Phase 2에서 가장 크게 바뀐 점은 “입력을 줄인다”에서 “호출을 줄인다”로 중심이 옮겨간 것이다.
Phase 1에서는 사용자의 긴 한국어 입력을 영어로 바꾸고, 압축하고, 작업 단위로 나누는 흐름을 만들었다. 그 결과 입력 토큰을 줄일 수 있다는 건 어느 정도 확인했다. 하지만 실제로 AI CLI를 오래 쓰다 보면, 입력 하나를 줄이는 것만으로는 부족했다.
더 큰 낭비는 반복에서 나왔다.
같은 요청을 다시 보내고, 이미 분석한 내용을 다시 분석하고, 이전에 만든 결과를 다시 설명하고, 참고하지 않아도 되는 자료까지 context에 붙이는 일이 계속 생겼다. 이럴 때는 프롬프트를 조금 짧게 만드는 것보다, 애초에 다시 실행하지 않는 쪽이 더 큰 절감이었다.
그래서 Phase 2의 기술 흐름은 이렇게 바뀌었다.
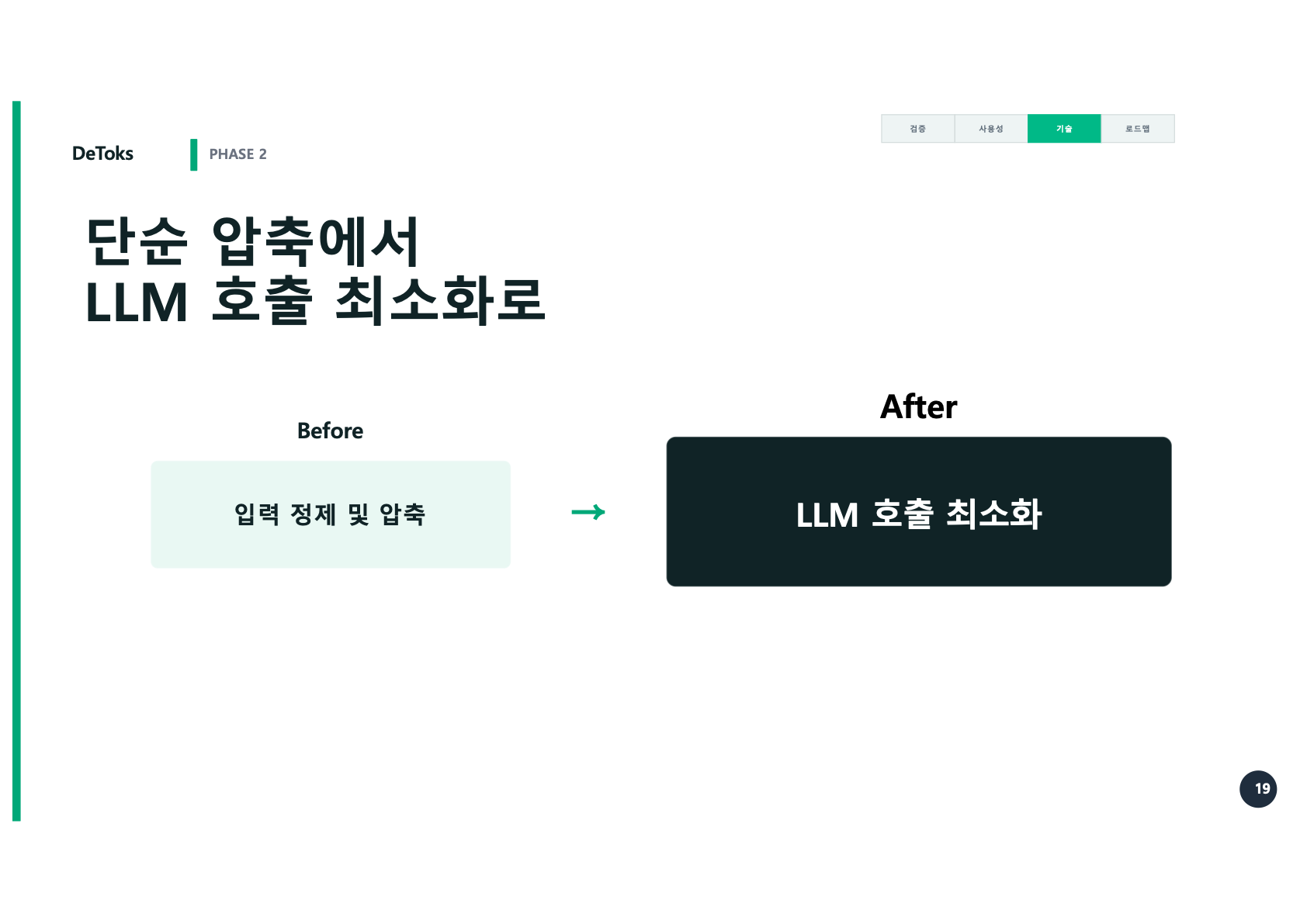
입력 정제 및 압축
에서
입력 정제 및 압축 + LLM 호출 최소화표현은 짧지만, 내부 구조는 꽤 달라졌다. Cache, RAG, Budget Gate가 이 흐름 안으로 들어왔다.
요청 하나를 끝까지 따라가기
발표자료에서는 하나의 예시 요청을 잡고 전체 흐름을 설명했다.
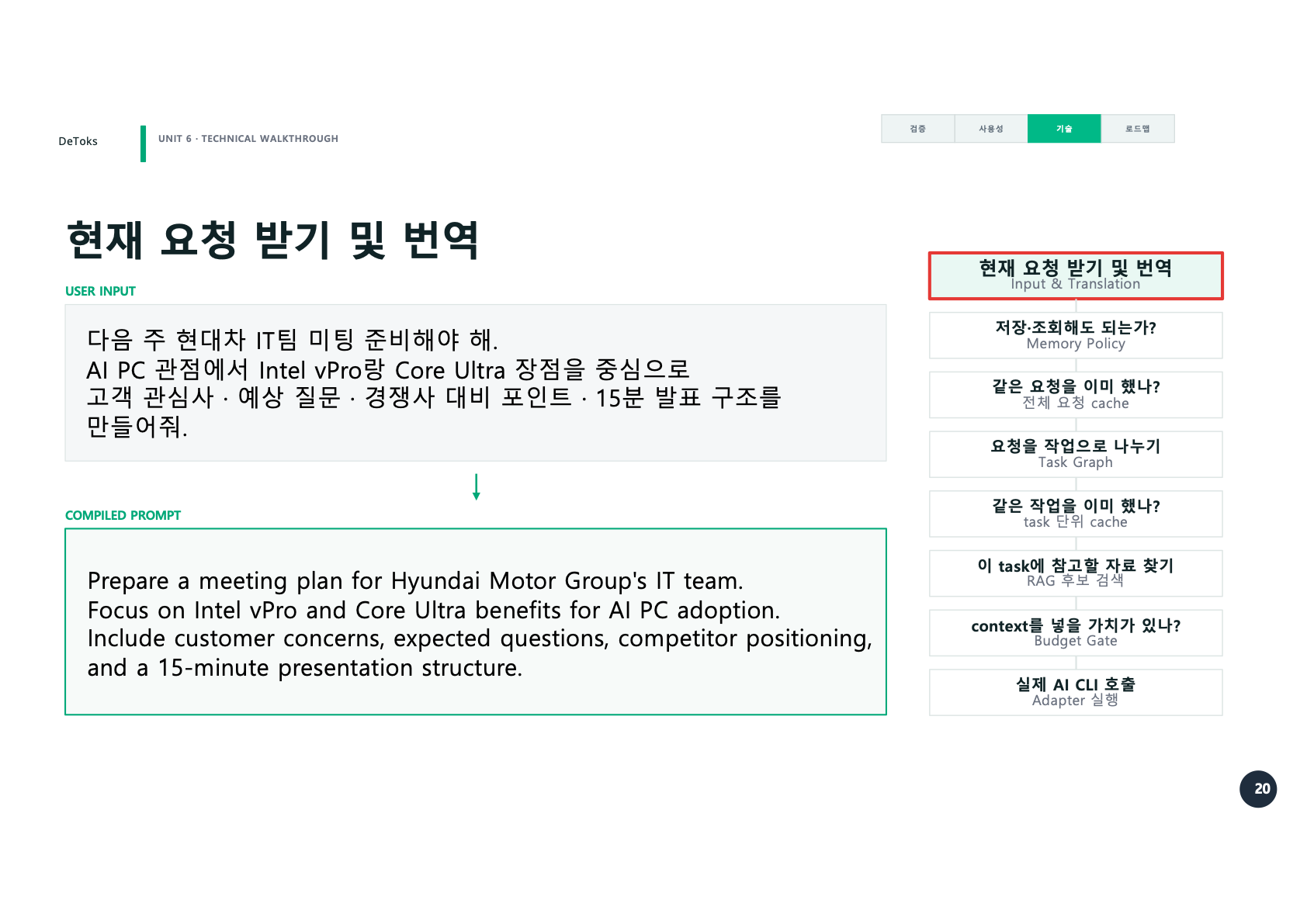
예시는 현대차 IT팀 미팅 준비 요청이었다.
다음 주 현대차 IT팀 미팅 준비해야 해.
AI PC 관점에서 Intel vPro랑 Core Ultra 장점을 중심으로
고객 관심사, 예상 질문, 경쟁사 대비 포인트, 15분 발표 구조를
만들어줘.DeToks는 이 요청을 바로 AI CLI에 던지지 않는다. 먼저 입력을 번역하고 정리한다.
Prepare a meeting plan for Hyundai Motor Group's IT team.
Focus on Intel vPro and Core Ultra benefits for AI PC adoption.
Include customer concerns, expected questions, competitor positioning,
and a 15-minute presentation structure.여기까지는 Phase 1에서도 하던 일이다. Phase 2에서 달라진 건 그 다음이다. 번역된 prompt를 바로 실행하지 않고, 몇 가지 질문을 차례대로 확인한다.
저장하고 조회해도 되는가?
같은 요청을 이미 했나?
요청을 어떤 task로 나눌 수 있나?
각 task를 이미 처리한 적이 있나?
참고할 만한 과거 자료가 있나?
그 자료를 context에 넣을 가치가 있나?
그래도 필요한 task만 실행한다.이 순서가 Phase 2의 핵심이었다. DeToks가 LLM 앞에서 하는 일이 단순히 문장을 줄이는 게 아니라, 실행할 가치가 있는 작업만 남기는 쪽으로 바뀌었다.
Memory Policy: 먼저 써도 되는지 확인한다
첫 단계는 Memory Policy였다.
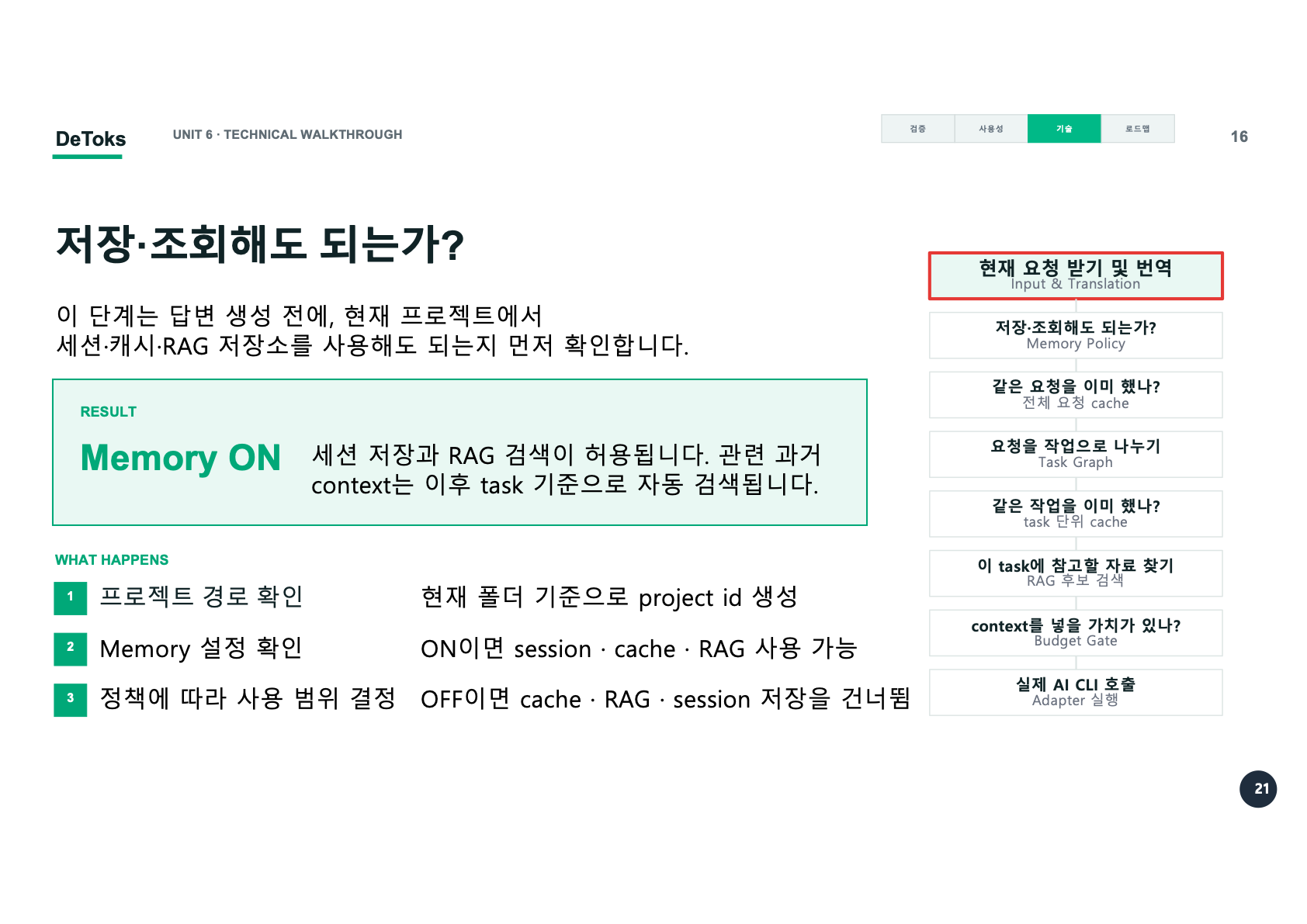
이 단계는 답변을 만들기 전에, 현재 프로젝트에서 세션, cache, RAG 저장소를 써도 되는지 확인한다. 기능을 만들 때는 “저장하면 편하다”만 생각하기 쉽다. 하지만 실제 도구에서는 언제나 저장 여부를 먼저 봐야 한다.
현재 폴더를 기준으로 project id를 만들고, memory 설정을 확인한다. Memory가 켜져 있으면 session, cache, RAG를 사용할 수 있다. 꺼져 있으면 cache 조회, RAG 검색, session 저장을 건너뛴다.
Memory ON
세션 저장 가능
cache 조회 가능
RAG 검색 가능
Memory OFF
session 저장 건너뜀
cache 조회 건너뜀
RAG 검색 건너뜀이 단계는 토큰 절감처럼 보이지 않을 수도 있다. 하지만 흐름 전체에서는 중요하다. 저장과 조회가 허용되지 않은 상태에서 cache나 RAG를 쓰면 안 된다. DeToks가 기억을 쓰기 전에 먼저 “기억을 써도 되는가”를 확인하는 구조가 필요했다.
발표에서는 이걸 크게 강조하지 않았지만, 실제 도구로 보면 꽤 중요한 경계였다. 사용자의 작업 폴더와 설정에 따라 memory를 쓸 수도 있고, 쓰지 않을 수도 있어야 한다.
F1 Cache: 같은 요청은 다시 하지 않는다
Memory Policy를 통과하면 전체 요청 cache를 확인한다.
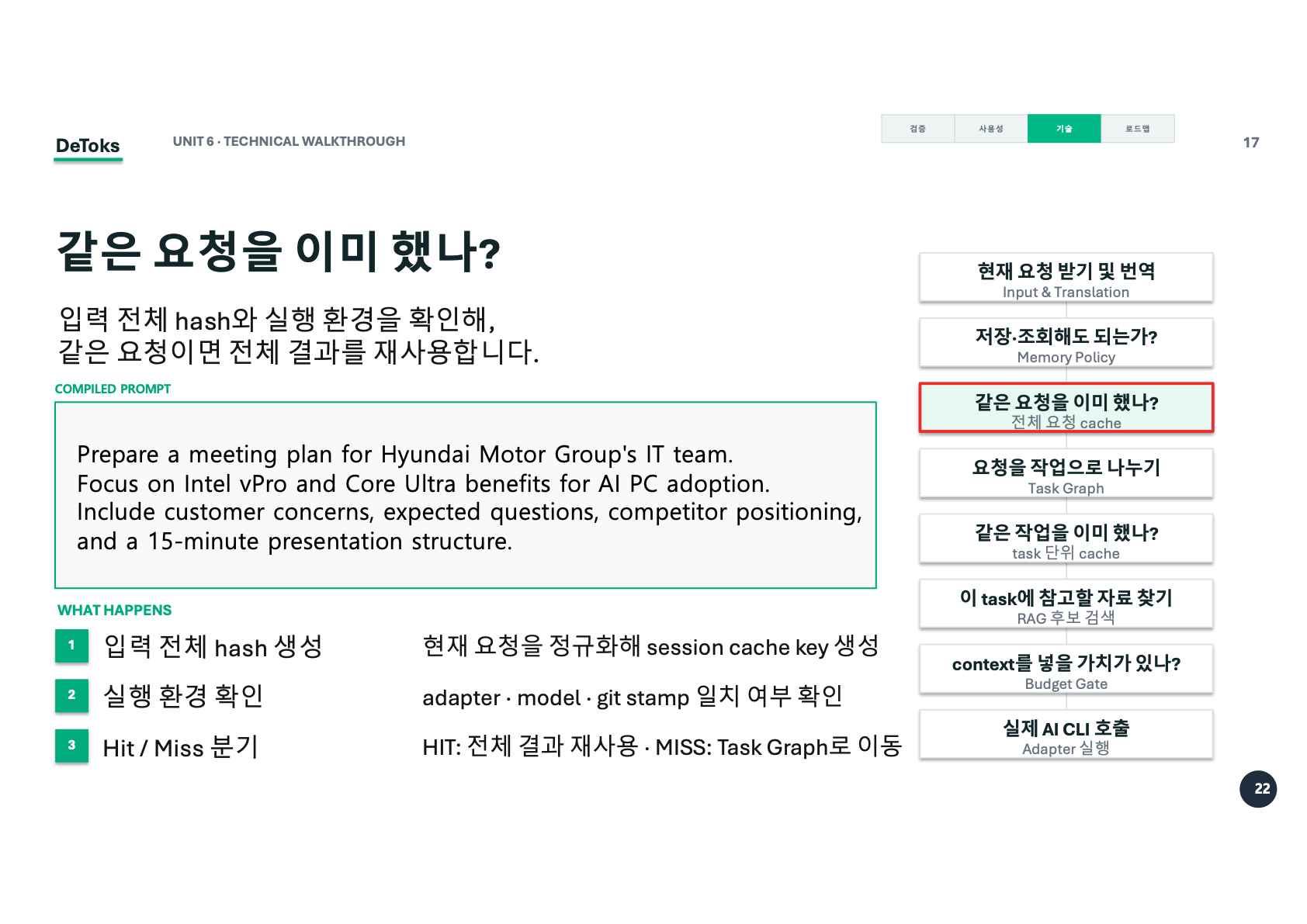
이 단계는 입력 전체를 기준으로 본다. 사용자의 현재 요청을 정규화하고 hash를 만든 뒤, 실행 환경이 같은지 확인한다. adapter, model, git stamp 같은 조건이 맞으면 이전 결과를 재사용할 수 있다.
입력 전체 hash 생성
실행 환경 확인
HIT / MISS 분기여기서 HIT가 나면 가장 좋다. 전체 결과를 그대로 재사용할 수 있기 때문이다. LLM을 부르지 않아도 되고, task를 다시 나누지 않아도 된다. 토큰을 줄이는 정도가 아니라 실행 자체를 건너뛰는 셈이다.
반대로 MISS가 나면 Task Graph 단계로 내려간다. 전체 요청은 같지 않지만, 그 안에 포함된 일부 task는 과거와 같을 수 있기 때문이다.
이게 Phase 2에서 cache를 두 단계로 본 이유였다.
F1 cache
전체 요청 단위로 재사용
F2 cache
task 단위로 재사용전체 요청이 완전히 같으면 F1에서 끝난다. 전체 요청이 조금 달라졌더라도, 그 안의 일부 작업이 이미 처리한 작업이면 F2에서 줄일 수 있다.
Task Graph: 요청을 실행 가능한 단위로 나눈다
전체 요청 cache에서 MISS가 나면, DeToks는 요청을 task로 나눈다.

현대차 IT팀 미팅 준비 요청은 이렇게 나눌 수 있다.
Task 1
Understand Hyundai IT team context
Task 2
Map vPro / Core Ultra benefits to AI PC adoption
Task 3
Prepare customer questions and competitor positioning
Task 4
Build a 15-minute presentation agenda여기서 Task Graph는 단순한 보기용 구조가 아니다. Phase 1에서는 task type과 의존성 정리에 더 가까웠다면, Phase 2에서는 cache와 RAG를 적용하기 위한 기준점이 됐다.
요청 전체가 다르더라도 task 단위로 보면 겹치는 일이 많다. 예를 들어 지난번에 이미 “Hyundai IT팀의 관심사”를 정리한 적이 있다면, 이번 요청에서도 그 부분은 다시 실행하지 않아도 된다. 반대로 “이번 15분 발표 구조”는 새로 만들어야 할 수도 있다.
task로 나누지 않으면 이런 판단을 할 수 없다. 전체 요청이 같냐 다르냐만 보게 된다. 하지만 task로 나누면 어떤 부분은 재사용하고, 어떤 부분만 새로 실행할지 나눌 수 있다.
그래서 Task Graph는 Phase 2에서 더 중요해졌다. 분류 자체가 토큰을 직접 줄인다고 말하기는 어렵지만, task 단위 cache와 RAG를 가능하게 하는 기반이 됐다.
F2 Cache: 이미 한 task는 재사용한다
다음은 task 단위 cache다.
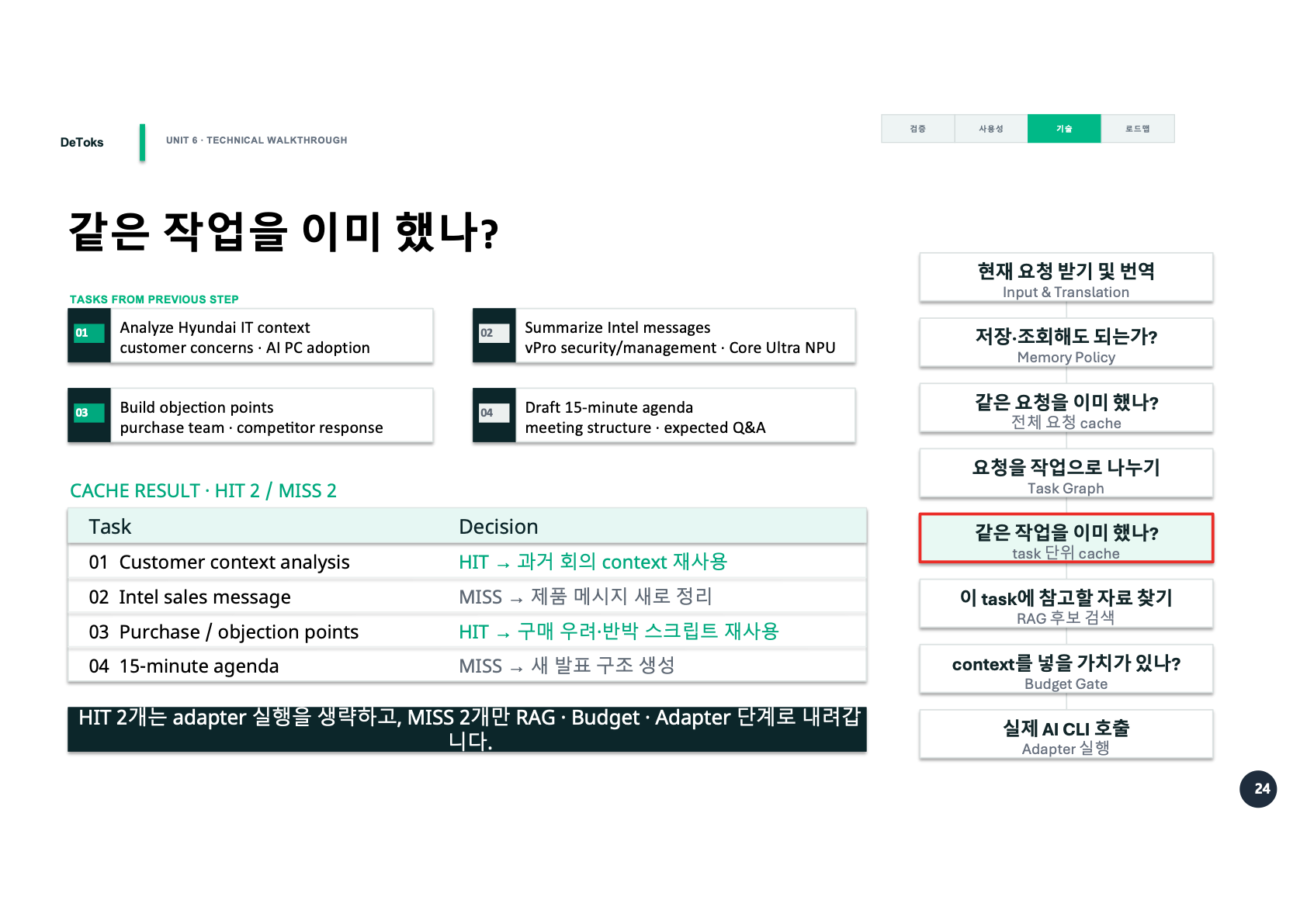
발표 예시에서는 task 4개 중 2개가 HIT, 2개가 MISS였다.
01 Customer context analysis
HIT -> 과거 회의 context 재사용
02 Intel sales message
MISS -> 제품 메시지 새로 정리
03 Purchase / objection points
HIT -> 구매 우려와 반박 스크립트 재사용
04 15-minute agenda
MISS -> 새 발표 구조 생성이 구조가 마음에 들었던 이유는 현실적인 사용 방식과 잘 맞았기 때문이다. 실제로 AI CLI를 쓰다 보면 전체 요청이 완전히 반복되는 경우는 생각보다 적다. 하지만 부분 반복은 자주 생긴다.
예를 들어 “고객사 배경 분석”은 한 번 해두면 여러 자료에서 다시 쓸 수 있다. “경쟁사 대비 포인트”도 비슷하다. 반면 발표 구조나 문서 형식은 매번 조금씩 달라질 수 있다.
F2 cache는 이런 반복을 줄이기 위한 장치다. HIT가 난 task는 adapter 실행을 생략한다. MISS가 난 task만 다음 단계로 내려간다.
HIT task
이전 결과 재사용
adapter 실행 생략
MISS task
RAG 후보 검색
Budget Gate 확인
adapter 실행이렇게 보면 cache가 왜 직접적인 절감 장치인지 분명해진다. cache는 context를 조금 줄이는 기능이 아니라, 실행 자체를 줄인다. 특히 task 단위 cache는 긴 요청 안에서 일부만 새로 처리할 수 있게 해준다.
RAG: 줄이는 기능이라기보다 필요한 기억을 찾는 기능
cache에서 MISS가 난 task는 RAG 검색으로 넘어간다.
여기서 중요한 건 RAG의 역할을 정확히 보는 것이다. RAG는 토큰을 직접 줄이는 기능이라고 말하기 어렵다. 오히려 잘못 쓰면 토큰이 늘어난다. 과거 자료를 context에 넣는 일이기 때문이다.
그렇다면 왜 RAG가 필요한가.
RAG는 프로젝트 메모리에 가깝다. 예전에 처리한 task, 출력, 회의 메모, 제품 설명 같은 자료 중에서 현재 task에 참고할 만한 것을 찾아준다. 사용자가 매번 “지난번에 정리한 Intel vPro 메시지도 참고해줘”라고 말하지 않아도, DeToks가 후보를 찾을 수 있게 하는 장치다.
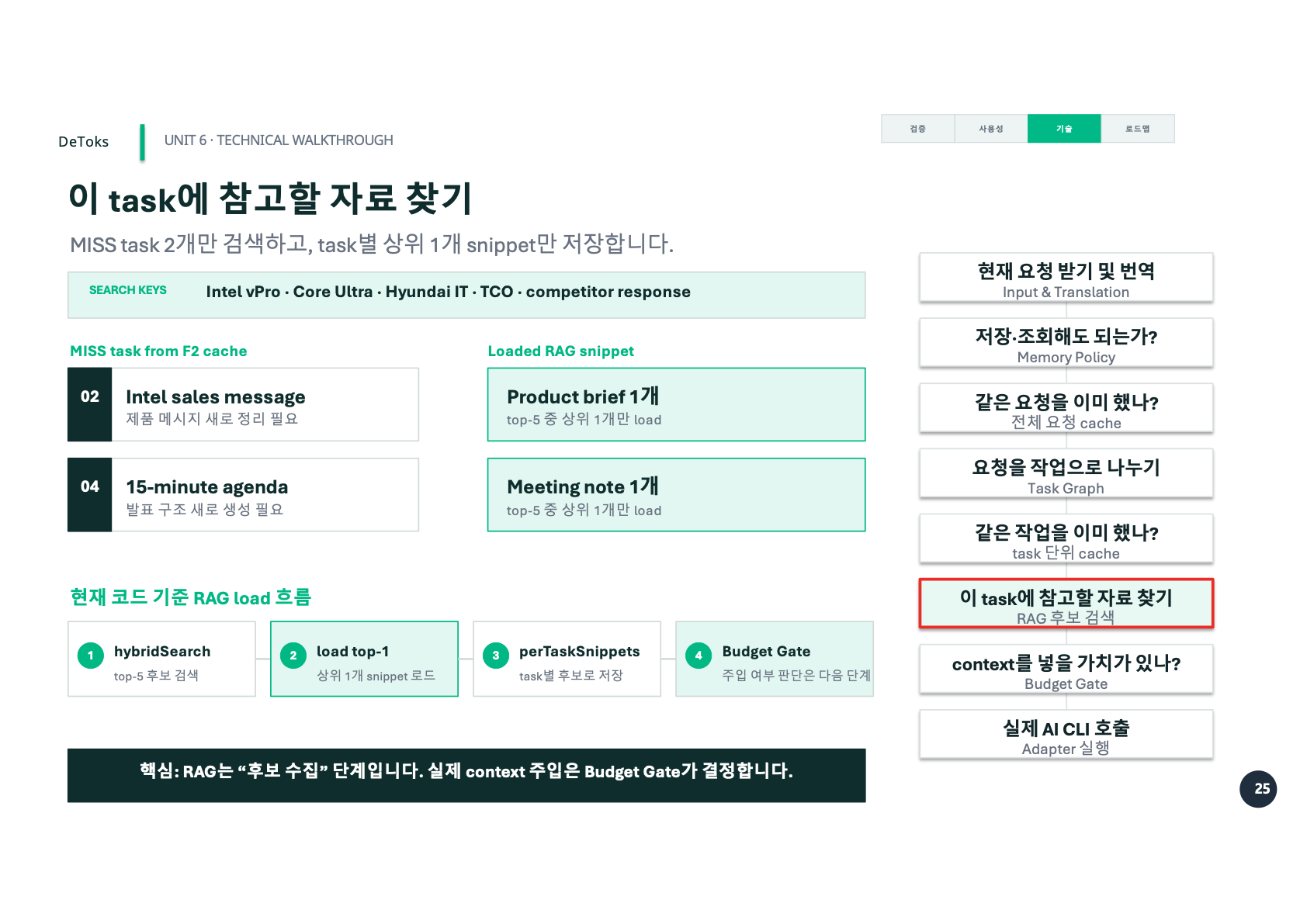
발표 예시에서는 MISS task 2개에 대해서만 검색했다.
02 Intel sales message
Product brief 1개 load
04 15-minute agenda
Meeting note 1개 load검색 키워드는 task에서 뽑았다.
Intel vPro
Core Ultra
Hyundai IT
TCO
competitor response현재 코드 기준으로는 RAG가 top-5 후보를 찾고, 그중 상위 1개 snippet만 로드하는 흐름이었다. task별로 후보를 모아두고, 실제로 context에 넣을지는 다음 단계에서 판단한다.
이 구분이 중요했다.
RAG
참고 자료 후보를 찾는다.
Budget Gate
그 자료를 실제 context에 넣을지 결정한다.RAG가 찾았다고 해서 무조건 넣으면 안 된다. 관련성이 낮은 자료가 들어가면 모델이 엉뚱한 방향으로 갈 수 있고, context도 불필요하게 늘어난다. 그래서 RAG는 “후보 수집” 단계로 두고, 실제 주입 여부는 Budget Gate에 넘기는 쪽이 더 맞았다.
Budget Gate: 실행을 막는 게 아니라 context를 고른다
다음은 Budget Gate다.
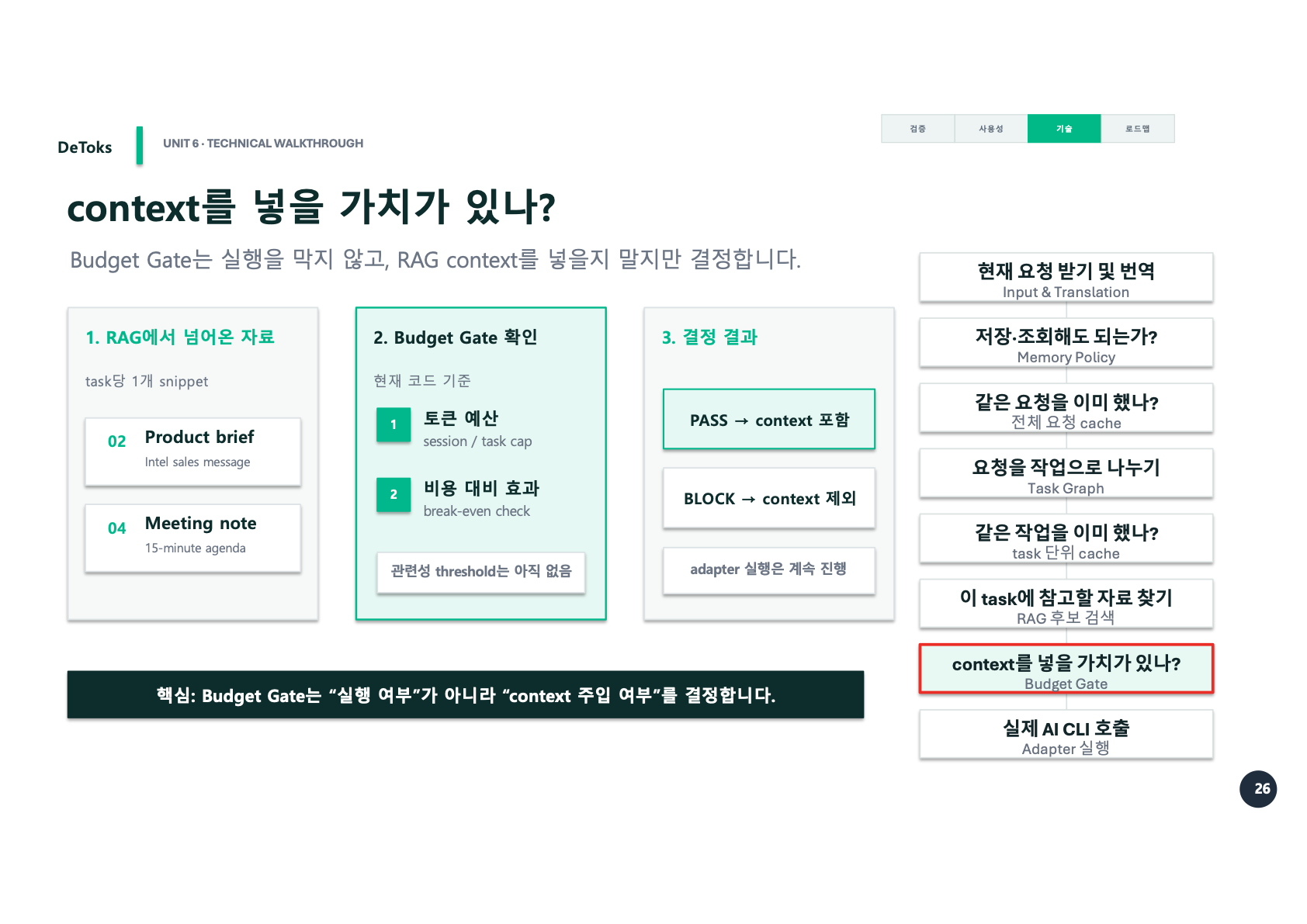
이름만 보면 Budget Gate가 실행을 막는 장치처럼 들릴 수 있다. 하지만 Phase 2 발표에서 우리가 강조한 건 반대였다.
Budget Gate는 실행 여부를 결정하지 않는다.
RAG context를 넣을지 말지를 결정한다.즉, Budget Gate에서 BLOCK이 나와도 adapter 실행은 계속된다. 다만 RAG에서 가져온 자료를 context에 넣지 않을 뿐이다.
예를 들어 Product brief는 현재 task와 관련성이 있고, 토큰 예산 안에서도 넣을 가치가 있다고 판단되면 PASS가 된다. 그러면 context에 포함된다. 반대로 Meeting note가 지금 task에 비해 비용 대비 효과가 낮다고 판단되면 BLOCK이 된다. 이 경우 task 자체는 실행하지만, 해당 snippet은 빼고 실행한다.
이 구조는 발표에서 꼭 정확히 말하고 싶었다. Budget Gate를 “작업 실행을 멈추는 단계”로 설명하면 실제 흐름과 다르다. 우리가 만들고 싶었던 건 실패시키는 게 아니라, context를 덜 넣는 판단이었다.
PASS
RAG context 포함
BLOCK
RAG context 제외
adapter 실행은 계속 진행여기서도 Phase 2의 방향이 보인다. 무조건 많이 넣는 게 좋은 게 아니다. AI에게 더 많은 정보를 주면 더 좋은 답을 할 것처럼 느껴지지만, 실제로는 그렇지 않을 때가 많다. 관련 없는 자료는 방해가 된다. 너무 긴 context는 비용도 늘리고, 답변의 초점도 흐린다.
Budget Gate는 그 사이에서 “이 자료를 넣을 만큼 가치가 있는가”를 묻는 단계였다.
Phase 1과 Phase 2의 차이
이 흐름을 정리하면 Phase 1과 Phase 2의 차이가 보인다.
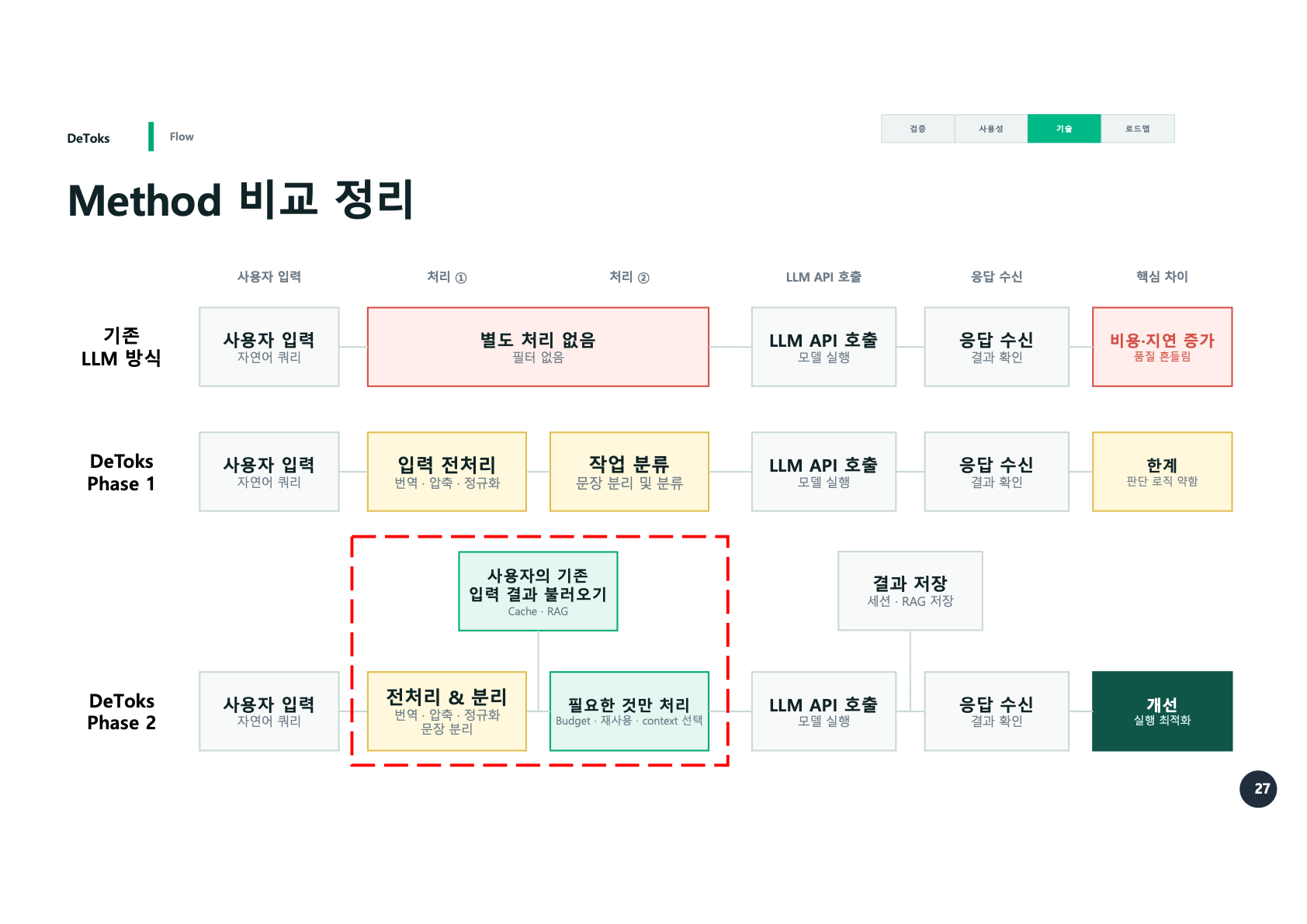
Phase 1은 입력 전처리와 작업 분류가 중심이었다.
사용자 입력
-> 번역, 압축, 정규화
-> 작업 분류
-> LLM API 호출
-> 응답 수신Phase 2는 여기에 재사용과 context 선택이 들어갔다.
사용자 입력
-> 전처리와 분리
-> 필요한 것만 처리
-> Budget, 재사용, context 선택
-> LLM API 호출
-> 결과 저장말하자면 Phase 1은 입력을 정리하는 단계였고, Phase 2는 실행을 최적화하는 단계였다.
이 차이는 작지 않았다. 입력을 줄이는 건 한 번의 요청 안에서 효과가 난다. 실행을 줄이는 건 여러 번의 요청이 이어질수록 효과가 커진다. 특히 AI CLI는 한 번 쓰고 끝나는 도구가 아니다. 같은 프로젝트 안에서 계속 대화하고, 계속 수정하고, 계속 검증한다.
그런 흐름에서는 이전 결과를 잘 저장하고, 다시 쓸 수 있는 건 다시 쓰고, 필요한 자료만 context에 넣는 구조가 더 중요해진다.
사용자 입장에서 좋은 점
이 파트를 준비하면서 계속 생각한 건 사용자 입장에서의 이점이었다. 내부 구조만 보면 기능 이름이 많아진다. Memory Policy, F1 cache, F2 cache, Task Graph, RAG, Budget Gate, Adapter. 이렇게 나열하면 오히려 복잡해 보인다.
하지만 사용자가 얻는 건 단순해야 했다.
같은 일을 덜 시킨다.
이미 한 일은 다시 하지 않는다.
필요한 기억만 꺼낸다.
불필요한 context는 넣지 않는다.
그래도 필요한 작업은 계속 실행한다.이게 Phase 2 기술 흐름의 사용자 가치였다.
사용자는 매번 “이전 결과 중 이 부분만 참고해줘”라고 자세히 말하지 않아도 된다. DeToks가 세션과 task 결과를 기준으로 다시 쓸 수 있는 부분을 찾는다. cache가 맞으면 실행을 건너뛰고, RAG가 도움이 되면 참고 자료를 찾고, Budget Gate가 비용 대비 가치가 낮다고 보면 context를 빼준다.
물론 이 구조가 완벽하다는 뜻은 아니다. RAG 검색 품질은 계속 검증해야 한다. cache도 의미는 같지만 표현이 다른 요청까지 잡으려면 더 고도화가 필요하다. Budget Gate도 더 정교한 관련성 판단이 붙어야 한다.
하지만 Phase 2에서 중요한 건 방향이었다.
프롬프트를 줄이는 도구
에서
반복 작업을 덜 실행하게 만드는 도구이 방향으로 DeToks를 다시 설명할 수 있게 됐다.
발표자료를 만들면서 조심했던 점
이 기술 파트를 발표자료로 만들 때 가장 조심했던 건 과장하지 않는 것이었다.
RAG를 넣으면 토큰이 줄어든다고 말하면 틀릴 수 있다. RAG는 오히려 context를 추가한다. 잘 쓰면 답변 품질을 높이고, 사용자가 다시 설명해야 하는 부담을 줄일 수 있지만, 직접적인 토큰 절감 장치는 아니다.
Budget Gate도 실행을 막는 기능처럼 말하면 안 된다. 실제로는 RAG context 주입 여부를 결정하는 단계다. BLOCK이 나와도 adapter 실행은 계속된다.
Task Graph도 “분류만으로 토큰이 줄었다”고 말하면 애매하다. Task Graph는 cache와 RAG를 task 단위로 적용하기 위한 구조에 더 가깝다.
그래서 발표에서는 각 기능의 역할을 나눠서 말하려고 했다.
Compression
현재 입력을 줄인다.
Cache
같은 요청이나 task 실행을 건너뛴다.
RAG
과거 자료와 프로젝트 메모리를 찾는다.
Budget Gate
찾은 자료를 context에 넣을지 판단한다.
Task Graph
이 판단을 task 단위로 가능하게 만든다.이 구분이 있어야 DeToks가 더 설득력 있게 보였다. 무엇이 직접 절감이고, 무엇이 품질 보조이고, 무엇이 실행 흐름을 위한 기반인지 나눠야 했다.
Phase 2 기술 본론
5월 12일쯤의 작업은 발표자료를 만들면서 구조를 다시 확인하는 시간이기도 했다. 기능 이름을 붙이는 건 어렵지 않다. 어려운 건 그 기능들이 실제로 어떤 순서로 이어지고, 사용자의 요청 하나가 어디에서 멈추고 어디에서 다시 실행되는지 설명하는 일이었다.
정리하고 나니 Phase 2의 기술 본론은 이 문장으로 남았다.
DeToks는 모든 요청을 더 짧게 만드는 것보다,
다시 하지 않아도 되는 작업을 찾아내는 쪽으로 진화했다.Phase 1에서 만든 번역, 압축, Task Graph는 여전히 중요했다. 다만 그 역할이 조금 바뀌었다. 입력을 줄이는 것에서 끝나는 게 아니라, cache와 RAG와 Budget Gate가 작동할 수 있는 기반이 됐다.
이제 남은 과제는 이 구조를 발표장에서 이해하기 쉽게 보여주는 일이었다. 기술적으로는 꽤 많은 단계가 있지만, 발표에서는 결국 하나의 흐름으로 보여야 했다.
사용자의 요청이 들어오고, DeToks가 기억 사용 여부를 확인하고, 같은 요청을 찾고, task로 나누고, 이미 한 task는 재사용하고, 필요한 자료만 찾아보고, context에 넣을 가치가 있는지 판단하고, 마지막으로 필요한 작업만 실행한다.
이 흐름이 보이면 DeToks가 왜 “작업 흐름 컨트롤러”인지도 조금 더 자연스럽게 설명할 수 있었다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.