 계산했다.
rf_rmse = np.sqrt(mean_squared_error(y_test, rf_pred))
rf_mae = mean_absolute_error(y_test, rf_pred)
rf_r2 = r2_score(y_test, rf_pred)
print("Random Forest")
print(f"RMSE : {rf_rmse:.4f}")
print(f"MAE : {rf_mae:.4f}")
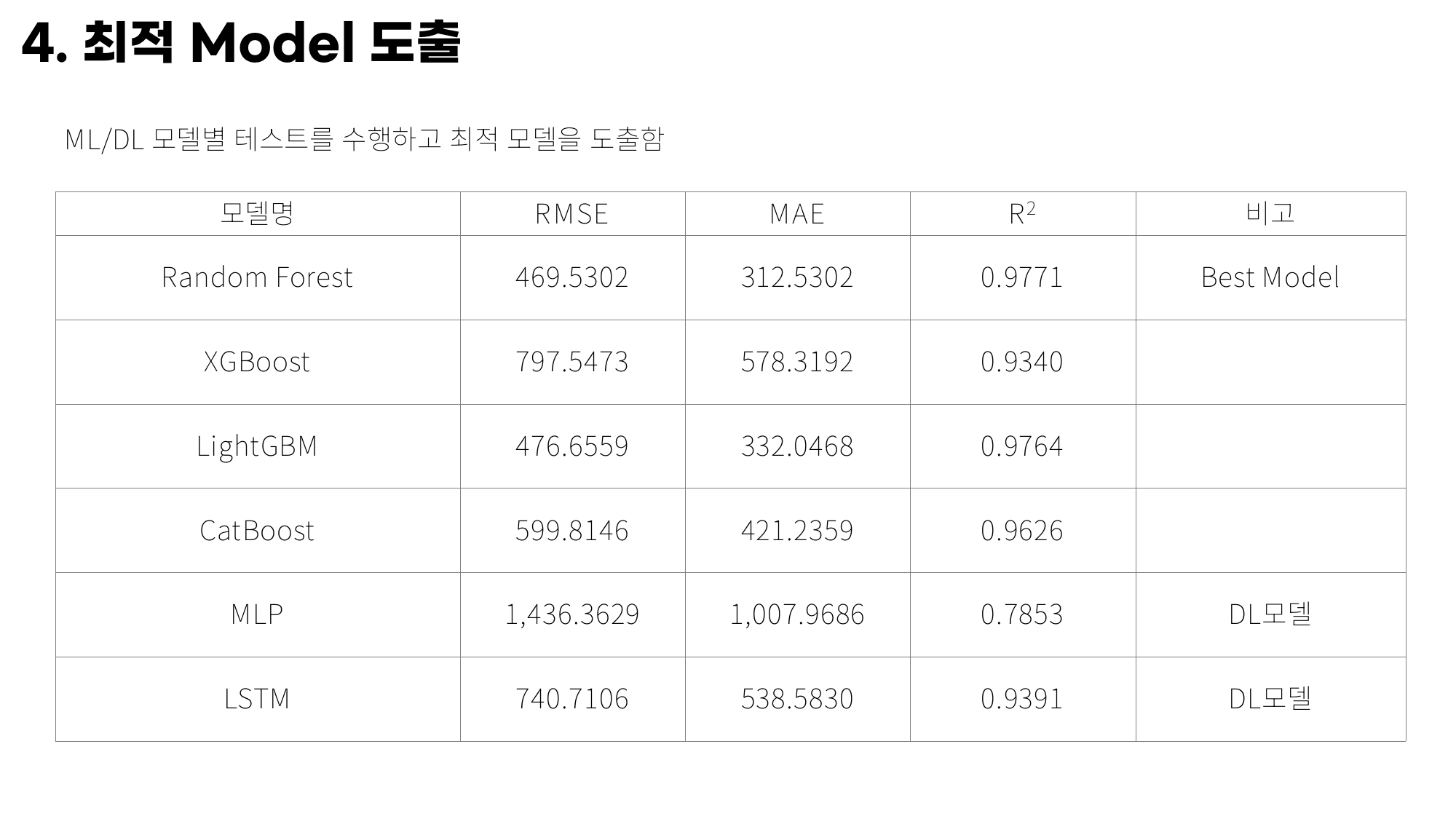
print(f"R^2 : {rf_r2:.4f}")발표 자료 기준 결과는 RMSE 469.5302, MAE 312.5302, R² 0.9771이었다. 이 수치만 놓고 봐도 Random Forest가 꽤 강했지만, 실제로 발표에서 더 유용했던 건 뒤쪽에 붙어 있는 해석용 셀들이었다.
Random Forest 결과를 어떻게 읽었는가
노트북에는 단순 예측 성능뿐 아니라, 실제값-예측값 산점도, 잔차 분포, 중요 변수 시각화, 깊이별 성능 확인 그래프가 들어 있었다. 내가 발표 PDF에 넣은 슬라이드를 기준으로 보면 당시 어떤 그림을 핵심으로 골랐는지 더 잘 드러난다.
이 슬라이드에서 내가 중요하게 봤던 포인트는 네 가지였다.
- 실제값과 예측값 산점도가 대각선에 비교적 잘 붙어 있다.
- 잔차가 완벽히 고르지는 않지만 대체로 설명 가능한 수준이다.
- 깊이를 늘릴수록 성능이 올라가다가 안정화된다.
- feature importance에서
Customers가 압도적으로 높다.
노트북 출력값 기준 top feature importance는 아래 순서였다.
이 결과를 보고 가장 먼저 든 생각은 “고객 수가 중요하다”라는 너무 당연한 결론이 아니라, 그 다음 줄에 있는 변수들이었다. StoreType, CompetitionDistance, Promo, Assortment가 모두 상위권에 있다는 건, Rossmann 매출이 단지 유입량만의 함수가 아니라 매장 포지셔닝과 경쟁 환경, 판촉 운영의 영향을 함께 받는다는 뜻이다.
노트북에 들어 있던 시나리오 분석
이 노트북이 좋았던 이유는 여기서 끝나지 않고, 모델을 가지고 직접 시나리오를 돌려 봤다는 점이다. 발표에서는 이 부분이 “실무에 가까운 제안”처럼 보이게 만드는 역할을 했다.
예를 들어 CompetitionDistance는 아래처럼 평균적인 기준 매장을 하나 만들고, 경쟁점 거리를 바꿔 가며 예측값을 보는 방식으로 테스트했다.
base_row = X_train.mean().to_frame().T
cd_min = X_train["CompetitionDistance"].quantile(0.05)
cd_max = X_train["CompetitionDistance"].quantile(0.95)
cd_values = np.linspace(cd_min, cd_max, 50)
scenario_df = pd.concat([base_row] * len(cd_values), ignore_index=True)
scenario_df["CompetitionDistance"] = cd_values
scenario_pred = rf_model.predict(scenario_df)출력값 일부를 보면 경쟁점 거리가 매우 가까운 구간과 조금 떨어진 구간의 예측 매출이 꽤 다르게 나타났다.
130m부근:5181.14543m부근:6939.92956m부근:4139.96
완벽한 단조 관계라기보다, 특정 거리 구간에서 민감하게 반응하는 비선형 패턴에 가까웠다. Random Forest가 이런 비선형 관계를 꽤 잘 잡아낸다는 점도 흥미로웠다.
Promo 효과는 더 직관적이었다.
scenario_promo = pd.concat([base_row, base_row], ignore_index=True)
scenario_promo.loc[0, "Promo"] = 0
scenario_promo.loc[1, "Promo"] = 1
promo_pred = rf_model.predict(scenario_promo)노트북 출력은 아래처럼 나왔다.
Predicted Sales: 2883.783333
Predicted Sales: 7368.650000
차이는 무려 4484.87이었다. 물론 평균 매장 1개를 기준으로 한 시뮬레이션이라 과장될 수는 있다. 그래서 노트북에서는 X_test에서 200개 샘플을 뽑아 다시 비교했고, 그 평균 효과는 약 830.71로 나왔다. 나는 오히려 이 두 숫자를 같이 보는 게 중요하다고 느꼈다. 프로모션 효과는 분명 존재하지만, 매장 조건에 따라 그 크기가 크게 달라진다는 뜻이기 때문이다.
Random Forest 시나리오 슬라이드도 같이 넣은 이유
발표 PDF에는 Random Forest 기준 시나리오를 한 장으로 정리한 슬라이드가 들어 있었다. 이건 발표용으로 아주 유용한 장표였다.
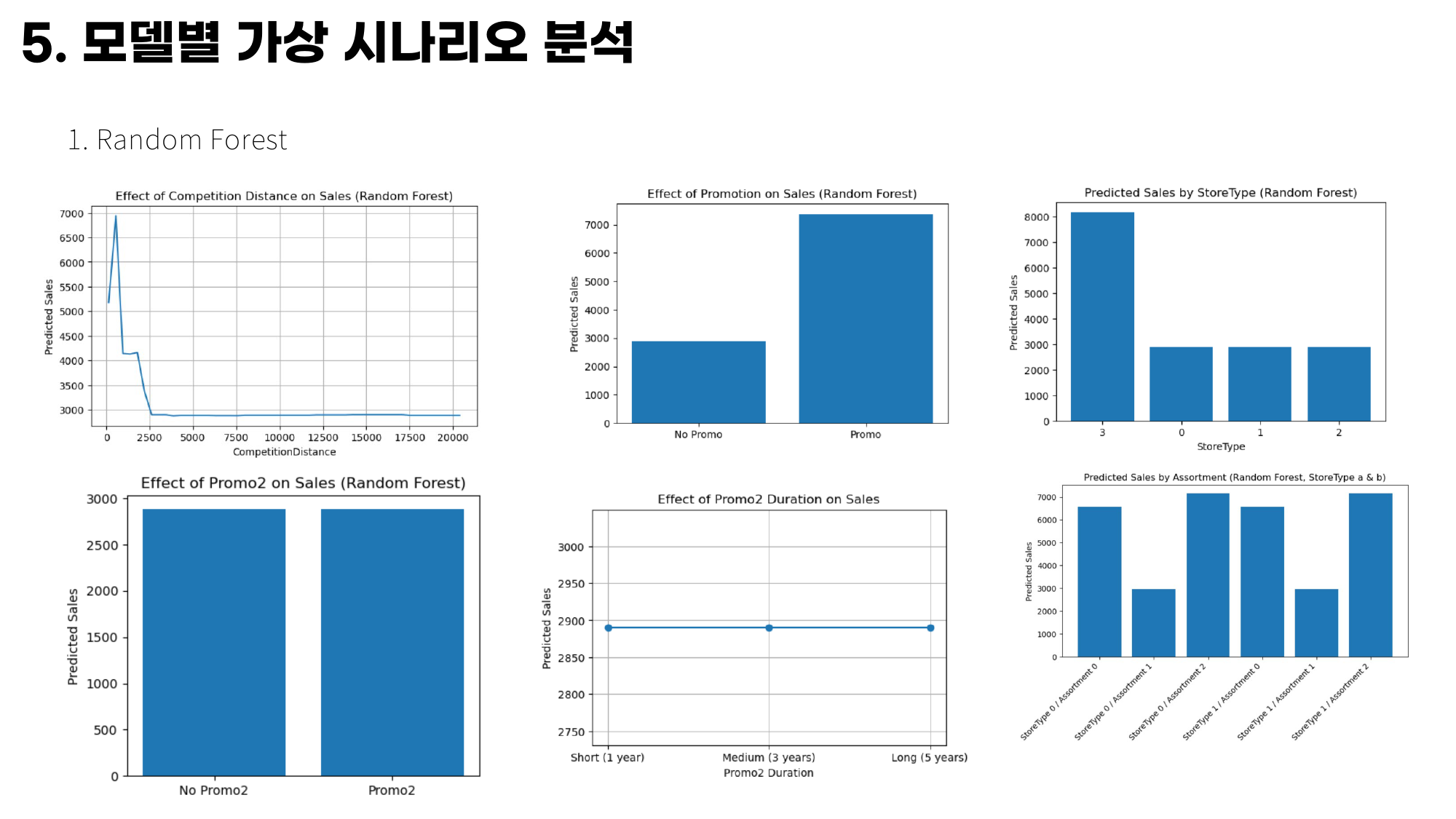
내가 이 슬라이드에 담고 싶었던 건 Random Forest가 실제로 어떤 질문에 답하게 했는지였다.
- 경쟁점 거리가 가까우면 매출이 어떻게 바뀌는가
- 프로모션을 했을 때와 안 했을 때 차이가 얼마나 나는가
StoreType이 바뀌면 예측 매출이 어떻게 달라지는가Promo2는 효과가 큰가Promo2기간이 길어질수록 매출이 계속 오르는가StoreType x Assortment조합은 어떤 차이를 만드는가
특히 이 장표에서 인상적이었던 건 Promo2였다. 노트북 출력 기준으로 Promo2 유무 차이는 1.34 수준으로 거의 없었고, 기간을 1년, 3년, 5년으로 바꿔도 예측 매출이 2890.416667로 동일하게 나왔다. 이건 굉장히 흥미로운 결과였다. 장기 프로모션이 무의미하다고 단정할 수는 없지만, 최소한 이번 데이터와 이 모델 조합에서는 “당일 프로모션(Promo)만큼 강한 직접 효과는 보이지 않는다”는 해석이 가능했다.
반대로 StoreType은 차이가 아주 컸다. 노트북 출력에서 StoreType=3의 예측 매출은 8159.013333이었고, 나머지 타입은 2883~2895 수준에 머물렀다. 발표 자료의 StoreType 관련 해석과 연결해 보면, 매장 유형이 이미 강한 구조적 차이를 만들고 있고, 그 위에 판촉과 상품 구성이 얹히는 그림으로 볼 수 있었다.
매출에 영향을 주는 특성으로 정리한 것들
발표 자료를 만들면서 최종적으로 정리한 핵심 특성은 아래였다.
Customers: 고객 수가 늘면 매출도 거의 직접적으로 증가했다.Month: 전반적으로 특정 시즌, 특히 연말 구간에서 매출 강도가 높게 나타났다.DayOfWeek: 요일에 따라 편차가 꽤 크게 났다.IsMonthEnd: 월말 여부가 매출 변화와 연결됐다.Promo: 당일 프로모션은 매출 상승에 직접적인 영향을 줬다.StateHoliday: 공휴일은 일반 영업일과 다른 패턴을 만들었다.StoreType: 매장 유형에 따라 매출 수준 차이가 있었다.StoreType x Assortment: 매장 유형과 상품 구성 범위를 함께 볼 때 차이가 더 잘 드러났다.
개인적으로 흥미로웠던 포인트는 두 가지였다.
첫째, 단일 변수보다 조합 변수가 훨씬 설명력이 좋았다. 예를 들어 StoreType만 볼 때보다 StoreType과 Assortment를 함께 봤을 때 어떤 매장이 더 높은 매출을 만들 가능성이 있는지 훨씬 뚜렷하게 보였다.
둘째, 프로모션은 “하면 좋다” 수준이 아니라 “언제, 어떤 매장에, 얼마나 집중할지”가 중요한 변수였다. 같은 프로모션이라도 요일, 월말 여부, 매장 유형, 경쟁점 거리와 결합해서 봐야 실제 운영 전략으로 연결할 수 있었다.
모델 비교 결과
발표 자료 기준으로 모델 비교 결과는 아래처럼 정리했다.
최종 발표에서는 Random Forest를 베스트 모델로 소개했다. 성능도 가장 좋았지만, 무엇보다 feature 해석과 시나리오 설명에 연결하기 편했다는 점이 컸다. 짧은 프로젝트에서는 “최고 성능” 자체보다 “왜 그렇게 나왔는지 설명 가능한가”가 발표 완성도를 좌우했다.
이 비교표는 발표 자료에서도 별도 슬라이드로 뽑아 두었다.
Random Forest가 압도적으로 혼자 튀는 수준은 아니고 LightGBM도 거의 비슷하게 따라왔다. 그래서 오히려 발표에서는 “왜 Random Forest를 대표 모델로 삼았는가”를 설명하는 쪽이 더 중요했다. 내가 발표에서 밀었던 이유는 아래 세 가지였다.
- 결과가 좋다.
- 중요 변수를 직관적으로 설명하기 쉽다.
- 시나리오 분석 결과를 장표로 옮기기 좋다.
그래서 어떤 매출 증대 솔루션을 제안했나
발표의 마지막 장에서는 단순히 “예측이 잘 된다”에서 끝내지 않고, 실제 매장 운영 관점의 액션으로 정리했다.
1. 프로모션 운영 최적화
- 경쟁 상황과 월말, 요일 효과를 반영한 프로모션 캘린더를 운영한다.
- 고객 수요가 높아지는 시즌에는
Promo2를 더 집중적으로 배치한다. - 모든 매장에 같은 강도의 프로모션을 뿌리기보다, 매장 유형과 상권 조건별로 차등 적용한다.
2. StoreType과 Assortment 조합 재설계
- 매출 잠재력이 높은 매장에는 assortment 확장 전략을 우선 검토한다.
StoreType x Assortment조합별 반응 차이를 보고 상품 구성 범위를 조정한다.- 특히 경쟁점 거리가 가까운 지역은 매장 포지셔닝을 더 공격적으로 설계할 필요가 있다.
3. 경쟁점 정보 기반 운영 전략
CompetitionDistance와 경쟁점 오픈 기간을 함께 보며 점포 전략을 나눈다.- 경쟁이 강한 지역은 프로모션과 상품 구성을 묶은 방어 전략이 필요하다.
- 반대로 경쟁 압력이 낮은 지역은 비용 대비 효율 중심 운영이 가능하다.
정리하면, “매출을 올리는 방법”은 하나의 마법 버튼이 아니라 프로모션, 매장 유형, 상품 구성, 경쟁 환경을 묶어 보는 운영 설계 문제였다.
발표 자료를 만들면서 느낀 점
이번 미니 프로젝트는 이틀짜리였지만, 데이터 프로젝트에서 무엇을 먼저 보여줘야 하는지 꽤 선명하게 배운 작업이었다.
- 분석은 넓게 했지만, 발표에서는 질문 하나로 압축해야 한다.
- 모델 점수보다 “무슨 특성이 매출에 영향을 주는가”가 더 기억에 남는다.
- 실행 가능한 제안이 있어야 분석 결과가 발표 자료 안에서 살아난다.
특히 나는 발표 자료에서 탐색 결과와 모델 결과를 따로 떼어놓지 않고 “이 특성이 중요하다 → 그래서 이런 전략이 가능하다”로 이어 붙였다. 나중에 다시 봐도 흐름이 끊기지 않았다.
아래 사진은 그 발표를 직접 진행하던 순간이다.

발표 자료는 아래에 첨부해 둔다.
마무리
짧은 프로젝트였지만, store.csv와 train.csv처럼 구조가 잘 잡힌 데이터셋을 만나면 단순 예측보다 훨씬 많은 이야기를 할 수 있다는 걸 다시 확인했다. 이틀 동안 한 일은 결국 하나였다. Rossmann의 매출을 숫자로만 맞히는 것이 아니라, 어떤 조건이 매출을 움직이는지 설명하고, 그 설명을 매장 운영 아이디어로 바꾸는 것.
그래서 이번 프로젝트는 모델링 연습이라기보다, 데이터 분석을 “의사결정 언어”로 바꾸는 훈련에 더 가까웠다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.