마지막 기록에서는 딥러닝 쪽을 끝까지 밀어봤다
2026년 1월 21일, 스팸 분류 스터디 마지막 기록에서는 딥러닝 모델을 중심으로 실험을 정리했다. 앞선 회차들에서 이미 몇 가지는 분명해져 있었다.
- 데이터 구조와 클래스 불균형은 확인했다
- 길이 분포와 빈출 단어를 통해 spam/ham의 언어 차이를 봤다
- 전처리와 기본 벡터화 실험을 해봤다
- SVM과 threshold tuning으로 “정상 메시지를 지키는 기준”도 세웠다
이제 남은 질문은 하나였다.
딥러닝으로 가면 이 문제를 더 잘 풀 수 있을까
그리고 이 마지막 회차에서 얻은 답은 꽤 현실적이었다.
- 기본 LSTM은 기대만큼 좋지 않았다
- 구조를 개선하니 성능이 크게 좋아졌다
- 하지만 마지막까지 중요한 것은 accuracy 하나가 아니라 precision, recall, overfitting, threshold의 균형이었다
즉 마지막 글은 단순히 “BiLSTM이 더 좋았다”로 끝나는 이야기가 아니라, 딥러닝 모델을 실제로 어떻게 다뤄야 하는지 정리하는 기록에 더 가까웠다.
먼저 기본 LSTM부터 돌려봤다
처음 시도한 모델은 비교적 단순한 LSTM 구조였다. 문자 데이터를 바로 넣을 수는 없기 때문에 먼저 토큰화와 패딩을 거쳤다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
vocab_size = 3000
max_length = 150
embedding_dim = 64
tokenizer = Tokenizer(num_words=vocab_size, oov_token="<OOV>")
tokenizer.fit_on_texts(X_data)
sequences = tokenizer.texts_to_sequences(X_data)
padded = pad_sequences(
sequences,
maxlen=max_length,
padding='post',
truncating='post'
)이후 모델은 아래처럼 구성했다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length=max_length),
LSTM(64),
Dropout(0.5),
Dense(32, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])구조만 보면 크게 복잡하지 않다.
- 단어를 임베딩 벡터로 바꾸고
- LSTM이 순서 정보를 읽고
- dropout으로 과적합을 조금 막고
- sigmoid로 최종 이진 분류를 하는 방식이었다
처음에는 이 정도만 해도 Naive Bayes나 SVM보다 더 좋아질 수도 있겠다고 기대했다. 하지만 결과는 예상보다 냉정했다.
기본 LSTM은 기대보다 약했다
기본 LSTM 실험에서 확인한 최종 테스트 정확도는 0.8733 수준이었다.
이 수치만 놓고 보면 아주 나쁜 것은 아니지만, 이미 앞선 회차에서 본 전통적인 머신러닝 baseline과 비교하면 아쉬운 결과였다.
- Bag of Words + Naive Bayes Accuracy:
0.9865 - SVM 기반 실험도 false positive를 통제하는 방향에서 충분히 의미 있었다
- 그런데 기본 LSTM은
0.8733
즉 “딥러닝이니까 더 잘 될 것”이라는 기대는 여기서 바로 깨졌다.
이 결과는 오히려 좋았다. 왜냐하면 여기서부터 딥러닝 모델을 더 현실적으로 보게 됐기 때문이다.
- 모델 구조가 단순하면 성능이 생각보다 안 나올 수 있다
- 텍스트 분류라고 해서 LSTM 하나 넣는다고 끝이 아니다
- 하이퍼파라미터와 구조 조정이 실제로 중요하다
즉 마지막 회차의 전반부는, 딥러닝이 baseline을 자동으로 이기는 것이 아니라는 점을 확인하는 과정이기도 했다.
그래서 단어 사전과 임베딩 차원부터 손봤다
기본 LSTM이 약하게 나온 뒤에는 표현력을 조금 더 키우는 방향으로 수정했다.
vocab_size = 5000
max_length = 150
embedding_dim = 100이렇게 바꾼 데에는 이유가 있었다.
- 더 많은 단어를 사전에 담고 싶었다
- 임베딩 표현력도 조금 더 넓혀 보고 싶었다
SMS 데이터가 아주 긴 문장은 아니지만, 스팸 메시지 특유의 표현이 꽤 다양하게 섞여 있기 때문에, 너무 작은 vocabulary로는 표현 손실이 있을 수 있다고 봤다.
즉 이번 단계는 “모델 자체를 바꾸기 전에 입력 표현을 조금 더 넓혀 보자”는 시도였다.
Bidirectional LSTM으로 구조를 바꿨다
그다음에 가장 크게 바꾼 부분은 LSTM을 양방향으로 읽도록 만든 것이다.
from tensorflow.keras.layers import Bidirectional
from tensorflow.keras.optimizers import Adam
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length=max_length),
Bidirectional(LSTM(64)),
Dropout(0.5),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
optimizer = Adam(learning_rate=0.001)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])Bidirectional LSTM을 선택한 이유는 문장을 앞에서 뒤로만 읽는 것보다, 양쪽 문맥을 같이 보는 편이 짧은 문자 패턴을 더 잘 잡을 수 있다고 판단했기 때문이다.
특히 SMS 스팸은 문장 구조가 아주 정교하다기보다 특정 표현 조합이 강한 편이라, 앞뒤 문맥을 같이 읽는 구조가 더 유리할 수 있다고 봤다.
그리고 실제로 결과도 확실히 달라졌다.
첫 번째 BiLSTM 결과는 확실히 좋아졌다
Bidirectional LSTM을 적용한 뒤 얻은 첫 번째 의미 있는 결과는 아래와 같았다.
- Accuracy:
0.9855 - Precision:
1.0000 - Recall:
0.8855 - F1-score:
0.9393 - Confusion Matrix:
[[903, 0], [15, 116]]
즉 기본 LSTM의 약점이 꽤 많이 개선됐다. 특히 중요한 것은 precision이 1.0000이라는 점이었다.
이 수치는 이번 시리즈 내내 유지하려고 했던 기준과 정확히 맞닿아 있다.
정상 메시지를 스팸으로 잘못 보내지 않는다
결과를 혼동행렬로 보면 더 명확하다.
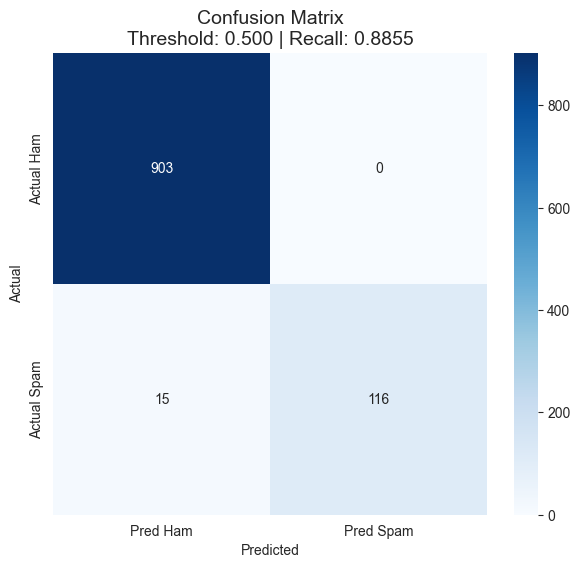
이 결과는 딥러닝 모델도 결국 단순 accuracy보다, 어떤 실수를 허용하고 어떤 실수를 막을지 기준을 같이 가져가야 한다는 점을 다시 보여 줬다.
여기서 멈추지 않고 과적합도 확인했다
딥러닝 모델이 어느 정도 성능이 나오기 시작하면 바로 걱정되는 것이 과적합이다. 학습 정확도는 계속 오르는데 검증 성능이 따라오지 않으면, 모델이 훈련 데이터만 외운 상태일 가능성이 커진다.
그래서 이번 회차에서는 Early Stopping을 적극적으로 사용했다.
from tensorflow.keras.callbacks import EarlyStopping
early_stop = EarlyStopping(
monitor='val_loss',
patience=4,
restore_best_weights=True
)
history = model.fit(
X_train, y_train,
epochs=15,
batch_size=32,
validation_data=(X_test, y_test),
callbacks=[early_stop],
verbose=1
)그리고 학습 곡선을 직접 확인했다.
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Loss Curve (Overfitting Check)')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Train Acc')
plt.plot(history.history['val_accuracy'], label='Validation Acc')
plt.title('Accuracy Curve')
plt.legend()
plt.show()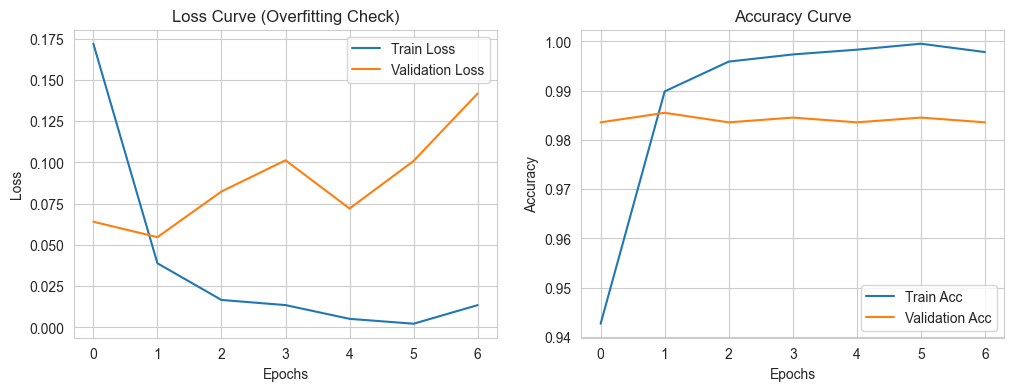
이 그래프를 직접 보고 나니 과적합이라는 개념이 훨씬 덜 추상적으로 느껴졌다.
- train loss는 계속 내려간다
- 그런데 val loss가 다시 올라가기 시작하면 위험 신호다
- 이때 Early Stopping이 가장 괜찮은 지점으로 되돌려 준다
즉 딥러닝은 “오래 학습시키면 더 좋아진다”가 아니라, “언제 멈춰야 하는지 같이 판단해야 한다”는 점을 마지막 회차에서 확실히 체감했다.
마지막에는 epoch를 더 길게 두고 다시 한 번 밀어봤다
이후에는 학습을 조금 더 길게 가져가면서 다시 한 번 성능을 확인했다. 방향은 앞선 실험과 같았다.
- precision은 최대한 유지하고
- recall을 조금 더 올려 보고
- overfitting은 막는다
최종적으로 기록에 남은 결과는 아래와 같았다.
- Threshold:
0.7590 - Accuracy:
0.9874 - Precision:
1.0000 - Recall:
0.9008 - F1-score:
0.9478
이 결과는 꽤 만족스러웠다. 이유는 명확하다.
- 정상 메시지를 스팸으로 잘못 보내지 않았다
- 스팸 재현율도
0.9008까지 끌어올렸다 - F1-score도 baseline과 비교해 충분히 경쟁력 있었다
그리고 최종 결과는 아래 혼동행렬로 정리됐다.
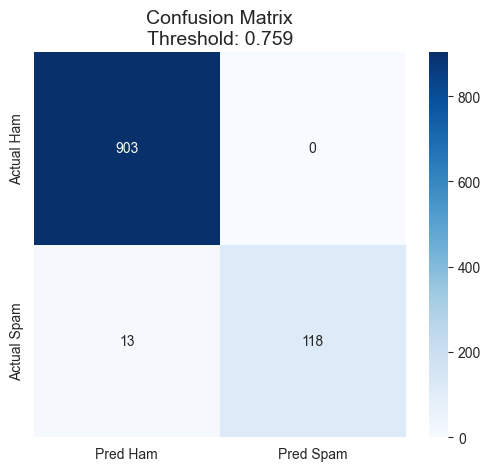
마지막 회차를 정리하면 이랬다. BiLSTM이 무조건 마법처럼 문제를 해결한 것은 아니었지만, 구조 조정과 학습 제어, threshold tuning을 같이 가져가니 꽤 설득력 있는 결과를 만들 수 있었다.
왜 마지막까지 threshold tuning을 같이 봤는가
딥러닝 모델에서도 결국 마지막 판단 기준은 여전히 중요했다. 모델이 출력하는 값을 그냥 0.5 기준으로 자르는 것만으로는, 내가 원하는 서비스 기준을 충분히 반영하지 못할 수 있기 때문이다.
이번 마지막 회차에서도 이 원칙은 그대로 유지했다.
- 기본 예측값만 믿지 않는다
- false positive가 0이 되는 지점을 찾는다
- 그 안에서 recall을 최대한 확보한다
즉 threshold tuning은 SVM 회차에서만 필요한 테크닉이 아니라, 마지막 딥러닝 실험에서도 여전히 중요한 기준 조정 수단이었다.
이번 스터디 전체를 관통한 핵심이 바로 이 부분이었다고 생각한다.
좋은 모델은 숫자가 높은 모델이 아니라, 실제로 중요하게 여기는 실수를 덜 하는 모델이다.
이번 스터디를 끝내며 정리한 것
마지막 회차를 마무리하면서, 이번 스팸 분류 스터디 전체를 다시 보면 흐름이 꽤 선명했다.
- 데이터를 읽고 구조를 정리했다
- spam과 ham이 어떻게 다른지 시각적으로 확인했다
- 전처리로 입력을 정리했다
- CountVectorizer, TF-IDF, Naive Bayes로 baseline을 만들었다
- SVM과 N-gram으로 더 실전적인 기준 조정을 해봤다
- 기본 LSTM이 약하다는 것도 확인했다
- BiLSTM으로 구조를 개선했다
- Early Stopping과 threshold tuning으로 성능과 안정성을 같이 봤다
즉 마지막 회차는 딥러닝 하나만 다룬 날이 아니라, 이전 실험에서 세운 기준을 딥러닝에도 그대로 적용해 본 날이었다.
개인적으로 가장 크게 남은 점
이번 스터디는 처음 목적부터 LLM을 최대한 쓰지 않는 방향이었다. 그래서 속도는 확실히 느렸다. 하지만 그 덕분에 오히려 각 단계가 왜 필요한지 더 또렷하게 이해할 수 있었다.
특히 마지막 회차까지 오면서 남은 생각은 세 가지였다.
첫째, baseline을 무시하면 안 된다.
단순한 Naive Bayes도 생각보다 강했다.
둘째, 딥러닝은 구조와 학습 전략이 같이 가야 한다.
그냥 LSTM 하나 쌓는다고 바로 좋아지지 않았다.
셋째, precision과 recall은 결국 목적의 문제다.
이번 스터디에서는 정상 메시지를 지키는 것이 더 중요했다.
이 세 가지는 단순히 스팸 분류 문제 하나에만 해당하는 것이 아니라, 이후 다른 분류 문제를 볼 때도 계속 가져갈 기준이 될 것 같다.
마무리
2026년 1월 21일의 마지막 기록은, BiLSTM 결과를 정리하는 글이면서 동시에 이번 스터디 전체를 마감하는 글이기도 하다. 기본 LSTM의 한계를 직접 확인했고, Bidirectional LSTM과 Early Stopping, threshold tuning을 조합하면서 꽤 안정적인 최종 결과까지 끌고 갈 수 있었다.
마지막에 남은 수치를 다시 정리하면 이렇다.
- Accuracy:
0.9874 - Precision:
1.0000 - Recall:
0.9008 - F1-score:
0.9478
숫자도 중요하지만, 이번 스터디에서 더 크게 남은 것은 과정이었다. 직접 전처리하고, 직접 비교하고, 직접 기준을 바꾸면서 “어떤 모델이 더 좋은가”보다 “어떤 실수를 더 줄일 것인가”를 계속 고민했던 과정이 가장 공부가 많이 됐다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.