Phase 2를 시작하면서 처음 잡은 키워드는 사용자 편의였다. 그런데 막상 우리가 만든 도구를 다시 실행해보니, 편의 기능을 더 붙이기 전에 먼저 해결해야 할 문제가 있었다.
설치와 실행이 너무 무거웠다.
Phase 1 때는 발표를 위해 어떻게든 돌아가게 만드는 게 먼저였다. 로컬 LLM도 붙여야 했고, 압축 모델도 써야 했고, CLI도 돌아가야 했다. 각 파트가 맡은 기능을 완성하는 데 집중하다 보니 실행 준비가 조금씩 복잡해졌다. 하나의 기능만 보면 납득이 됐지만, 사용자가 처음 DeToks를 실행한다고 생각하면 얘기가 달랐다.
Python 가상환경을 만들고
uv sync를 하고
GGUF 모델 경로를 맞추고
llama-server를 따로 띄우고
Python worker도 실행하고
Node CLI를 다시 실행한다이 흐름은 개발 중에는 받아들일 수 있었다. 팀원들이 어떤 서버를 띄워야 하는지 알고 있었고, 문제가 생기면 바로 옆에서 같이 봐줄 수도 있었다. 하지만 사용자에게는 너무 많은 설명이 필요했다. 사용자가 DeToks를 쓰기 전에 먼저 환경 맞추기와 서버 관리에 지치면, 그건 도구의 문제였다.

그래서 5월 8일쯤부터는 “무엇을 더 붙일까”보다 “무엇을 걷어낼 수 있을까”를 더 많이 봤다. Phase 2의 사용자 편의는 예쁜 화면이나 명령어 추가만으로 해결되는 문제가 아니었다. 사용자가 DeToks를 처음 설치하고 실행할 때, 얼마나 적은 단계로 시작할 수 있는지가 먼저였다.
예전 실행 준비
발표자료에는 예전 실행 준비를 일부러 길게 적었다.

$ npm install
$ python3.13 -m venv .venv
$ uv sync
$ export GGUF_MODEL_PATH=...
$ export API_BASE=http://localhost:...
$ ./llama-server -m model.gguf --port ...
$ npm run python-worker이 목록을 적어놓고 보니 더 분명해졌다. DeToks는 “AI CLI를 더 쉽게 쓰게 해주는 도구”인데, 정작 DeToks를 쓰려면 사용자가 여러 런타임을 직접 맞춰야 했다.
여기에는 몇 가지 문제가 있었다.
첫 번째는 진입 장벽이다. Node 프로젝트를 설치하는 것만으로도 충분히 부담이 있는데, Python 3.13, 가상환경, uv, 별도 서버, 모델 경로까지 설명해야 했다. 사용자가 이 과정을 한 번에 통과하지 못하면, DeToks의 핵심 기능을 보기도 전에 실패한다.
두 번째는 운영 부담이다. llama-server를 따로 띄우면 사용자는 포트, 모델 파일, 서버 상태를 직접 관리해야 한다. 서버가 떠 있는지, 포트가 맞는지, .env가 제대로 읽혔는지, worker가 연결됐는지 계속 확인해야 한다.
세 번째는 디버깅 경계가 흐려진다는 점이다. 문제가 생겼을 때 Node CLI 문제인지, Python worker 문제인지, llama-server 문제인지, 모델 경로 문제인지 바로 알기 어렵다. 기능이 많아서 복잡한 게 아니라 실행 경계가 많아서 복잡해졌다.
이건 Phase 2에서 꼭 정리해야 했다.
Node 쪽으로 묶기
수정 방향은 단순했다. 가능한 한 Node 기반 설치 흐름으로 묶는 것.
$ npm install @sorlros/detoks물론 이 한 줄만으로 모든 게 끝난다는 뜻은 아니다. adapter CLI나 GGUF 모델 준비는 별도일 수 있다. 그래도 최소한 DeToks 내부에서 Python worker와 llama-server를 따로 관리해야 하는 구조는 줄이고 싶었다.
그래서 로컬 추론 런타임을 node-llama-cpp 쪽으로 통합했다. 핵심은 사용자가 별도의 llama-server 프로세스를 직접 띄우지 않게 만드는 것이었다. 모델을 읽고 추론하는 경계를 Node 안으로 가져오면, CLI 입장에서는 실행 흐름을 훨씬 단순하게 만들 수 있다.
이 변화는 겉으로 보기에는 작은 선택처럼 보일 수 있다. 하지만 실제로는 꽤 큰 차이가 있었다.
이전
Node CLI -> Python worker -> llama-server -> GGUF model
이후
Node CLI -> node-llama-cpp -> GGUF model중간 계층이 줄어들면 설치 문서도 짧아진다. 실행 중에 확인해야 할 프로세스도 줄어든다. 실패했을 때 어디를 봐야 하는지도 조금 더 명확해진다.
Phase 1에서 우리에게 중요했던 건 “기능이 된다”였다. Phase 2에서 봐야 했던 건 “다시 설치해도 된다”였다. 발표장이나 팀원 노트북에서만 돌아가는 도구가 아니라, 처음 보는 사람이 따라 해도 어느 정도 예측 가능한 흐름이어야 했다.
Gemma에서 Qwen으로
런타임을 바꾸면서 모델 선택도 다시 봤다.

처음에는 Gemma 계열 모델을 실험했다. Phase 1에서는 번역 품질과 토큰 절감률을 검증하는 데 집중했기 때문에, 모델을 여러 개 비교하면서 가장 안정적인 후보를 찾았다. 하지만 Phase 2에서는 품질만 볼 수 없었다. node-llama-cpp에서 안정적으로 읽히는 GGUF 모델이어야 했고, 실제 CLI 안에서 실행 가능한 구조여야 했다.
그래서 Qwen GGUF 쪽으로 방향을 옮겼다.
발표자료에는 세 가지 후보를 비교했다.
Qwen3.5-4B GGUF
성공률 96.753%
latency 5.620s
similarity 0.906
fail 34
Qwen3.5-2B GGUF
성공률 96.466%
latency 5.779s
similarity 0.905
fail 37
DeepSeek-R1 Qwen3-8B GGUF
성공률 96.848%
latency 5.614s
similarity 0.908
fail 33여기서 similarity는 번역 결과가 원래 의미를 얼마나 잘 보존했는지 보기 위한 기준이었다. 단순히 “영어 문장이 그럴듯한가”만 보면 위험하다. 개발 요청에서는 단어 하나가 바뀌어도 의미가 틀어질 수 있다. 그래서 임베딩 cosine similarity로 의미 보존 정도를 자동 측정했다.
숫자만 보면 DeepSeek-R1 Qwen3-8B GGUF가 가장 좋아 보인다. 성공률도 조금 높고 similarity도 가장 높다. 하지만 모델 선택은 최고 숫자 하나만 보고 끝낼 수 없었다. 크기, 실행 안정성, 설치 부담, 추론 시간까지 같이 봐야 했다.
우리가 발표에서 잡은 결론은 이거였다.
번역 품질은 임베딩 유사도로 검증한다.
실행 구조는 Qwen GGUF + node-llama-cpp로 단순화한다.이 문장이 Phase 2 초반의 핵심이었다. 모델을 바꾼 이유는 단순히 “Qwen이 더 좋아서”가 아니었다. 품질을 측정하는 방식과 실행 구조를 함께 바꾸기 위한 선택이었다.
Python worker를 걷어내기
다음으로 본 건 압축 파트였다.
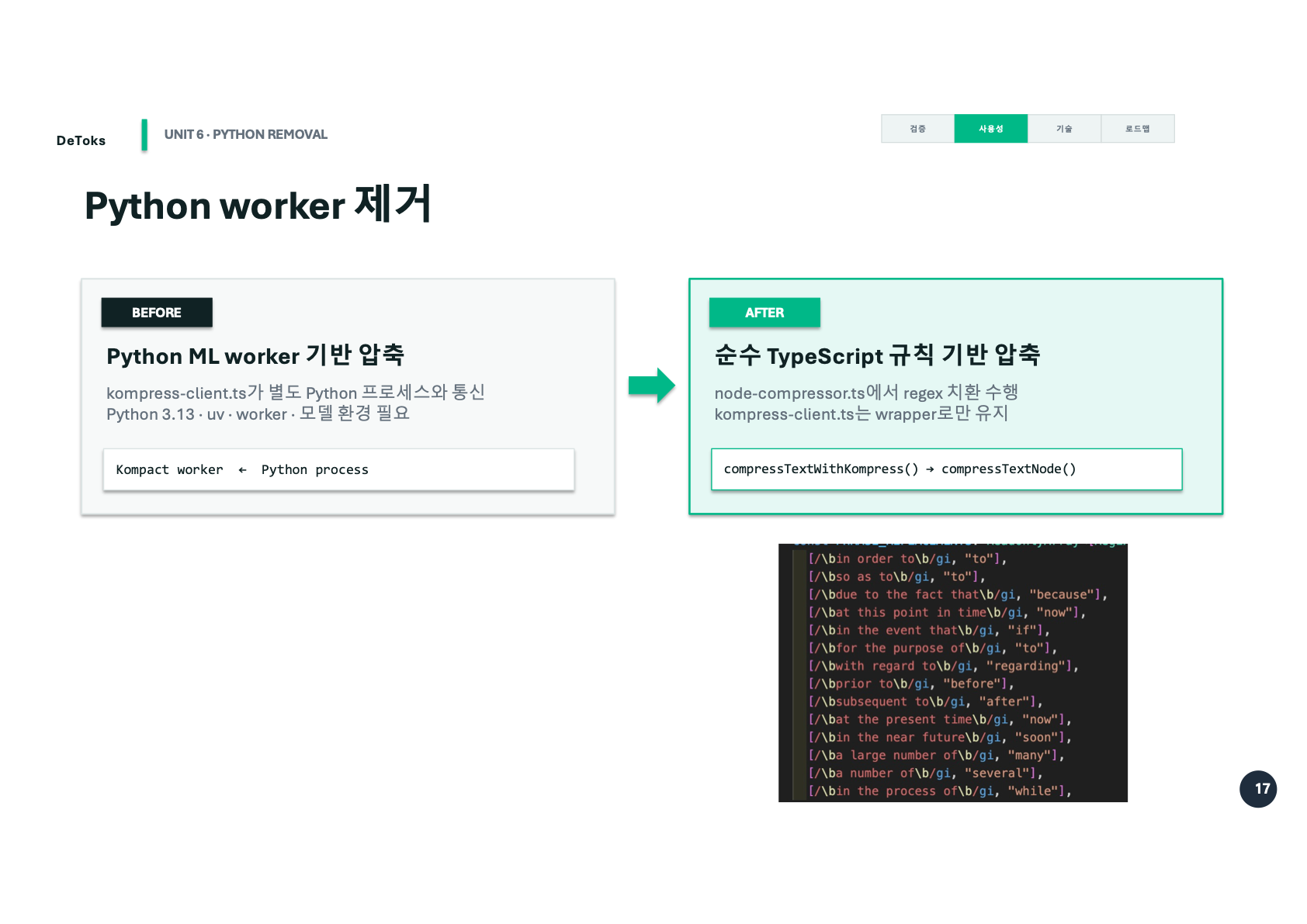
Phase 1에서는 압축을 위해 Python ML worker를 붙였다. kompress-client.ts가 별도 Python 프로세스와 통신하고, 그쪽에서 압축 결과를 받아오는 구조였다. 그 자체로는 나쁘지 않았다. 이미 검증된 압축 모델을 쓰는 방식이었고, 실험 결과도 있었다.
하지만 Phase 2 관점에서는 다시 문제가 보였다.
Python 3.13 필요
uv 필요
worker 프로세스 필요
모델 환경 필요
Node CLI와 Python worker 연결 필요압축률을 조금 더 얻기 위해 사용자가 감당해야 하는 실행 부담이 너무 컸다. 특히 DeToks의 목표를 생각하면 더 그랬다. 우리는 사용자가 AI CLI를 더 반복 가능하게 쓰도록 돕고 싶었다. 그런데 그 과정에서 또 다른 실행 환경을 만들고, 또 다른 프로세스를 띄우게 한다면 방향이 맞지 않았다.
그래서 Phase 2에서는 순수 TypeScript 규칙 기반 압축으로 바꿨다.
이전
kompress-client.ts -> Python process -> Kompact worker
이후
kompress-client.ts -> node-compressor.ts -> regex 기반 치환kompress-client.ts는 wrapper 역할로 남기고, 실제 압축은 compressTextNode() 쪽으로 넘겼다. 압축 모델을 완전히 버렸다는 느낌보다는, 발표와 패키징 시점에 맞춰 실행 부담을 줄이는 선택이었다.
여기서 중요한 건 솔직함이었다. 규칙 기반 압축이 모든 면에서 ML 압축보다 낫다고 말할 수는 없다. 어떤 문장에서는 모델 기반 압축이 더 자연스럽고, 더 많이 줄일 수도 있다. 하지만 DeToks가 실제 CLI 도구로 쓰이려면 설치와 실행이 먼저 안정되어야 했다.
좋은 기능도 사용자가 실행하지 못하면 의미가 없다. Phase 2에서는 이 기준을 꽤 자주 떠올렸다.
기능을 줄인 게 아니라 경계를 줄인 것
이 작업을 하면서 느낀 건, 단순화가 꼭 기능 축소는 아니라는 점이었다.
처음에는 Python worker를 제거하면 무언가를 잃는 느낌이 있었다. llama-server를 걷어내는 것도 비슷했다. 이미 만들어둔 실행 경로가 있고, 그 위에서 검증한 결과도 있는데, 그걸 다시 바꾸는 일은 늘 부담스럽다.
하지만 실제로는 기능을 줄인 게 아니라 경계를 줄인 쪽에 가까웠다.
서버를 따로 띄우는 경계
Python worker와 통신하는 경계
환경변수를 여러 곳에서 맞추는 경계
실패 원인을 여러 런타임에서 찾는 경계이런 경계가 줄어들수록 사용자는 DeToks를 더 쉽게 시작할 수 있다. 개발자 입장에서도 테스트와 디버깅이 쉬워진다. 같은 오류를 보더라도 확인해야 할 범위가 줄어든다.
Phase 1에서는 여러 기능이 각자 살아 있어야 했다. Phase 2에서는 그 기능들이 하나의 도구처럼 보이도록 묶어야 했다. 이 차이가 생각보다 컸다.
발표에서 보여줘야 했던 변화
이 파트를 발표자료로 만들 때는 “우리가 라이브러리를 바꿨다” 정도로 보이면 안 된다고 생각했다. node-llama-cpp라는 이름만 말하면 듣는 사람에게는 내부 구현 교체처럼 느껴질 수 있다. 하지만 실제로 보여주고 싶었던 건 구현체 교체가 아니라 사용자 경험의 변화였다.
발표 문장도 그래서 설치 명령을 중심으로 잡았다.
이전에는 여러 런타임과 서버를 직접 맞춰야 했다.
이제는 Node 기반 흐름으로 묶었다.이 차이는 개발자가 도구를 처음 만질 때 바로 체감된다. 무언가를 설치할 때 가장 불안한 순간은 “내가 지금 무엇을 띄워야 하는지 모르겠다”는 느낌이 들 때다. 서버를 하나 띄웠는데 CLI가 연결되지 않고, 환경변수를 맞췄는데 worker가 다른 값을 보고 있고, 모델 파일은 있는데 어떤 프로세스가 그 파일을 읽는지 모르면 금방 지친다.
DeToks가 그런 도구가 되면 안 됐다. 우리가 만들고 있는 건 AI CLI를 쓰는 부담을 줄이는 도구인데, DeToks 자체가 또 다른 부담이 되면 방향이 틀어진다.
그래서 발표에서는 설치 단계를 단순히 줄였다고 말하는 것보다, 부담의 종류가 바뀌었다고 설명하고 싶었다.
서버 관리 부담
프로세스 연결 부담
Python 환경 부담
모델 경로 확인 부담
실패 원인 추적 부담이런 부담을 줄이는 게 Phase 2 초반의 핵심이었다.
왜 지금 정리해야 했나
이 작업은 나중에 해도 되는 일처럼 보일 수도 있었다. 기능을 먼저 완성하고, 마지막에 패키징할 때 설치 흐름을 정리하는 방식도 가능하다. 하지만 DeToks에서는 그렇게 미루기 어려웠다.
이유는 간단했다. Phase 2의 다음 기능들이 모두 실행 흐름 위에 올라가기 때문이다.
Cache가 제대로 보이려면 같은 요청을 반복 실행할 수 있어야 한다. RAG가 의미 있으려면 세션과 저장소가 안정적으로 이어져야 한다. Budget Gate를 설명하려면 adapter 실행 전에 context를 조절하는 흐름이 분명해야 한다.
런타임이 여러 군데로 흩어져 있으면 이 모든 설명이 어려워진다.
cache가 안 맞은 건가?
worker가 안 돈 건가?
llama-server가 안 떠 있는 건가?
모델이 못 읽힌 건가?
adapter가 실패한 건가?이 질문들이 섞이면 Phase 2의 핵심을 검증하기 어렵다. 그래서 설치와 실행 흐름 정리는 발표 막판의 포장 작업이 아니라, Phase 2 기술 본론을 설명하기 위한 전제였다.
사용자 편의라는 말의 의미
발표자료에는 이 파트를 사용자 편의라고 묶었다. 처음에는 조금 평범한 표현처럼 느껴졌다. 하지만 작업을 하다 보니 이 말이 꽤 정확했다.
사용자 편의는 꼭 버튼을 예쁘게 만드는 게 아니다. CLI에서 친절한 문구를 보여주는 것도 중요하지만, 그 전에 사용자가 도구를 켤 수 있어야 한다. 설치 문서를 읽다가 포기하지 않아야 하고, 모델 서버를 띄우다가 막히지 않아야 하고, worker가 연결되지 않았다는 오류를 보고 어디부터 봐야 할지 헤매지 않아야 한다.
이번 작업은 그런 의미의 사용자 편의였다.
더 적은 런타임
더 적은 프로세스
더 적은 환경변수
더 짧은 설치 흐름
더 명확한 실패 지점이걸 정리하고 나서야 다음 단계로 넘어갈 수 있었다. Cache, RAG, Budget Gate 같은 Phase 2의 핵심 기능은 실행 흐름 위에 올라간다. 밑에 있는 런타임이 흔들리면 그 위의 기능도 불안해진다.
Phase 2 초반의 결론
5월 8일자 글로 남기고 싶은 결론은 간단하다.
Phase 2의 첫 개선은 화려한 기능 추가가 아니었다. 오히려 덜어내는 일이었다.
llama-server를 따로 띄우지 않게 한다.
Python worker에 기대지 않는다.
Node 기반 실행 흐름으로 묶는다.
GGUF 모델은 node-llama-cpp에서 안정적으로 읽히는 쪽으로 고른다.
압축은 TypeScript 안에서 처리한다.이렇게 정리하고 나니 DeToks가 조금 더 도구처럼 느껴졌다. Phase 1에서는 각 기능을 증명하는 데 집중했다면, Phase 2에서는 사용자가 실제로 만지는 실행 흐름을 줄이기 시작했다.
다음 단계는 호출을 줄이는 일이었다. 런타임을 단순화한 뒤에는, 같은 요청을 다시 실행하지 않고, 필요한 task만 보내고, 참고 자료도 무조건 넣지 않는 구조를 봐야 했다.
그게 Phase 2의 진짜 기술 본론이었다. Cache, RAG, Budget Gate는 그 지점에서 들어왔다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.