5월 4일부터 DeToks Phase 2가 시작됐다. Phase 1 최종 발표를 끝낸 지 얼마 되지 않은 시점이라, 처음에는 그동안 못 붙였던 기능을 더 붙이면 된다고 생각했다. Claude adapter를 확장하고, Web Metrics를 만들고, @ 기능과 Dashboard를 정리하면 Phase 2도 꽤 그럴듯하게 완성될 것 같았다.
그런데 발표자료를 다시 만들면서 생각이 조금 바뀌었다. Phase 1에서 우리가 확인한 건 “토큰을 줄일 수 있다”는 사실이었지만, Phase 2에서 계속 같은 방향으로만 가면 프로젝트가 너무 좁아질 것 같았다. 프롬프트를 줄이는 도구로만 남으면 DeToks가 할 수 있는 말은 결국 하나였다.
입력을 줄이면 토큰이 줄어든다.맞는 말이지만, 이 말만으로는 부족했다. AI 코딩 도구를 쓰면서 정말 피곤했던 건 단순히 토큰 숫자가 아니었다. 같은 설명을 반복해서 넣고, 이전 작업 결과를 다시 붙이고, 이미 했던 일을 또 시키고, 필요한 자료와 불필요한 자료를 매번 사람이 고르는 과정이 더 컸다.
그래서 Phase 2의 질문은 이렇게 바뀌었다.
토큰을 얼마나 줄일 수 있나?
에서
LLM을 꼭 불러야 하는 작업만 남길 수 있나?
발표자료 첫 장에는 Build Story & Technical Insight라는 제목을 넣었다. Phase 1 발표가 “우리가 무엇을 만들었는가”에 가까웠다면, Phase 2 발표는 “왜 이렇게 바꿨는가”에 가까웠다. 기능 설명보다 빌드 과정과 판단 근거를 더 많이 보여줘야 했다.
Phase 2의 발표 구조
Phase 2 발표 목차는 네 부분으로 잡았다.
1. Phase 1 Review
2. Phase 2 Pivot
3. Technical Walkthrough
4. Use Cases & Roadmap처음부터 Cache, RAG, Budget Gate를 설명하지 않은 이유가 있다. 이런 기능 이름은 개발자에게는 익숙해 보일 수 있지만, 듣는 사람 입장에서는 “그래서 왜 필요하지?”가 먼저 떠오른다. 그래서 Phase 2 발표는 Phase 1 검증에서 시작했다. 무엇이 맞았고, 무엇이 애매했고, 무엇이 틀렸는지를 먼저 보여줘야 했다.
기능을 많이 만든 것처럼 보이는 발표는 만들기 쉽다. 화면을 많이 넣고, 파이프라인을 길게 그리면 된다. 하지만 그런 발표는 끝나고 나서 기억에 잘 남지 않는다. 이번에는 오히려 반대로 가고 싶었다. 우리가 처음 세운 가설 중에서 어디까지가 진짜였는지, 그리고 그 결과 때문에 어떤 방향으로 틀었는지를 차분히 보여주는 쪽이 낫다고 봤다.
Phase 2는 5월 4일부터 5월 19일 발표일까지 이어졌다. 날짜로 보면 길지 않은 기간이었지만, 방향은 꽤 크게 바뀌었다.

처음 계획은 단순했다. Phase 1은 Token 절약을 위한 Core 기능 구현, Phase 2는 사용성 확장과 추가 기능 구현이었다. 말 그대로 Phase 1에서 만든 뼈대 위에 편의 기능을 얹는 구조였다.
그런데 Phase 1을 검증하고 나니 “추가 기능”보다 먼저 봐야 할 게 있었다. 우리가 만든 Core Flow가 실제로 어디에서 효과를 냈는지, 반대로 어디에서는 생각보다 효과가 없었는지를 다시 봐야 했다.
Phase 1의 Core Flow
Phase 1에서 DeToks는 사용자의 입력과 LLM 호출 사이에 들어갔다.
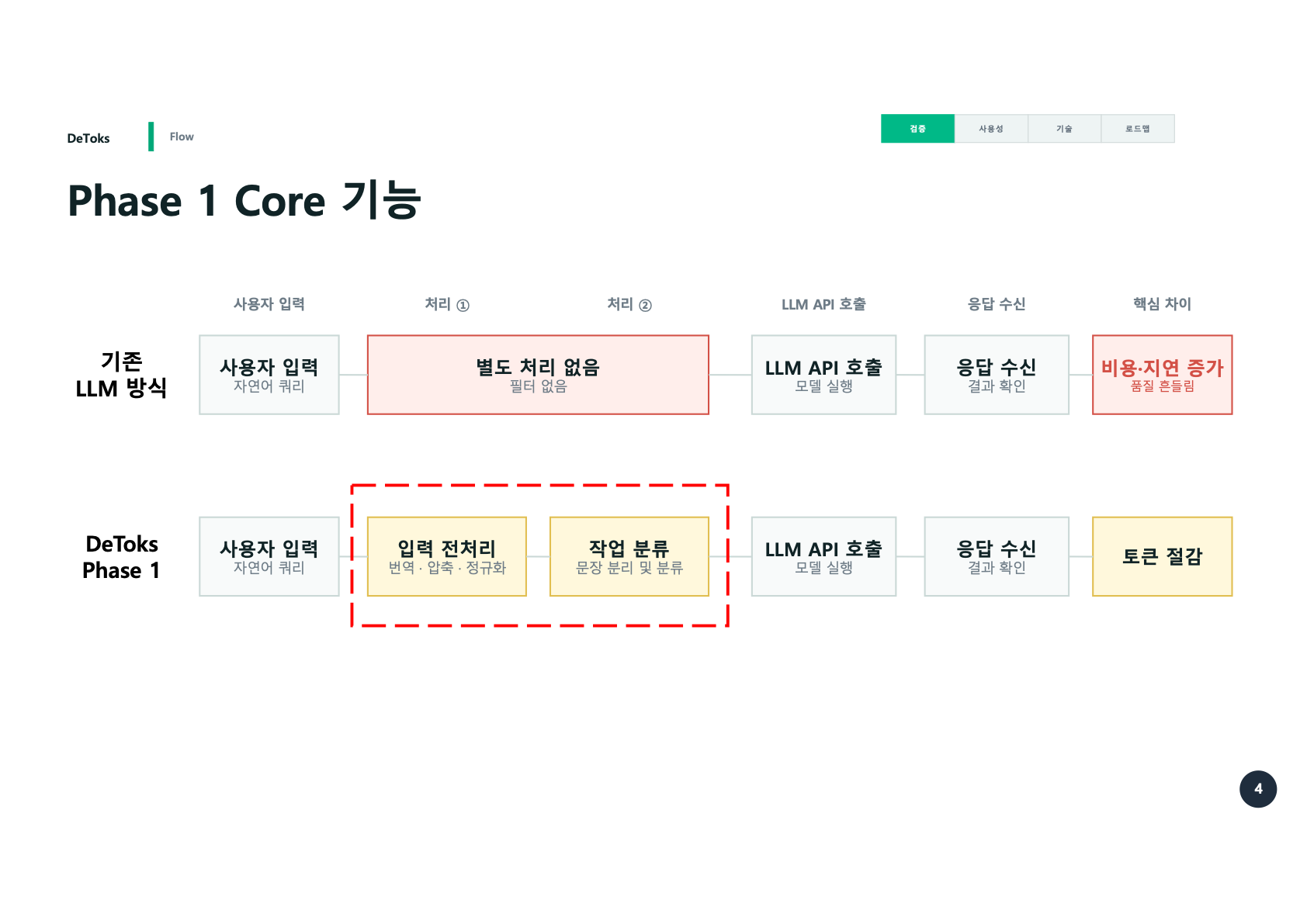
기존 방식은 사용자의 자연어 쿼리를 거의 그대로 LLM에 넘긴다. 별도 처리도 없고, 필터도 없다. 사용자는 “이전 작업도 참고해줘”, “이 조건은 유지해줘”, “아까 말한 건 빼지 말아줘” 같은 말을 계속 붙인다. 그럴수록 입력은 길어지고, 응답은 느려지고, 비용은 늘어난다.
Phase 1의 DeToks는 그 앞단에서 입력을 전처리했다.
사용자 입력
-> 번역
-> 압축
-> 정규화
-> 작업 분류
-> LLM API 호출핵심은 사용자의 말을 바로 던지지 않는 것이었다. 한국어와 영어가 섞인 입력을 모델이 이해하기 쉬운 형태로 바꾸고, 긴 표현을 줄이고, 실제 작업 단위로 나눈 뒤 실행하는 흐름을 만들었다.
당시에는 이 흐름을 Core 기능이라고 불렀다. 지금 다시 보면 이 표현도 조금 넓다. Phase 1의 Core는 “LLM 호출 전에 입력을 정리하는 구조”에 가까웠다. LLM을 부르는 횟수 자체를 줄이거나, 이전 결과를 재사용하거나, 참고 자료를 넣을지 말지를 판단하는 단계는 아직 강하지 않았다.
그래서 Phase 2를 시작하면서 먼저 Phase 1의 세 가지 가설을 다시 봤다.

가설 1
한국어를 영어로 바꾸면 토큰을 절약할 것이다.
가설 2
작업을 분류하고 정제하면 LLM 부담이 줄어들 것이다.
가설 3
전체 문맥 대신 요약 JSON을 저장하고 전달하면 줄어들 것이다.이 세 가지를 다 같은 무게로 보고 출발했지만, 결과는 같지 않았다. 어떤 가설은 꽤 선명하게 맞았고, 어떤 가설은 일부만 맞았고, 어떤 가설은 우리가 생각했던 방식으로는 증명하기 어려웠다.
가설 1: 번역은 확실히 효과가 있었다
첫 번째 가설은 비교적 깔끔하게 입증됐다.
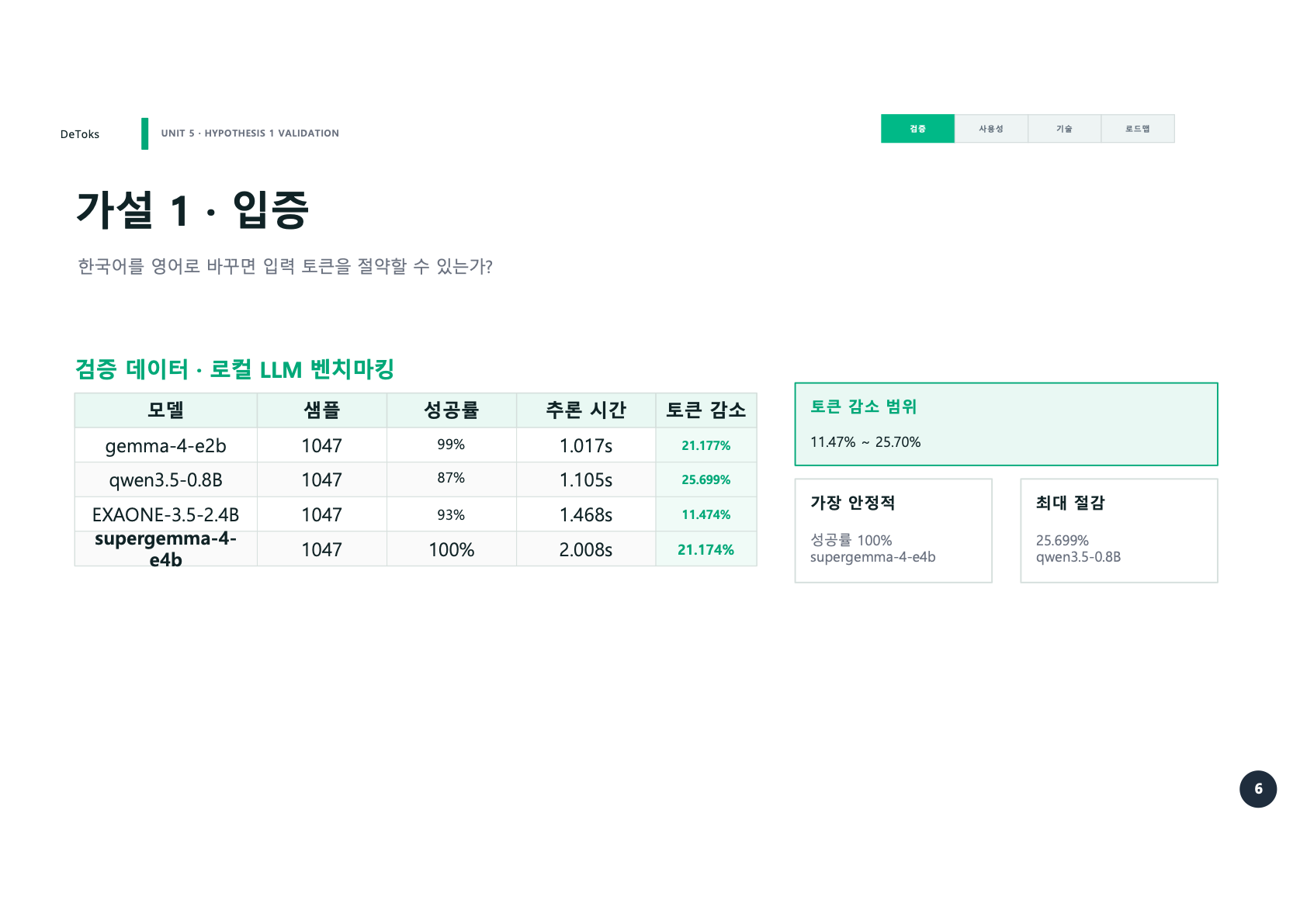
한국어를 영어로 바꾸면 입력 토큰을 줄일 수 있었다. 로컬 LLM 벤치마킹에서 모델별 차이는 있었지만, 전체적으로 11.47%에서 25.70% 사이의 토큰 감소가 확인됐다.
gemma-4-e2b
성공률 99%
추론 시간 1.017s
토큰 감소 21.177%
qwen3.5-0.8B
성공률 87%
추론 시간 1.105s
토큰 감소 25.699%
EXAONE-3.5-2.4B
성공률 93%
추론 시간 1.468s
토큰 감소 11.474%
supergemma-4-e4b
성공률 100%
추론 시간 2.008s
토큰 감소 21.174%숫자만 보면 qwen3.5-0.8B가 가장 많이 줄였다. 하지만 이 모델은 성공률이 87%였다. 개발 프롬프트에서는 이 차이가 꽤 크다. 조금 더 많이 줄이는 것보다, 중요한 단어를 망가뜨리지 않는 게 먼저다. MySQL, PostgreSQL, migration, auth 같은 단어가 한 번 틀어지면 뒤에서 절약한 토큰보다 더 많은 수정 비용이 생긴다.
그래서 발표에서는 가장 안정적인 모델로 supergemma-4-e4b를 강조했다. 성공률 100%와 21%대 토큰 감소는 Phase 1의 방향을 뒷받침하기에 충분했다.

이 결과는 우리에게 꽤 힘이 됐다. 적어도 “한국어 개발 요청을 영어로 안정화하면 토큰을 줄일 수 있다”는 말은 숫자로 보여줄 수 있었다. 하지만 동시에 한계도 보였다. 번역은 입력을 줄이는 방법이지, 이미 끝난 작업을 다시 하지 않게 만드는 방법은 아니었다.
말하자면 번역은 좋은 출발점이었다. 하지만 DeToks가 여기서 멈추면 “프롬프트 번역기”에 가까워진다. 우리가 원했던 건 그보다 조금 더 넓었다.
가설 2: 정제와 압축은 맞았지만, 분류는 애매했다
두 번째 가설은 더 복잡했다.

정제와 압축은 효과가 있었다. 허깅페이스의 153개 한국어 복합 프롬프트 데이터셋으로 비교했을 때, DeToks를 쓰지 않은 입력은 3,784 tokens였고, DeToks를 거친 입력은 2,424 tokens였다.
발표자료에는 이렇게 정리했다.
DeToks 미사용: 3,784 tokens
DeToks 사용: 2,424 tokens
번역 절감: 30.243%
압축 절감: 6.507%
fallback: 2건여기까지는 괜찮았다. 긴 문장을 정리하고, 반복되는 표현을 줄이고, 모델이 이해하기 쉬운 형태로 만드는 일은 실제로 입력 토큰을 줄였다.
문제는 작업 분류였다. 우리는 처음에 작업을 분류하면 LLM의 부담도 줄어들 것이라고 봤다. 예를 들어 어떤 요청이 탐색인지, 분석인지, 수정인지, 검증인지 미리 나눠주면 모델이 더 적은 맥락으로도 안정적으로 움직일 것이라고 생각했다.
그런데 발표를 준비하면서 이 부분은 조심스럽게 말해야 한다고 판단했다.
정제와 압축은 효과가 있었다.
하지만 분류 단계가 별도 절감 효과를 만들었다고 보기는 어렵다.LLM은 이미 사용자의 의도를 어느 정도 잘 분류한다. “이 파일을 보고 버그를 찾아줘”와 “이 코드를 수정해줘”의 차이는 모델도 잘 안다. 그래서 단순히 우리가 analyze, modify, validate 같은 type을 붙였다고 해서 입력 토큰이 바로 줄었다고 말하기는 어려웠다.
물론 분류가 의미 없었다는 뜻은 아니다. 분류는 토큰 절감보다 실행 흐름 관리에 더 가까웠다. 작업을 나누고, 어떤 작업이 먼저인지 정하고, 끝난 작업과 남은 작업을 구분하는 데 필요했다. 다만 Phase 1의 가설처럼 “분류 자체가 LLM 부담을 줄인다”라고 말하면 과장이 될 수 있었다.
그래서 발표자료에는 이 가설을 부분 입증으로 표시했다.

이 장을 만들면서 오히려 프로젝트의 방향이 더 분명해졌다. 우리가 만든 Task Graph는 토큰을 직접 줄이기 위한 기능이라기보다, 이후 Cache와 RAG와 Budget Gate가 동작할 수 있게 작업 단위를 만들어주는 기반이었다.
입력을 task로 나누지 않으면 “어떤 작업을 이미 했는지”를 판단하기 어렵다. task가 없으면 cache도 전체 요청 단위로만 볼 수 있고, RAG도 어떤 작업에 어떤 자료가 필요한지 세밀하게 고르기 어렵다. 결국 분류와 작업 분해는 직접 절감 장치가 아니라, 더 큰 절감을 가능하게 하는 구조였다.
가설 3: 요약 JSON은 출력이 길수록 강해졌다
세 번째 가설은 다시 선명하게 맞았다.
AI 코딩 도구를 쓰다 보면 한 번의 출력이 꽤 길어진다. 코드 설명, 수정 결과, 검증 로그, 다음 단계 제안까지 붙으면 몇 KB는 금방 쌓인다. 문제는 다음 요청에서 이 전체 출력을 다시 넣는 경우가 많다는 점이다.
사람은 “아까 그 결과 참고해서 이어서 해줘”라고 말하지만, 모델 입장에서는 그 “아까”를 보려면 실제 텍스트가 다시 들어와야 한다. 이전 출력 전체를 그대로 넣으면 context가 빠르게 커진다.
그래서 Phase 1에서는 완료 task 결과를 요약 JSON과 상태 메타데이터로 저장했다. 다음 요청에서는 전체 raw output을 다시 넣는 대신, 필요한 요약만 재구성해서 context로 쓰는 방향을 잡았다.
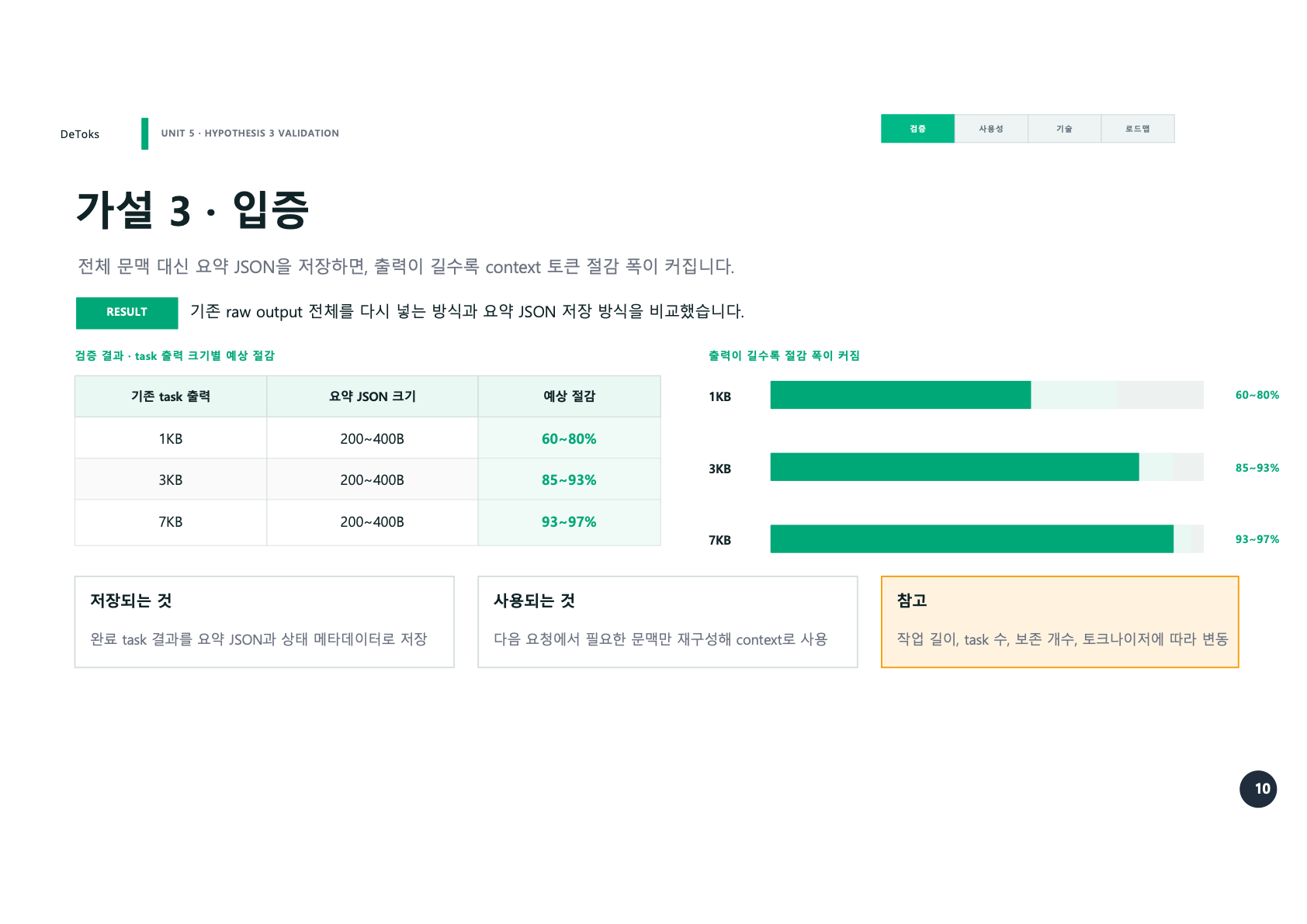
발표자료에서는 출력 크기별 예상 절감 폭을 이렇게 정리했다.
1KB 출력 -> 200~400B 요약
예상 절감 60~80%
3KB 출력 -> 200~400B 요약
예상 절감 85~93%
7KB 출력 -> 200~400B 요약
예상 절감 93~97%여기서 중요한 건 출력이 길어질수록 절감 폭이 커진다는 점이었다. 짧은 작업에서는 요약 JSON의 이점이 작게 보일 수 있다. 하지만 작업이 길어지고, task가 많아지고, 세션이 이어질수록 raw output을 그대로 들고 가는 방식은 금방 무거워진다.
이 가설은 Phase 2의 방향과도 잘 맞았다. Phase 2에서 우리가 하고 싶은 건 단순히 현재 입력을 줄이는 게 아니었다. 이전 결과를 저장하고, 필요한 만큼만 다시 꺼내고, 굳이 다시 실행하지 않아도 되는 작업은 건너뛰는 구조를 만들고 싶었다.

세 가지 가설을 정리하면 이랬다.
가설 1
번역 절감 효과 확인
가설 2
정제와 압축은 효과 있음
분류의 별도 절감 효과는 검증하지 못함
가설 3
출력이 길수록 요약 JSON의 context 절감 폭 증가이 결과를 보고 나니 Phase 2를 단순한 기능 추가 기간으로 쓰면 아깝다는 생각이 들었다. Phase 1에서 이미 효과가 확인된 부분은 있었다. 하지만 동시에 “입력을 줄이는 것만으로는 부족하다”는 것도 보였다.
그래서 무엇이 부족했나
Phase 1 흐름을 다시 그려보면 한계가 더 잘 보였다.
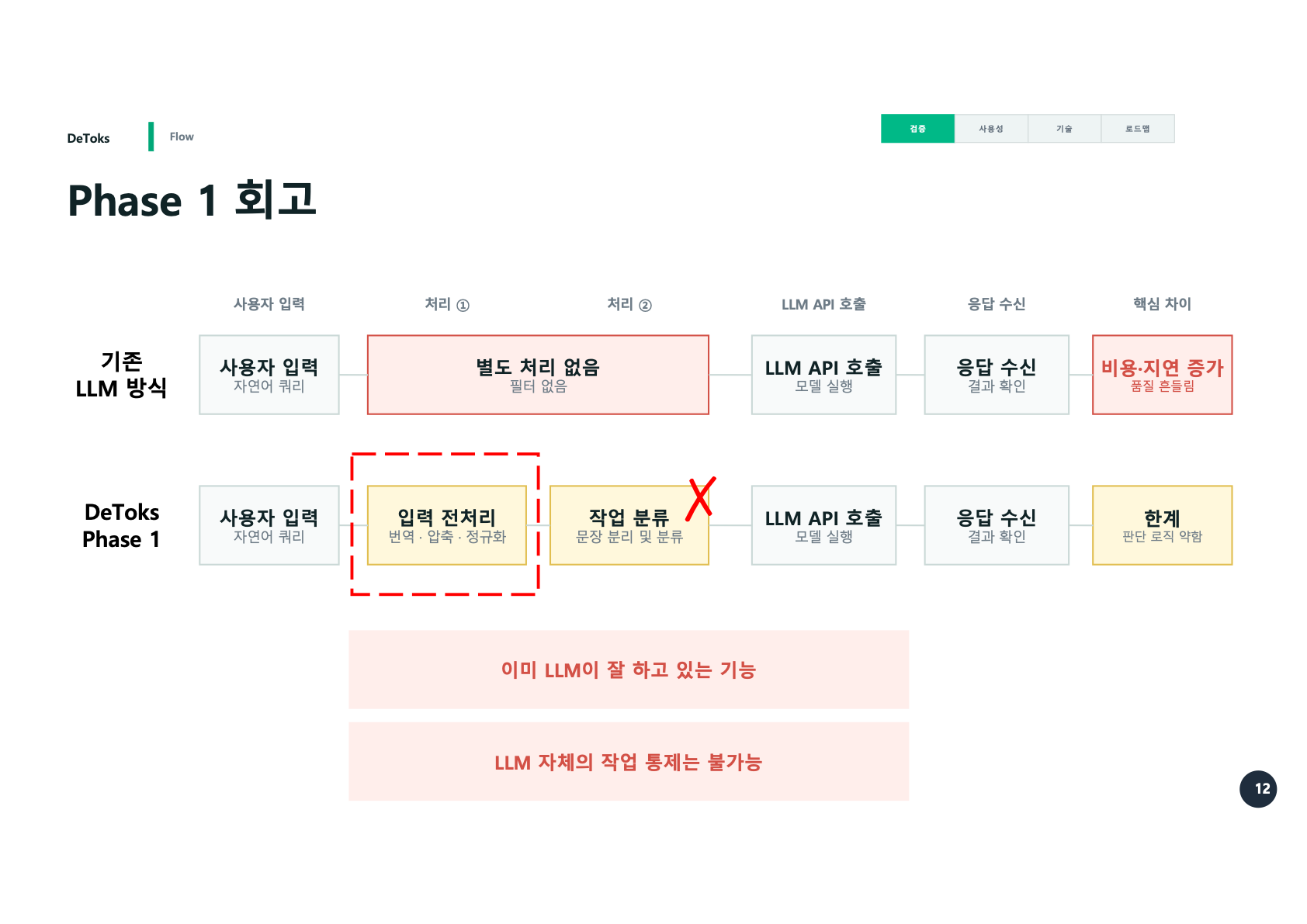
Phase 1의 DeToks는 입력 전처리와 작업 분류에 강했다. 하지만 판단 로직은 아직 약했다. 이미 LLM이 잘 하고 있는 기능을 앞에서 한 번 더 하기도 했고, LLM 자체의 작업 통제는 여전히 어려웠다.
여기서 “통제”라는 말을 너무 거창하게 쓰고 싶지는 않다. 우리가 모델 내부를 바꿀 수 있는 건 아니다. 모델이 어떤 단어를 어떻게 이해하는지, 다음 토큰을 어떻게 고르는지 직접 제어할 수는 없다. 하지만 모델을 부르기 전후의 흐름은 바꿀 수 있다.
예를 들면 이런 것들이다.
같은 요청이면 다시 실행하지 않는다.
이미 끝난 task는 재사용한다.
필요한 자료만 찾아온다.
찾아온 자료도 무조건 넣지 않는다.
context를 넣을 가치가 있을 때만 넣는다.이렇게 보면 Phase 2의 방향이 달라진다. 더 좋은 번역 모델을 찾는 것도 중요하고, 압축률을 조금 더 올리는 것도 의미가 있다. 하지만 그보다 큰 절감은 LLM 호출 자체를 줄이는 쪽에서 나온다.
이미 해둔 일을 다시 시키지 않는 것. 필요한 task만 실행하는 것. 참고 자료를 무작정 넣지 않는 것. 이쪽이 Phase 2의 중심이 되어야 했다.
Phase 2의 수정 계획
그래서 Phase 2 계획을 다시 잡았다.

최초 계획에서는 Phase 2를 “사용성 확장 및 추가 기능 구현”이라고 적었다. 수정 후에는 표현을 바꿨다.
절약을 위한 추가 방법 모색
사용자 편의 및 추가 기능 구현작아 보이는 문장 수정이지만, 실제 방향은 꽤 달랐다. “기능을 더 붙인다”가 아니라 “어디서 더 줄일 수 있는지 다시 찾는다”가 먼저가 됐다.
여기서부터 Cache, RAG, Budget Gate가 Phase 2의 중심으로 들어왔다.
Cache는 같은 요청이나 같은 task를 다시 실행하지 않기 위한 장치다. 전체 요청이 같으면 전체 결과를 재사용하고, 일부 task만 같으면 그 task 결과만 재사용한다. 이렇게 하면 토큰을 조금 줄이는 정도가 아니라, LLM 호출 자체를 건너뛸 수 있다.
RAG는 이전 작업이나 프로젝트 자료를 다시 찾아오는 장치다. 다만 이걸 토큰 절감 기능이라고 부르면 조금 애매하다. RAG는 직접 토큰을 줄이기보다, 필요한 참고자료를 찾는 프로젝트 메모리에 가깝다. 잘 쓰면 모델이 엉뚱한 답을 덜 하게 만들 수 있지만, 관련 없는 자료를 넣으면 오히려 context가 늘고 품질이 흔들릴 수 있다.
그래서 Budget Gate가 필요했다. RAG가 자료 후보를 가져오더라도, 그 자료를 실제 context에 넣을지는 한 번 더 판단해야 한다. context를 넣는 비용보다 얻는 이점이 작으면 빼는 게 맞다.
이 세 가지를 합치면 Phase 2의 흐름은 이렇게 바뀐다.
입력을 줄인다.
작업으로 나눈다.
이미 한 작업인지 확인한다.
필요한 자료 후보를 찾는다.
context에 넣을 가치가 있는지 판단한다.
그래도 필요한 작업만 LLM에 보낸다.이제 DeToks는 단순한 프롬프트 압축기라기보다, LLM 앞에서 작업 흐름을 정리하는 컨트롤러에 가까워졌다. 발표자료 첫 장의 문장도 그래서 “작업 흐름 컨트롤러”로 정리됐다.
Phase 2 첫날에 남긴 기준
5월 4일에 가장 중요했던 건 기능 목록을 늘리는 게 아니었다. Phase 1에서 남은 결과를 그대로 믿지 않고, 어떤 부분을 계속 가져갈지 다시 고르는 일이었다.
번역과 압축은 계속 가져간다. 실제로 토큰을 줄였고, 입력을 안정화하는 데도 도움이 됐다.
작업 분류도 버리지 않는다. 다만 “분류만으로 토큰을 줄인다”는 식으로 말하지 않는다. 분류는 Cache, RAG, 실행 흐름을 위한 기반으로 보는 게 더 정확했다.
요약 JSON 저장은 더 중요해졌다. 출력이 길어질수록 전체 문맥을 다시 넣는 방식은 부담이 커지고, 다음 요청에서 필요한 정보만 꺼내 쓰는 구조가 필요해진다.
그리고 Phase 2의 가장 큰 기준은 이것이었다.
줄일 수 있으면 줄인다.
다시 하지 않아도 되면 하지 않는다.
넣지 않아도 되는 context는 넣지 않는다.Phase 1에서는 “토큰을 줄이고도 기능이 유지되는가”를 봤다. Phase 2에서는 한 단계 더 들어가야 했다. 작업이 반복될수록 DeToks가 얼마나 덜 시키고, 덜 넣고, 덜 부르는지를 보여줘야 했다.
그때부터 DeToks의 설명도 조금 달라졌다.
Less Token, More Control.이 문장은 Phase 1 발표 때도 썼지만, Phase 2에 와서야 더 정확해졌다. Less Token은 번역과 압축만으로 끝나지 않는다. Cache로 호출을 건너뛰고, RAG로 필요한 기억만 찾고, Budget Gate로 context를 조절해야 한다.
그리고 More Control은 모델을 마음대로 조종한다는 뜻이 아니다. 모델을 부르기 전의 입력, 작업 단위, 이전 결과, 참고 자료, 실행 여부를 사람이 납득할 수 있는 구조로 관리한다는 뜻에 가깝다.
5월 4일은 그 방향을 다시 잡은 날이었다. Phase 1에서 만든 것을 부정하는 게 아니라, 어디까지가 진짜 성과였는지 확인하고, 그 위에 Phase 2의 기준을 다시 세운 날이었다.
다음 글에서는 이 방향 전환이 실제 구현에 어떤 영향을 줬는지 정리하려고 한다. 특히 설치와 실행 흐름을 줄이기 위해 Python worker와 llama-server를 걷어내고, node-llama-cpp와 Qwen GGUF 쪽으로 옮겨간 과정을 남겨둘 예정이다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.