Day 2에서는 모델보다 데이터를 먼저 읽었다
2026년 1월 9일, 스팸 분류 스터디 두 번째 기록에서는 모델을 바로 학습시키기보다 데이터를 조금 더 눈으로 읽는 작업에 집중했다. 첫 번째 글에서 이미 spam.csv를 불러오고, 불필요한 컬럼을 제거하고, ham과 spam 비율이 꽤 기울어져 있다는 사실까지는 확인했다.
둘째 날에는 목표를 이렇게 잡았다.
- 정상 메시지와 스팸 메시지가 실제로 어떻게 다른지 시각적으로 보기
- 숫자만 보던 데이터를 그래프로 바꿔서 감을 잡기
- 이후 전처리와 모델링 방향을 정할 힌트를 찾기
즉 Day 2는 본격적인 분류기 실험보다, 데이터의 성격을 해석하는 EDA에 가까운 날이었다.
클래스 비율부터 다시 봤다
전날에도 확인했던 부분이지만, 둘째 날 시각화를 보기 전에 다시 한 번 ham과 spam 비율을 머리에 넣고 시작하는 것이 중요했다.
print(df['label'].value_counts())중복 제거 전 원본 기준 개수는 다음과 같았다.
ham: 4825개spam: 747개
비율로 보면 대략 이렇다.
- 정상 메시지: 약
86.6% - 스팸 메시지: 약
13.4%
이 비율을 먼저 보고 가야 하는 이유는 간단하다. 이후에 나오는 그래프나 모델 결과를 볼 때, “정상 데이터가 기본적으로 훨씬 많다”는 전제를 잊으면 해석이 쉽게 틀어지기 때문이다.
예를 들어 정확도 숫자만 높아 보여도 실제로는 스팸을 잘 못 잡고 있을 수 있다. 그래서 Day 2 시각화는 단순히 예쁜 그림을 보는 것이 아니라, 데이터 불균형이 실제로 어떤 모습으로 드러나는지 이해하는 과정이었다.
문장 길이부터 비교해 보기로 했다
둘째 날 가장 먼저 본 그래프는 메시지 길이 분포였다. 노트북에서는 각 문자 길이를 계산한 뒤 histplot으로 정상 메시지와 스팸 메시지를 한 번에 비교하고 있었다.
df['length'] = df['text'].apply(len)
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='length', hue='label', bins=50, kde=True)
plt.title('Message Length Distribution: Ham vs Spam')
plt.xlabel('Length')
plt.ylabel('Frequency')
plt.show()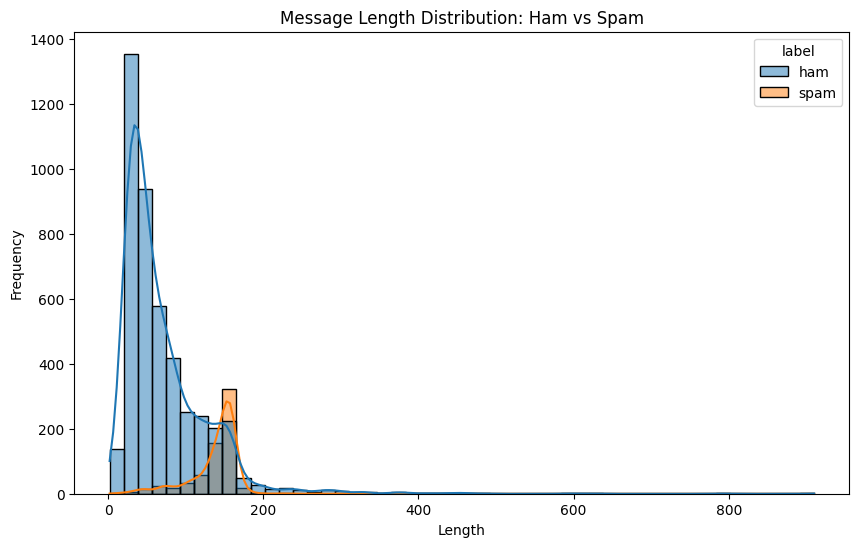
이 그래프를 처음 봤을 때 가장 먼저 눈에 들어온 것은, 스팸 메시지 쪽 분포가 전반적으로 오른쪽으로 밀려 있다는 점이었다. 즉 스팸 메시지가 평균적으로 더 길다.
실제 수치로 보니 차이가 더 또렷했다.
- 정상 메시지 평균 길이: 약
70.46 - 스팸 메시지 평균 길이: 약
137.89 - 정상 메시지 중앙값:
52 - 스팸 메시지 중앙값:
149
정상 메시지는 대화형 문장이 많아서 짧고 일상적인 표현이 많고, 스팸 메시지는 당첨 문구, 번호, 링크, 회신 유도 같은 정보가 붙으면서 길어지는 경향이 있다는 것을 그래프만으로도 확인할 수 있었다.
왜 스팸 메시지가 더 길게 나오는지 생각해 봤다
그래프를 보고 끝내지 않고, 왜 이런 차이가 생기는지도 같이 생각해 봤다. 실제 스팸 메시지는 보통 이런 요소를 많이 포함한다.
- 금액이나 경품 관련 문구
- 회신을 유도하는 문장
- 전화번호나 URL
FREE,WINNER,CLAIM,STOP같은 강한 키워드- 짧은 광고문이 아니라 여러 정보를 한꺼번에 붙여 놓은 문장
반면 정상 메시지는 친구나 가족 사이 대화처럼 짧은 응답형 메시지가 많다.
Ok lar...Sorry, I'll call laterNah I don't think so
즉 길이 자체가 이미 분류에 도움이 되는 힌트가 될 수 있다는 점을 Day 2에서 확인한 셈이다. 물론 길이 하나만으로 분류하는 것은 위험하지만, “문장 구조가 다르다”는 사실을 초반에 파악한 것은 꽤 의미 있었다.
길이 분포 그래프를 보고 든 생각
이 그래프를 보면서 개인적으로 두 가지를 정리하게 됐다.
첫째, 텍스트 분류 문제라고 해서 단어만 볼 필요는 없다는 점이다. 텍스트의 길이, 구두점 패턴, 숫자 포함 여부처럼 문장 형태 자체도 정보가 된다.
둘째, 스팸 분류에서는 단순 단어 매칭보다 “스팸이 어떻게 말하는가”를 보는 것도 중요하다는 점이다. 즉 단어 사전만이 아니라 메시지의 전반적 구조도 분류 힌트가 된다.
이런 생각은 나중에 SVM과 LSTM 실험 결과를 해석할 때도 꽤 도움이 됐다.
전처리를 하기 전에 데이터의 언어 분위기를 보고 싶었다
길이 분포를 본 다음에는, 실제로 어떤 단어들이 많이 등장하는지 확인하는 흐름으로 넘어갔다. 여기서 워드클라우드가 등장한다.
다만 워드클라우드를 만들기 전에는 최소한의 텍스트 정리가 먼저 필요했다. 노트북에서도 워드클라우드는 원문 그대로가 아니라 전처리된 텍스트를 기준으로 만들고 있었다.
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
text = re.sub(r'[^a-zA-Z]', ' ', text)
text = text.lower()
words = text.split()
words = [stemmer.stem(w) for w in words if w not in stop_words]
return ' '.join(words)
df['processed_text'] = df['text'].apply(preprocess_text)이 함수는 이후 모델링에서도 쓰이지만, 둘째 날에는 “어떤 단어가 실제로 많이 남는가”를 보기 위한 준비 단계로도 의미가 있었다.
워드클라우드로 전체 단어 분위기를 봤다
전처리된 텍스트를 하나로 합쳐 워드클라우드를 만든 코드는 아래와 같았다.
all_text = ' '.join(df['processed_text'])
wordcloud = WordCloud(
width=800,
height=400,
background_color='white',
colormap='viridis'
).generate(all_text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud of Processed Text')
plt.show()
워드클라우드는 정량 분석 도구라기보다, 데이터의 언어 분위기를 한 번에 보는 도구에 가깝다. 그리고 실제로 이 그림을 보면 어떤 단어들이 자주 등장하는지 바로 감이 온다.
둘째 날 기준으로 특히 눈에 들어온 단어는 이런 것들이었다.
callfreetextreplyclaimprizecashstop
이런 단어들은 일반 대화보다 광고, 유도, 당첨, 회신, 차단 안내 같은 스팸 문맥과 더 가깝다. 반대로 정상 메시지에서는 일상적 대화에서 자주 쓰이는 표현이 많았다.
빈출 단어를 다시 숫자로도 확인했다
워드클라우드는 시각적으로 좋지만, 실제로는 빈도 표도 같이 보는 것이 더 도움이 된다. 노트북을 기준으로 전처리한 뒤 단어를 세어 보면 전체 상위 단어는 대략 이런 흐름이었다.
- 전체 기준:
u,call,go,get,ur,free,text - 스팸 쪽 상위:
call,free,txt,text,mobile,stop,reply,claim,prize - 정상 쪽 상위:
u,go,get,ok,come,know,good,love
여기서 흥미로웠던 점은 call처럼 두 클래스에 모두 많이 나오는 단어도 존재한다는 것이다. 즉 스팸 분류는 단순히 “이 단어가 있으면 스팸”처럼 풀리는 문제가 아니었다. 같은 단어라도 함께 등장하는 다른 단어, 문장 길이, 표현 패턴이 같이 봐야 의미가 생긴다.
그래서 Day 2에서 내가 잡은 결론은 이랬다.
단어 하나보다 단어 조합과 문장 패턴이 더 중요하다.
이 생각이 이후 CountVectorizer, TF-IDF, N-gram 실험으로 자연스럽게 이어졌다.
워드클라우드만으론 부족했다
워드클라우드는 전체 분위기를 보는 데는 유용했지만, 한계도 분명히 있었다.
ham과spam을 완전히 분리해서 보여주지 않는다- 단어 중요도가 실제 분류 기여도와 같지는 않다
- 전처리 방식에 따라 단어 모양이 달라진다
예를 들어 mobile은 mobil처럼 어간 형태로 남고, reply도 repli로 줄어든다. 처음에는 이런 형태가 어색하게 느껴졌지만, 스테밍이 적용된 결과라는 점을 이해하고 나니 “모델이 학습하는 단어 형태”를 보는 것이라고 받아들이게 됐다.
즉 Day 2의 워드클라우드는 보고서용 예쁜 이미지라기보다, 전처리 결과를 사람이 한 번 검수하는 용도에도 가까웠다.
둘째 날까지는 아직 모델보다 해석이 더 중요했다
스팸 분류 스터디라고 하면 보통 바로 어떤 알고리즘을 썼는지부터 떠올리기 쉽다. 하지만 실제 흐름은 그 반대에 가까웠다. 둘째 날까지는 모델을 고르는 일보다 데이터를 어떻게 이해할지가 더 중요했다.
Day 2에서 정리된 중요한 사실은 이렇다.
- 스팸 메시지는 정상 메시지보다 평균적으로 훨씬 길다.
- 데이터는 클래스 불균형이 심하다.
free,claim,reply,cash,prize같은 단어는 스팸 쪽 특징을 강하게 보여 준다.- 정상 메시지는 일상적인 짧은 대화 표현이 많다.
- 단어 하나보다 단어 조합과 문장 구조가 중요할 가능성이 높다.
이 다섯 가지는 이후 모델링 방향을 정하는 데 꽤 큰 힌트가 됐다.
Day 2에서 중요한 코드만 다시 정리하면
둘째 날 핵심 코드는 크게 세 블록이었다.
먼저 길이를 계산하고 분포를 보는 코드:
df['length'] = df['text'].apply(len)
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='length', hue='label', bins=50, kde=True)
plt.show()그다음 전처리 함수:
def preprocess_text(text):
text = re.sub(r'[^a-zA-Z]', ' ', text)
text = text.lower()
words = text.split()
words = [stemmer.stem(w) for w in words if w not in stop_words]
return ' '.join(words)마지막으로 워드클라우드 생성 코드:
all_text = ' '.join(df['processed_text'])
wordcloud = WordCloud(
width=800,
height=400,
background_color='white',
colormap='viridis'
).generate(all_text)이 세 블록만으로도 Day 2의 흐름은 거의 설명된다. 둘째 날은 “분석을 위한 데이터를 사람이 읽을 수 있게 바꾸는 날”이었다.
내가 Day 2에서 배운 것
둘째 날을 지나면서 가장 크게 느낀 것은, EDA가 단순한 준비 단계가 아니라는 점이었다. 그래프 한 장, 워드클라우드 한 장이 나중 모델 결과를 해석하는 기준을 만들어 준다.
예를 들어 Day 2를 하지 않았다면, 나중에 Bag of Words가 왜 잘 나오는지, 왜 SVM에서 threshold 조정이 의미 있는지, 왜 스팸 Recall과 Precision이 같이 중요해지는지 훨씬 막연하게 받아들였을 것 같다.
반대로 길이 분포와 단어 분위기를 먼저 보고 나니 이후 흐름이 자연스럽게 연결됐다.
- 스팸은 길다
- 스팸은 특정 단어 조합이 강하다
- 그러면 빈도 기반 벡터화가 잘 먹을 수도 있다
- 그런데 데이터 불균형이 있으니 정확도만 믿으면 안 된다
즉 둘째 날은 모델링 이전에 사고의 틀을 만드는 날이었다.
마무리
2026년 1월 9일, 스팸 분류 스터디 두 번째 기록은 데이터를 시각적으로 읽는 시간이었다. 문장 길이 분포와 워드클라우드를 통해 정상 메시지와 스팸 메시지가 어떤 차이를 가지는지 확인했고, 그 차이가 이후 분류기의 특징 설계와 성능 해석에 어떤 영향을 줄지도 미리 생각해 볼 수 있었다.
둘째 날까지 오고 나니 이제 다음 단계가 분명해졌다.
- 텍스트를 더 본격적으로 정제하고
- 벡터화해서
- 실제 분류 모델을 돌려 보고
- 단순 정확도 외의 지표도 같이 해석해야 한다
다음 글에서는 Day 3 기준으로, 불용어 제거와 스테밍 같은 전처리를 실제로 적용하고, 전처리 전후 텍스트가 어떻게 달라졌는지 더 자세히 정리해 보려고 한다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.