세 번째 글부터는 본격적으로 전처리에 들어갔다
2026년 1월 14일, 스팸 분류 스터디 세 번째 기록에서는 드디어 모델이 먹을 수 있는 형태로 텍스트를 정리하는 작업을 본격적으로 진행했다. 앞선 두 글에서 한 일은 크게 두 가지였다.
- 데이터 구조를 점검하고 불필요한 컬럼을 정리했다
- 길이 분포와 워드클라우드로 spam 데이터의 분위기를 읽었다
그다음 단계는 자연스럽게 전처리였다. 문자 데이터는 원문 그대로 두고는 바로 학습시키기 어렵다. 특수문자, 대소문자, 불필요한 조사나 관사, 형태가 조금씩 다른 비슷한 단어들이 너무 많기 때문이다.
그래서 이번 회차에서는 “문장을 사람이 읽기 좋은 형태로 보존하는 것”보다 “모델이 패턴을 읽기 좋은 형태로 바꾸는 것”에 집중했다.
먼저 중복을 제거하고 분석 기준을 다시 맞췄다
print(df.duplicated().sum())
print(df[df.duplicated()])여기서 확인된 중복 개수는 403개였다. 문자 분류 문제에서 중복은 생각보다 영향을 크게 준다. 같은 문장이 여러 번 들어 있으면 모델이 특정 표현만 과하게 학습할 수 있기 때문이다.
그래서 이후 단계에서는 중복을 제거한 데이터를 기준으로 보는 흐름이 더 자연스러웠다.
df.drop_duplicates(inplace=True)
df.rename(columns={'v1': 'label', 'v2': 'text'}, inplace=True)정리 후 데이터 크기는 5169 x 2가 됐다. 즉 이제는 본격적으로 아래 두 컬럼만 남긴 상태였다.
labeltext
이렇게 해 두고 나니 이후 전처리 결과를 확인할 때도 훨씬 덜 헷갈렸다.
왜 전처리가 필요한가를 다시 생각했다
이번 회차에서 가장 오래 붙잡고 있었던 질문은 이것이었다.
스팸 분류에서 어떤 텍스트를 남기고, 어떤 텍스트를 버려야 하는가
문자 메시지 원문에는 분류에 도움 되는 정보와 방해되는 정보가 섞여 있다.
- 도움 되는 정보
free,claim,reply,cash,prize- 반복적으로 등장하는 행동 유도 단어
- 광고성 문장 패턴
- 방해되는 정보
- 의미 없는 구두점
- 대문자/소문자 표기 차이
- 의미보다 형태만 다른 단어들
- 자주 나오지만 분류력은 낮은 불용어
즉 전처리의 목적은 문장을 깨끗하게 보이게 만드는 것이 아니라, 모델이 진짜 중요한 단어 패턴에 더 집중하도록 잡음을 줄이는 것이었다.
이번 회차에서 적용한 전처리 순서
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
text = re.sub(r'[^a-zA-Z]', ' ', text)
text = text.lower()
words = text.split()
words = [stemmer.stem(w) for w in words if w not in stop_words]
return ' '.join(words)이 함수가 하는 일은 순서대로 다음과 같다.
- 알파벳이 아닌 문자를 제거한다
- 모든 글자를 소문자로 바꾼다
- 공백 기준으로 단어를 나눈다
- 불용어를 제거한다
- 남은 단어에 스테밍을 적용한다
- 다시 하나의 문자열로 합친다
수업 시간에 배웠던 내용과 거의 같은 흐름이지만, 실제 데이터에 적용하니 각 단계가 왜 필요한지 훨씬 선명하게 느껴졌다.
특수문자 제거만 해도 효과가 났다
문자 메시지 데이터는 일반 문장보다 특수문자가 훨씬 많이 섞여 있다. 괄호, 느낌표, 숫자, 점, 하이픈, URL 조각, 금액 표기 등이 계속 섞여 나오기 때문이다.
여기서 사용한 코드는 아래 한 줄이었다.
text = re.sub(r'[^a-zA-Z]', ' ', text)즉 영어 알파벳만 남기고 나머지는 공백으로 바꾸는 방식이다.
처음에는 숫자나 기호도 정보 아닌가 싶었지만, 이번 스터디에서는 우선 텍스트 내용 그 자체에 집중하기로 했기 때문에 가장 단순한 정리 방식으로 갔다. 나중에 더 고도화한다면 숫자나 URL 패턴을 별도 특징으로 남길 수도 있겠지만, 기본 분류기 실습에서는 오히려 너무 많은 요소를 동시에 넣으면 해석이 어려워질 수 있다.
소문자 변환은 단순하지만 꼭 필요했다
스팸 메시지는 대문자를 강조 표현처럼 쓰는 경우가 많다.
FREEWINNERURGENT
하지만 지금 단계에서는 Free, FREE, free를 서로 다른 단어로 취급하는 것이 오히려 비효율적이라고 판단했다. 그래서 모든 문자를 소문자로 통일했다.
text = text.lower()이렇게 하면 동일한 의미의 단어가 같은 형태로 모인다. 단어 빈도를 계산하거나 벡터화를 할 때도 훨씬 일관된 입력이 된다.
불용어 제거는 왜 필요한지 직접 느꼈다
불용어는 영어에서 너무 자주 나와서 오히려 구분에 큰 도움이 되지 않는 단어들이다.
theaistoand
이런 단어를 그대로 두면 메시지마다 거의 다 비슷하게 등장하기 때문에, 스팸과 정상 메시지를 구분하는 데 큰 도움이 되지 않는다.
노트북에 NLTK의 stopwords를 내려받아 사용했다.
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))그리고 전처리 함수에서 아래처럼 제거했다.
words = [stemmer.stem(w) for w in words if w not in stop_words]이 과정을 통해 남는 단어는 문장의 뼈대라기보다 분류에 실제로 더 중요한 핵심 표현에 가까워졌다.
스테밍은 처음 보면 어색하지만, 왜 하는지는 알겠다
이번 회차에서 가장 낯설었던 부분은 스테밍 결과였다. 스테밍은 단어를 어간 중심으로 줄여서 비슷한 형태를 하나로 묶는 작업이다.
예를 들면 이런 식이다.
available->availreplying->replicrazy->crazi
처음 보면 사람이 읽기에는 오히려 불편하다. 하지만 모델 입장에서는 reply, replied, replying을 따로 배우는 것보다 하나의 뿌리 단어로 묶는 편이 더 효율적일 수 있다.
이번 스터디에서는 PorterStemmer()를 사용했다.
stemmer = PorterStemmer()즉 문장을 자연스럽게 유지하는 것보다, 비슷한 단어 형태를 하나로 묶어 벡터화가 잘 되도록 만드는 쪽을 선택한 것이다.
전처리 전후를 직접 비교하니 차이가 확실했다
df['processed_text'] = df['text'].apply(preprocess_text)
print(df[['text', 'processed_text']].head())예시를 보면 이런 느낌이었다.
-
원문:
Go until jurong point, crazy.. Available only in bugis n great world... -
전처리 후:
go jurong point crazi avail bugi n great world ... -
원문:
Ok lar... Joking wif u oni... -
전처리 후:
ok lar joke wif u oni
이 비교를 보면서 확실히 느낀 것은, 전처리 후 텍스트는 사람이 읽기에는 조금 덜 자연스럽지만 모델이 보기에는 더 명확한 재료가 된다는 점이었다.
즉 이번 회차는 “문장을 정리하는 작업”이 아니라 “학습 입력을 재구성하는 작업”에 가까웠다.
이제야 벡터화와 기본 분류기를 돌릴 준비가 됐다
전처리까지 끝나고 나니, 그다음에는 텍스트를 숫자로 바꾸는 단계로 넘어갈 수 있었다. 노트북에서는 CountVectorizer와 TfidfVectorizer를 각각 적용한 뒤 MultinomialNB를 사용해 비교했다.
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, f1_score그리고 학습/테스트 데이터를 분리했다.
df['label'] = df['label'].map({'spam': 1, 'ham': 0})
X_train, X_test, y_train, y_test = train_test_split(
df['text'],
df['label'],
test_size=0.2,
random_state=42,
stratify=df['label']
)여기서 한 가지 아쉬운 점도 있었다. 전처리 컬럼을 따로 만들어 두었는데, 기본 비교 실험에서는 processed_text가 아니라 text를 기준으로 학습하고 있었다. 하지만 그 자체도 오히려 공부가 됐다.
- 전처리된 텍스트를 쓸 수도 있고
- 원문 기준으로도 baseline을 만들 수 있다
즉 어떤 입력을 쓰는지가 결과에 영향을 줄 수 있다는 점을 자연스럽게 생각하게 됐다.
Bag of Words와 TF-IDF를 처음 비교했다
기본 비교 함수는 아래처럼 작성돼 있었다.
def train_model(vectorizer_type):
if vectorizer_type == 'count':
vectorizer = CountVectorizer()
name = "Bag of Words (Count)"
else:
vectorizer = TfidfVectorizer()
name = "TF-IDF"
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
model = MultinomialNB()
model.fit(X_train_vec, y_train)
y_pred = model.predict(X_test_vec)
print(f"=== {name} 성능 ===")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")
print(f"F1-score: {f1_score(y_test, y_pred):.4f}")이후 두 방식을 연속으로 실행했다.
train_model('count')
train_model('tfidf')결과는 다음과 같았다.
- Bag of Words Accuracy:
0.9865 - Bag of Words F1-score:
0.9449 - TF-IDF Accuracy:
0.9516 - TF-IDF F1-score:
0.7642
그리고 이 결과를 다시 막대 그래프로 정리한 시각화도 남아 있었다.
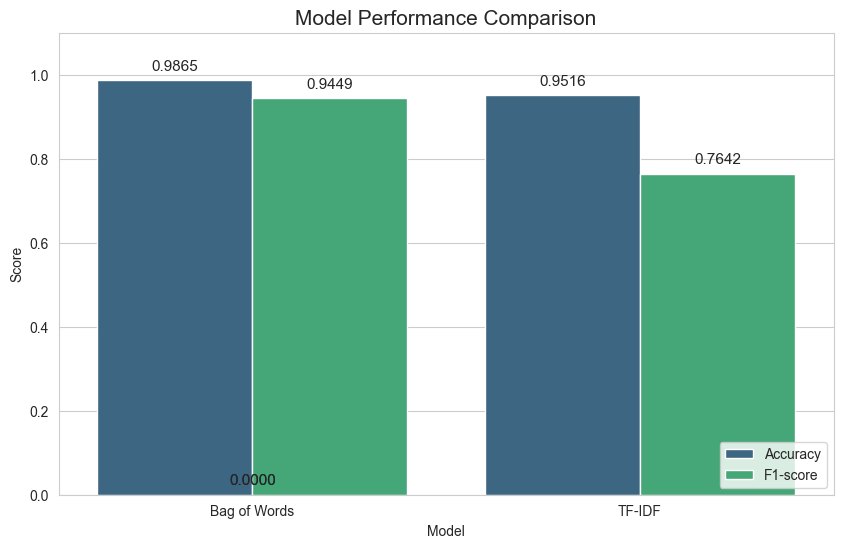
결과가 의외였던 이유
처음에는 TF-IDF가 더 잘 나올 것이라고 막연히 생각했다. 중요도를 반영하는 방식이니 당연히 더 정교할 것 같았기 때문이다. 그런데 이번 데이터에서는 오히려 Bag of Words가 더 좋았다.
이 결과를 보면서 세 번째 기록에서 정리한 생각은 이랬다.
- SMS 스팸은 문장이 짧고 패턴이 강하다
- 그래서 단어 등장 여부와 빈도 자체가 이미 강한 신호일 수 있다
- 복잡한 가중치보다 단순한 카운트가 더 잘 먹는 데이터도 있다
즉 TF-IDF가 이론적으로 더 세련된 방법처럼 보여도, 실제 데이터에서는 가장 단순한 방법이 baseline으로 더 강할 수 있다는 점을 직접 확인한 것이다.
이번 회차에서 느낀 전처리의 의미
세 번째 기록을 정리하면서 가장 크게 남은 것은 전처리가 “있으면 좋은 옵션”이 아니라 거의 필수 단계라는 점이었다.
전처리를 하고 나니 이런 변화가 생겼다.
- 데이터의 잡음이 줄었다
- 비슷한 단어를 하나로 묶을 수 있었다
- 워드클라우드와 빈출 단어 해석이 쉬워졌다
- 이후 벡터화 실험으로 자연스럽게 이어졌다
그리고 동시에 이런 사실도 배웠다.
- 전처리를 했다고 해서 무조건 복잡한 모델이 이긴다거나
- TF-IDF가 항상 Count보다 우수하다거나
- 딥러닝이 항상 baseline보다 좋다는 보장은 없다
즉 전처리는 모델 성능을 자동으로 올려 주는 마법이 아니라, 비교 가능한 입력을 만들어 주는 기반 작업에 가까웠다.
마무리
2026년 1월 14일의 스팸 분류 스터디 세 번째 기록은, 본격적인 텍스트 전처리와 첫 baseline 비교를 진행한 회차였다. 특수문자 제거, 소문자 변환, 불용어 제거, 스테밍을 적용하면서 모델이 읽기 좋은 입력을 만드는 과정을 손으로 따라가 봤고, 그 위에서 Bag of Words와 TF-IDF 기반 Naive Bayes 결과를 처음 비교할 수 있었다.
이번 회차까지 오고 나니 이제 다음 단계가 명확해졌다.
- 단순 baseline을 넘어
- 스팸과 정상 메시지를 더 잘 가르는 기준을 고민하고
- N-gram, SVM, threshold 조정 같은 더 실전적인 실험으로 넘어가는 것
다음 글은 2026년 1월 16일 기준으로, SVM과 안전 임계값 조정을 통해 “정상 메시지를 스팸으로 잘못 분류하지 않는 것”에 집중한 실험을 중심으로 정리할 생각이다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.