5월 19일, DeToks Phase 2 최종 발표를 진행했다. 장소는 인텔 코리아였다.
이곳은 과정 초반에 한 번 방문했던 곳이기도 했다. 그때는 현직자 특강을 들으러 간 입장이었다. 인텔의 AI 기술, OpenVINO, AI 솔루션 이야기를 들으면서 아직 내가 모르는 게 정말 많다고 느꼈던 날이었다.
그런데 이번에는 조금 달랐다. 같은 공간에 다시 갔지만, 이번에는 우리가 만든 DeToks를 발표하러 갔다. 짧은 기간이었지만, 그 사이에 프로젝트 하나를 기획하고, 만들고, 검증하고, 방향을 바꾸고, 다시 발표자료로 정리했다.

사진 속 슬라이드는 Phase 1 회고 부분이다. 기존 LLM 방식과 DeToks Phase 1을 비교하면서, 어디까지가 효과가 있었고 어디서 한계가 있었는지 설명하던 장면이었다.
발표를 하면서 가장 신경 쓴 건 “우리가 많이 만들었다”를 보여주는 게 아니었다. Phase 2에서는 오히려 무엇을 덜어냈고, 어떤 표현을 조심해야 했고, DeToks를 어떤 방향으로 다시 잡았는지를 보여주는 게 더 중요했다.
Phase 2 발표의 중심
Phase 2 발표의 중심은 이 문장이었다.
Phase 1은 토큰 절감 가능성을 확인한 시간이었다.
Phase 2는 반복 가능한 작업 흐름을 만들기 위한 시간이었다.Phase 1에서 우리는 번역과 압축으로 입력 토큰을 줄일 수 있다는 걸 확인했다. 한국어를 영어로 바꾸면 토큰이 줄었고, 정제와 압축도 효과가 있었다. 전체 문맥 대신 요약 JSON을 저장하면 출력이 길수록 context 절감 폭이 커진다는 것도 확인했다.
하지만 동시에 한계도 보였다. 작업 분류 자체가 별도의 토큰 절감을 만든다고 말하기는 어려웠다. LLM은 이미 사용자의 의도를 꽤 잘 파악한다. 단순히 우리가 analyze, modify, validate 같은 type을 붙였다고 해서 바로 비용이 줄었다고 말하면 과장이 될 수 있었다.
그래서 Phase 2에서는 방향을 바꿨다.
입력을 줄이는 것
에서
다시 하지 않아도 되는 작업을 줄이는 것이 변화가 발표의 핵심이었다.
DeToks가 필요한 사람
발표 후반부에서는 DeToks가 어떤 사람에게 유용한지 정리했다.

슬라이드에는 다섯 가지 대상을 넣었다.
AI CLI를 자주 쓰는 개발자
반복 작업이 많은 팀
세션 관리가 필요한 프로젝트
토큰 비용을 관리할 조직
CLI는 낯설지만 AI 자동화에 관심 있는 IT 실무자이 목록을 만들면서 생각한 건, DeToks가 모든 사람을 위한 도구는 아니라는 점이었다. 한 번 질문하고 답을 받는 정도라면 굳이 DeToks가 필요하지 않을 수 있다. 짧은 대화에서는 cache도, RAG도, Budget Gate도 크게 빛나지 않는다.
DeToks가 더 잘 맞는 상황은 반복이 있는 작업이다.
같은 프로젝트 안에서 여러 번 AI CLI를 쓰고, 이전 결과를 다시 참고하고, 작업을 나눠서 처리하고, 이미 한 일을 다시 시키기 싫은 상황. 이런 흐름에서 DeToks의 의미가 생긴다.
사용자에게 주고 싶은 가치는 결국 이거였다.
AI CLI를 더 쉽게,
더 오래,
더 반복 가능하게 쓴다.이 문장은 발표자료에도 넣었다. DeToks가 단순히 “토큰을 조금 줄여주는 도구”로 보이지 않았으면 했다. AI CLI를 오래 쓰다 보면 생기는 반복과 맥락 관리의 피로를 줄이는 도구로 설명하고 싶었다.
남은 문제를 숨기지 않기
발표 후반에는 Known Issue도 넣었다.
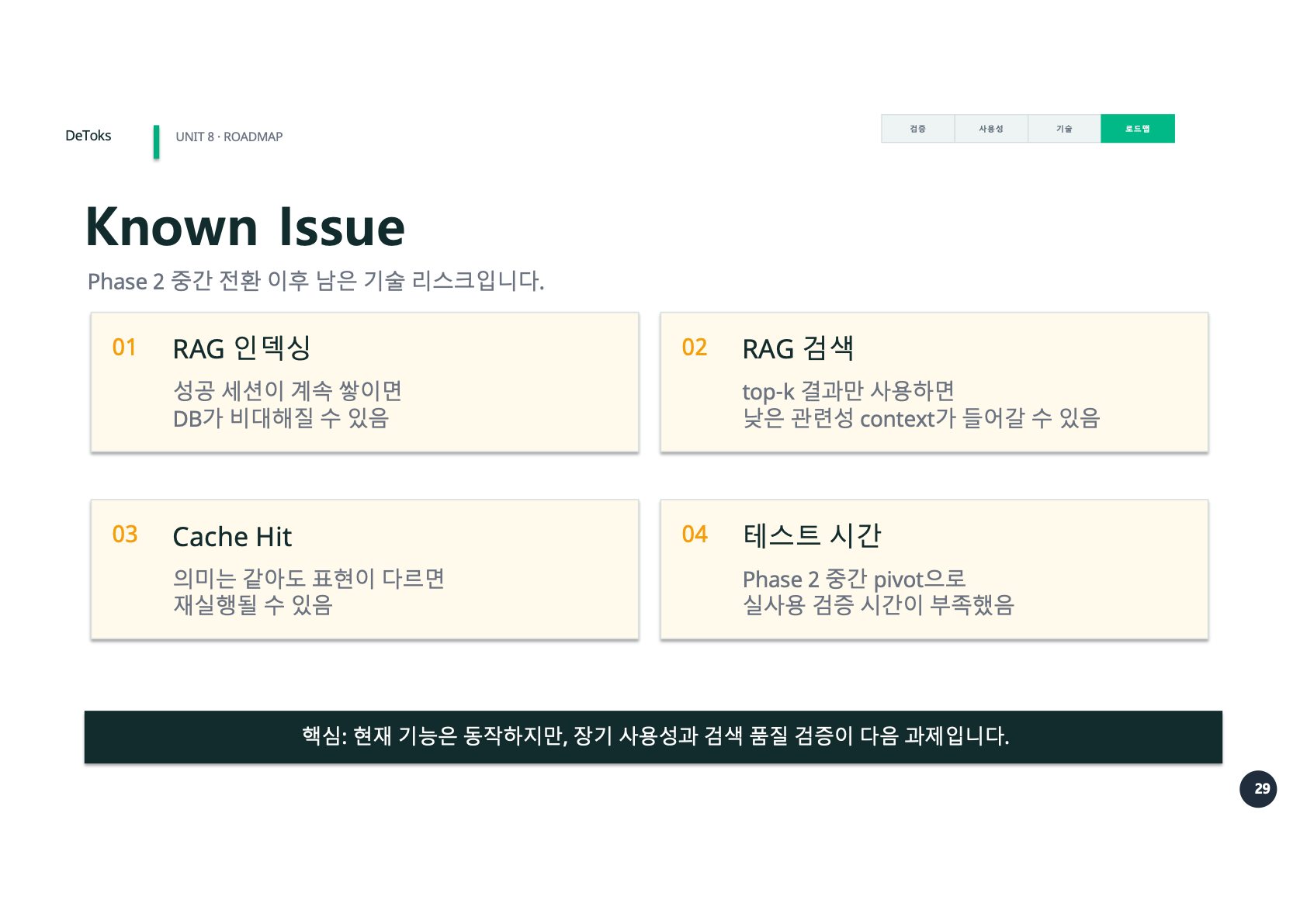
이 부분은 일부러 뺐어도 됐다. 최종 발표에서는 보통 잘 된 것만 보여주고 싶은 마음이 생긴다. 하지만 Phase 2에서 남은 리스크를 숨기면, 프로젝트가 오히려 덜 설득력 있어 보일 것 같았다.
우리가 정리한 Known Issue는 네 가지였다.
RAG 인덱싱
성공 세션이 계속 쌓이면 DB가 비대해질 수 있음
RAG 검색
top-k 결과만 사용하면 낮은 관련성 context가 들어갈 수 있음
Cache Hit
의미는 같아도 표현이 다르면 재실행될 수 있음
테스트 시간
Phase 2 중간 pivot으로 실사용 검증 시간이 부족했음이 문제들은 모두 Phase 2의 방향과 연결되어 있었다.
RAG는 프로젝트 메모리로 유용하지만, 계속 저장만 하면 DB가 커진다. 저장량 관리가 필요하다. 검색도 마찬가지다. top-k 결과만 가져오면 관련성이 낮은 context가 들어갈 수 있다. 단순히 “가장 가까운 후보”를 가져오는 것만으로는 부족하고, 어느 정도 이하의 관련성은 빼는 기준이 필요하다.
Cache도 아직 완벽하지 않았다. 같은 의미라도 표현이 다르면 hash가 달라질 수 있고, 그러면 재실행된다. Phase 2에서 cache는 직접적인 절감 장치였지만, 의미 기반 재사용까지 가려면 더 많은 작업이 필요했다.
마지막은 테스트 시간이었다. Phase 2 중간에 방향을 꽤 크게 바꿨기 때문에, 실제 사용 검증은 충분하지 않았다. 기능이 동작하는 것과 오래 써도 괜찮은 것은 다르다. 이 차이를 남은 과제로 인정해야 했다.
개선 방향
Known Issue는 바로 Roadmap으로 이어졌다.

문제를 문제로만 남겨두지 않고, 개선 방향으로 바꿔 적었다.
RAG DB 관리
TTL 만료 삭제
Semantic deduplication
검색 품질 개선
Distance threshold
낮은 관련성 사전 필터링
Cache 고도화
Semantic cache lookup
표현이 달라도 유사 작업 매칭
지속 테스트
Known Issue 수정 후 실사용 테스트로 품질 개선여기서 가장 중요한 건 저장량과 검색 품질이었다. Memory가 많아질수록 좋아지는 것처럼 보이지만, 실제로는 그렇지 않을 수 있다. 오래된 세션이 계속 쌓이면 검색 대상이 커지고, 비슷한 자료가 중복으로 남고, 관련 없는 context가 들어갈 가능성도 생긴다.
그래서 단순히 “더 많이 저장한다”가 아니라, 잘 지우고 잘 합치는 방향이 필요했다.
저장량을 줄인다.
검색 정확도를 높인다.
재사용 판단을 의미 기반으로 바꾼다.이 세 가지가 Phase 2 이후의 개선 방향이었다.
Phase 2에서 DeToks는 작업 흐름 컨트롤러로 방향을 바꿨다. 하지만 컨트롤러가 되려면 판단 기준이 더 정교해야 한다. 어떤 기억을 남길지, 어떤 기억을 버릴지, 어떤 context를 넣을지, 어떤 작업을 재사용할지 더 잘 판단해야 한다.
수익화 이야기를 넣은 이유
발표 후반에는 수익화 전략도 간단히 넣었다.


개인 사용자는 오픈소스로 열고, 조직 단위에서는 Business Fee를 받을 수 있다는 방향이었다. 여기에 Buy Me a Coffee도 넣었다.
솔직히 이 파트는 기술적으로 깊은 내용은 아니었다. 하지만 프로젝트를 발표할 때는 “이걸 어떻게 쓰게 만들 것인가”도 어느 정도는 필요했다. 아무리 기능이 좋아도 사용자가 어디서 시작해야 하는지, 어떤 방식으로 확장할 수 있는지 보여줘야 한다.
DeToks의 개인 사용자는 AI CLI를 자주 쓰는 개발자일 가능성이 높다. 이들에게는 오픈소스로 접근성을 열어두는 게 맞다고 봤다. 반대로 조직에서는 반복 작업, 비용 관리, 팀 단위 세션 관리가 더 중요해질 수 있다. 이쪽은 Business 방향으로 확장할 수 있다.
아직 구체적인 사업 모델이라고 말하기에는 이르다. 그래도 발표에서는 DeToks가 단순 실습 결과물이 아니라, 실제 사용 흐름과 확장 방향을 생각한 도구라는 점을 보여주고 싶었다.
Try DeToks
마지막 슬라이드는 간단하게 끝냈다.
$ npm install -g @sorlros/detoks
$ detoks이 두 줄을 넣은 이유는 분명했다. Phase 2에서 설치와 실행 흐름을 줄였다는 이야기를 했기 때문에, 마지막도 실행 명령으로 끝나는 게 자연스러웠다.
Phase 1이었다면 마지막 문장은 “토큰을 줄였다”에 가까웠을 것이다. Phase 2에서는 조금 달랐다. 이제 DeToks는 줄인 토큰 수만 말하는 도구가 아니었다. 사용자가 AI CLI를 반복해서 쓸 때, 어떤 작업을 다시 하지 않아도 되는지 판단하고, 필요한 기억만 찾고, context를 조절하는 도구로 설명됐다.
그래서 마지막 명령어는 단순한 설치 안내라기보다, Phase 2의 목표를 보여주는 장면에 가까웠다.
이제 한 번 실행해볼 수 있는 도구로 만들자.발표하면서 느낀 것
발표를 하면서 가장 기억에 남은 건, Phase 1 때와 마음가짐이 달랐다는 점이다.
Phase 1 발표 때는 우리가 만든 기능을 설명하는 데 집중했다. Prompt Compiler, Task Graph, Context Manager, CLI Wrapper를 각각 보여주고, 토큰 절감률과 기능 유지 결과를 말하면 됐다.
Phase 2 발표는 더 어려웠다. 기능을 설명하는 것보다 판단을 설명해야 했다.
왜 Python worker를 걷어냈나
왜 node-llama-cpp로 묶었나
왜 RAG를 직접 절감 기능이라고 말하지 않았나
왜 Budget Gate를 실행 차단이 아니라 context 선택으로 설명했나
왜 Known Issue를 발표에 넣었나이런 질문에 답해야 했다.
결국 발표는 결과물 자랑이 아니라 의사결정의 기록이었다. 어떤 가설이 맞았고, 어떤 표현은 과했고, 어떤 구조는 유지하고, 어떤 구조는 덜어냈는지 설명하는 자리였다.
그 점에서 Phase 2 발표는 좋은 마무리였다. 완벽한 제품을 만들었다고 말할 수는 없지만, 프로젝트가 어떤 방향으로 가야 하는지는 꽤 분명해졌다.
질문을 예상하며 정리한 것
발표자료를 만들 때는 실제 발표에서 받을 수 있는 질문도 생각했다. DeToks의 구조는 한 번에 이해하기 쉬운 편은 아니었다. 특히 Cache, RAG, Budget Gate가 한 흐름 안에 들어가면, 듣는 사람은 자연스럽게 이런 질문을 할 수 있다.
RAG가 있으면 정말 토큰이 줄어드나?
Cache는 어떤 기준으로 재사용하나?
Budget Gate가 막으면 실행이 안 되는 건가?
작업 분류는 왜 필요한가?
설치 흐름을 줄인 게 실제 사용자에게 얼마나 중요한가?이 질문들에 답하려면 기능을 과장하면 안 됐다. RAG는 직접 절감 기능이 아니라 프로젝트 메모리라고 말해야 했다. Budget Gate는 실행 차단이 아니라 context 주입 판단이라고 말해야 했다. Cache는 같은 요청과 같은 task를 재사용할 때 직접적인 절감이 생긴다고 설명해야 했다.
이런 구분을 해두니 발표가 더 편해졌다. 완벽한 기능처럼 보이게 포장하는 것보다, 각 기능이 어디까지 책임지는지 나눠 말하는 게 더 설득력 있었다.
발표장에서 모든 질문을 받은 건 아니지만, 준비 과정에서 이 질문들을 생각한 것만으로도 자료가 많이 정리됐다. 어떤 문장은 빠졌고, 어떤 문장은 더 쉬워졌다. Known Issue를 넣은 것도 같은 이유였다. 남은 문제를 인정해야 다음 방향도 자연스럽게 말할 수 있었다.
팀 발표로서의 마무리
이번 발표는 혼자 만든 결과물이 아니었다. 각자 맡은 파트가 있었고, 그 파트들이 모여 DeToks라는 하나의 흐름이 됐다.
시호님이 맡은 번역과 압축 흐름은 Phase 1의 출발점이었고, Phase 2에서도 입력 안정화의 기반으로 남았다. 내가 맡았던 Task Graph는 Phase 2에서 cache와 RAG를 task 단위로 적용하기 위한 기준점이 됐다. 지호님의 세션과 context 쪽 작업은 RAG와 memory 설명의 중심이 됐다. 규철님의 CLI와 adapter 흐름은 실제 사용자가 DeToks를 만나는 표면이었다.
발표에서는 이 모든 파트를 따로따로 보여주는 대신, 하나의 사용자 요청이 어떻게 흘러가는지로 묶었다. 그게 팀 프로젝트의 마지막 정리 방식으로 가장 맞았다.
입력은 정리되고
작업은 나뉘고
기억은 확인되고
필요한 context만 들어가고
실행 결과는 다시 저장된다이 흐름 안에 각자의 작업이 들어가 있었다.
다시 인텔 코리아에서
처음 인텔 코리아를 방문했을 때는 배우는 입장이었다. 현직자들의 이야기를 들으면서, 언젠가 저런 내용을 더 잘 이해하고 싶다고 생각했다.
그리고 몇 달 뒤, 같은 공간에서 우리가 만든 DeToks를 발표했다.
물론 이 발표 하나로 많은 것이 바뀌었다고 말할 수는 없다. 아직 부족한 점도 많고, DeToks도 더 다듬어야 한다. 그래도 개인적으로는 꽤 의미 있는 순간이었다. 처음에는 듣기만 했던 공간에서, 이번에는 우리가 만든 흐름을 설명하고 있었다.
Phase 2 발표를 마치고 나니 DeToks가 어떤 프로젝트였는지 조금 더 선명해졌다.
Phase 1
토큰 절감 가능성을 확인했다.
Phase 2
반복 가능한 작업 흐름을 만들기 시작했다.이 두 문장으로 정리할 수 있을 것 같다.
Phase 2의 마무리
Phase 2는 기능 추가 기간으로 시작했지만, 실제로는 방향 전환의 기간이었다.
처음에는 Claude adapter, Web Metrics, Dashboard 같은 확장을 생각했다. 하지만 검증을 다시 하면서 더 중요한 문제가 보였다. 입력을 줄이는 것만으로는 부족했고, 반복 작업을 다시 하지 않게 만드는 구조가 필요했다.
그래서 실행 준비를 줄였다. Python worker와 llama-server 부담을 걷어내고, Node 기반 런타임으로 묶었다. Cache를 통해 같은 요청과 같은 task를 재사용하는 흐름을 만들었다. RAG는 프로젝트 메모리로 보고, Budget Gate는 context 주입 판단으로 정리했다. 그리고 남은 리스크를 Known Issue와 Roadmap으로 남겼다.
이게 Phase 2의 결과였다.
완성이라기보다는 다음 단계로 넘어가기 위한 정리였다. DeToks는 이제 단순히 프롬프트를 줄이는 도구가 아니라, AI CLI 앞에서 작업 흐름을 정리하는 도구가 되어가고 있었다.
마지막으로 남기고 싶은 문장은 Phase 1 때와 같다.
Less Token, More Control.하지만 Phase 2를 지나고 나니 이 문장의 의미가 조금 더 달라졌다. 적은 토큰은 단순히 짧은 프롬프트에서만 나오지 않는다. 같은 일을 다시 하지 않고, 필요한 기억만 찾고, 넣을 가치가 있는 context만 넣는 흐름에서도 나온다.
그리고 더 많은 control은 모델을 억지로 조종하는 게 아니다. 모델을 부르기 전과 후의 작업 흐름을 사람이 납득할 수 있게 만드는 것이다.
5월 19일의 발표는 그 방향을 확인한 자리였다.
Community
Comments
Comments appear immediately. Use report if something needs review.
No comments yet.